java中一些容器底层的数据结构解析
先来看一个java里一些主要容器的继承图:
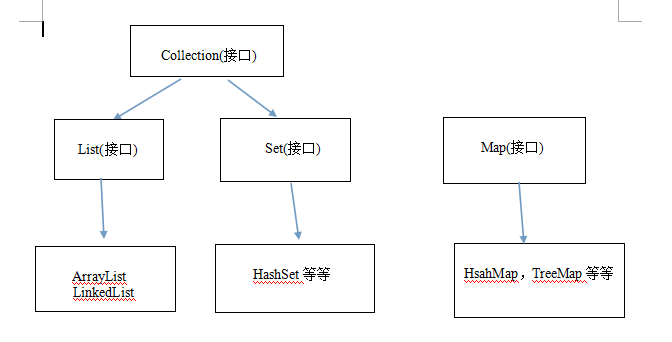
然后分别解析一下上面几种容器底层的数据结构以及一些实现:
1.ArrayList(非线程安全的)
底层的数据结构其实就是数组,但是它比数组优秀的地方在于他是动态的,即不必像数组那样固定大小,那么他是如何实现这种数据结构是数组,但是给我们看起来确实不固定大小的呢?
ArrayList 是通过将底层 Object 数组复制的方式(System.arraycopy方法)来处理数组的增长;
当ArrayList 的容量不足时,其扩充容量的方式:先将容量扩充至当前容量的1.5倍,若还不够,则将容量扩充至当前需要的数量。
所以由上面可以看出ArrayList用于查找的话就相当于数组十分快,但是如果是插入或者删除的话则十分慢。
2.LinkedList(非线程安全)
顾名思义底层的数据结构是链表,而且是双向链表,所以他也具有链表的特点,即插入或者删除的话很快,但是如果是查找的话则比较缓慢。
3.HashSet(非线程安全)
底层数据结构是散列表(关于散列表看下面),仅仅存储对象(而hashMap是存储键值对),突出特点是存的对象不可重复,保证这一点是通过先对比每个对象的hashCode,如果hashCode相同,再对比equal()来确定两个对象是否重复,所以放入hashset的对象一定要重写hashCode()和equal().
4.HsahMap(非线程安全)
底层也是散列表(见下面),通过键值对来存储数据,通过键来获取值,速度比hashset快,键和值可以null.
现在介绍一下散列表(哈希表)这种数据结构:
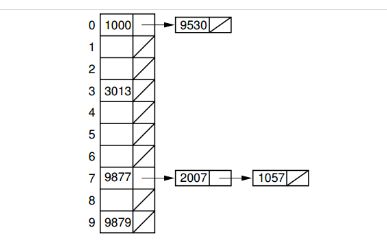
首先每个对象产生一个哈希值(因为哈希值太大,数组不可能开这么大,会造成巨大浪费),所以需要通过一个哈希函数对哈希值进行转化,如图1000就转化为0,,3013就放入3,这样访问对象就跟数组一样便捷,插入对象也十分便捷,如果是碰到哈希值转化后是同一值得,即产生冲突,则像上面这种解决冲突的方式就是 链表的方式,哈希值在数组里同一位置的都用链表链接起来。所以散列表实际上是查找快,插入删除也快,解决了数组和链表各自的一些缺点。