Spark学习四:网站日志分析案例
Spark学习四:网站日志分析案例
标签(空格分隔): Spark
- Spark学习四网站日志分析案例
- 一创建maven工程
- 二创建模板
- 三日志分析案例
一,创建maven工程
1,执行maven命令创建工程
mvn archetype:generate -DarchetypeGroupId=org.scala-tools.archetypes -DarchetypeArtifactId=scala-archetype-simple -DremoteRepositories=http://scala-tools.org/repo-releases -DgroupId=com.ibeifeng.bigdata.spark.app -DartifactId=analyzer-logs -Dversion=1.0
2,idea导入maven工程

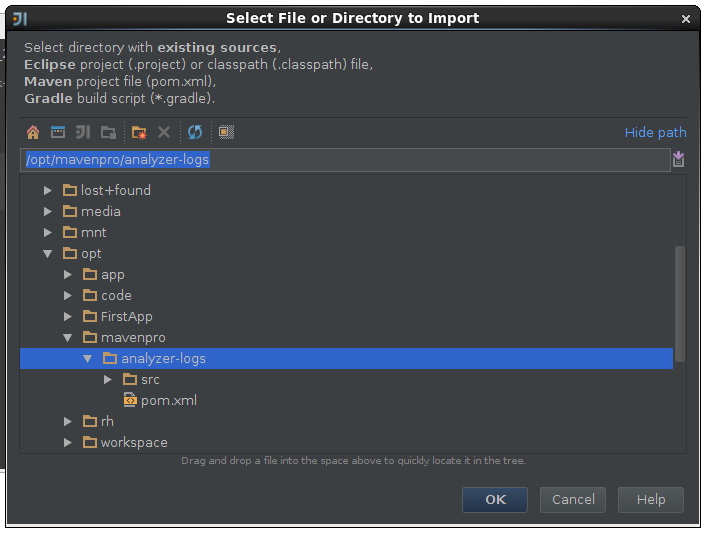
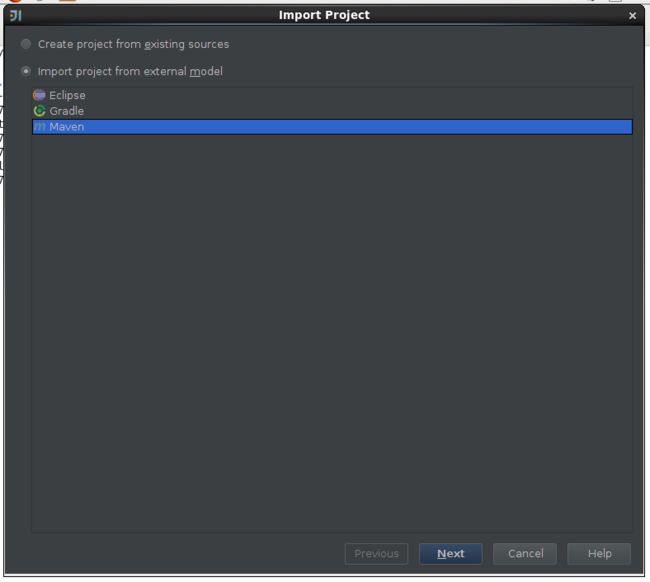
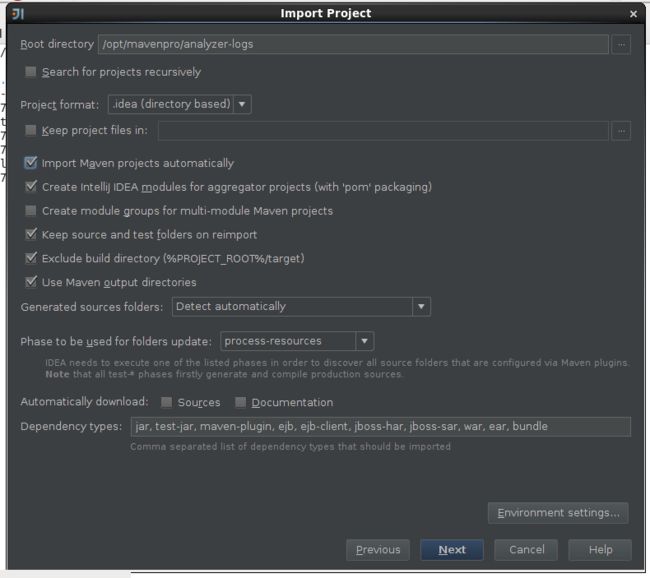
二,创建模板
#if ((${PACKAGE_NAME} && ${PACKAGE_NAME} != ""))package ${PACKAGE_NAME} #end
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
#parse("File Header.java")
object ${NAME} {
def main(args:Array[String]){
// create SparkConf
val sparkConf=new SparkConf().setAppName("Test").setMaster("local[2]")
//create sc
val sc=new SparkContext(sparkConf)
sc.stop()
}
}三,日志分析案例
1,准备数据
2,完成代码
ApacheAccessLog.scala
package com.ibeifeng.bigdata.spark.app
/** * Created by hadoop001 on 4/27/16. */
case class ApacheAccessLog( ipAddress: String , clientIdentd: String , userId: String , dataTime: String , method: String , endPoint: String , protocol: String , responseCode: Int , contentSize: Long ) {
}
object ApacheAccessLog{
// regex
// 64.242.88.10 - - [ 07/Mar/2004:16:05:49 -0800 ]
// "GET /twiki/bin/edit/Main/Double_bounce_sender?topicparent=Main.ConfigurationVariables HTTP/1.1"
// 401 12846
val PARTTERN = """^(\S+) (\S+) (\S+) \[([\w:/]+\s[+|-]\d{4})\] "(\S+) (\S+) (\S+)" (\d{3}) (\d+)""".r
def isValidatelogLine(log:String):Boolean={
val res=PARTTERN.findFirstMatchIn(log)
if(res.isEmpty){
false
}else{
true
}
}
def parseLogLine(log:String):ApacheAccessLog={
val res=PARTTERN.findFirstMatchIn(log)
if(res.isEmpty){
throw new RuntimeException("Cannot parse log line: " + log)
}
val m=res.get
ApacheAccessLog(
m.group(1) ,
m.group(2) ,
m.group(3) ,
m.group(4) ,
m.group(5) ,
m.group(6) ,
m.group(7) ,
m.group(8).toInt ,
m.group(9).toLong
)
}
}
OrderingUtils.scala
package com.ibeifeng.bigdata.spark.app
/** * Created by hadoop001 on 4/28/16. */
object OrderingUtils {
object SecondValueOrdering extends Ordering[(String, Int)]{
/** Returns an integer whose sign communicates how x compares to y. * * The result sign has the following meaning: * * - negative if x < y * - positive if x > y * - zero otherwise (if x == y) */
def compare(x: (String, Int), y: (String, Int)): Int ={
x._2.compare(y._2)
}
}
}
3,maven进行打包
mvn clean package
4,提交应用
//本地模式
bin/spark-submit --class com.ibeifeng.bigdata.spark.app.LogAnalyzer analyzer-logs-1.0.jar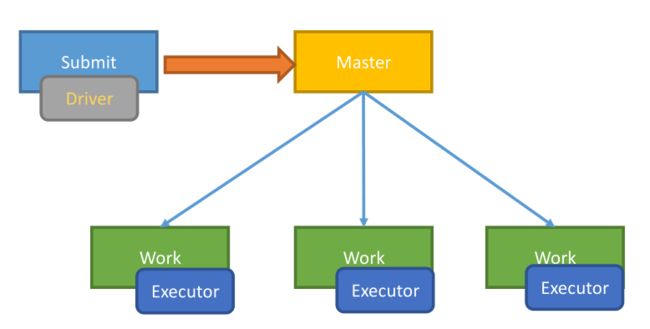
//集群模式 需要启动master和worknode
bin/spark-submit \
--class com.ibeifeng.bigdata.spark.app.LogAnalyzer \
--deploy-mode cluster \
analyzer-logs-1.0.jar \
spark://spark.com.cn:7077
四,spark launch on yarn
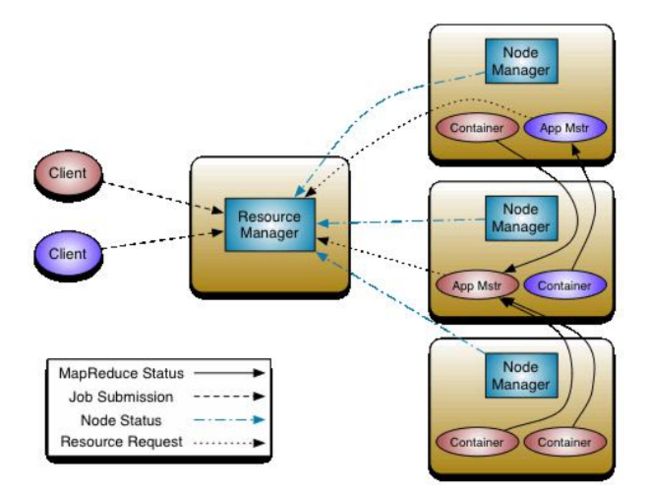
1) 编译Spark时,指定选择-Pyarn
2) 在提交应用时,指定HADOOP_CONF,读取配置信息
–master yarn
第一种运行模式:yarn-client
/opt/modules/spark-1.3.0-bin-2.5.0/bin/spark-submit \
--class com.ibeifeng.bigdata.spark.app.LogAnalyzer \
analyzer-logs-1.0.jar \
yarn-client第二种运行模式:yarn-cluster
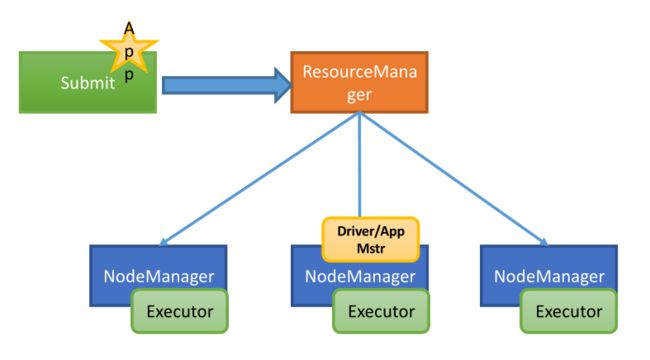

/opt/modules/spark-1.3.0-bin-2.5.0/bin/spark-submit \
--master yarn-cluster \
--class com.ibeifeng.bigdata.spark.app.LogAnalyzer \
analyzer-logs-1.0.jar