Spark 定制版:002~Spark Streaming(二)
本讲内容:
a. 解密Spark Streaming运行机制
b. 解密Spark Streaming架构
注:本讲内容基于Spark 1.6.1版本(在2016年5月来说是Spark最新版本)讲解。
上节回顾:
上节课谈到技术界的寻龙点穴,Spark就是大数据的龙脉,而Spark Streaming就是Spark的穴位。假如要构建一个强大的Spark应用程序 ,Spark Streaming 是一个值得借鉴的参考,Spark Streaming涉及多个job交叉配合,几乎可以包括spark的所有的核心组件,如果对Spark Streaming精通了的话,可以说就精通了整个Spark,因此精通并掌握Spark Streaming是至关重要的。
在Spark官网(这里写链接内容)中,可以看到如下图所示:

Spark Core上面有4个流行的框架:Spark SQL、Spark Streaming、机器学习、图计算。除了Spark Streaming,其他的子框架大多都是在Spark Core上对一些算法或者接口进行了高层的封装。例如Spark SQL 封装了SQL语法,主要功能就是将SQL语法解析成Spark Core的底层API。而机器学习则是封装了许多的数学向量及算法。GraphX目前也没有太大的更新。
而Spark Streaming更像是对Spark Core的衍生子框架,可想而知,他是相当复杂的一个应用程序。同时我们也不难发现,基于Spark Core的时候,都是基于RDD编程,Spark Streaming则是基于DStream编程。DStream是逻辑级别的,而RDD是物理级别的。DStream是随着时间的流动内部将集合封装RDD。对DStream的操作,归根结底还是对其RDD进行的操作。
我们查看上一节中Spark Streaming的运行日志,就可以看出和RDD的运行几乎是一致的:

SparkStreaming Job在运行的时候,首先会生成DStream的Graph,在特定的时间将DStream Graph转换成RDD Graph。然后再去运行RDD的job 。如下图:

从这个角度来讲,可以将Spark Streaming放在坐标系中。其中Y轴就是对RDD的操作,RDD的依赖关系构成了整个job的逻辑,而X轴就是时间。随着时间的流逝,固定的时间间隔(Batch Interval)就会生成一个job实例,进而在集群中运行。

由此为大家详细总结并揭秘 Spark Streaming五大核心特征
特征1:逻辑管理
DStream是对RDD封装的集合,作用于DStream的操作会对其中每个RDD进行作用,DStream Graph就是RDD Graph的模板,其逻辑管理完全继承RDD的DAG关系。
特征2:时间管理
Spark Streaming的最大特征是引入了时间属性,DStream在RDD的基础上增加了时间纬度,随着时间的纬度,不断把模板实例化,通过动态Job控制器运行作业。
特征3:流式输入和输出
以InputStream和OutputStream为核心,进行流式的数据输入输出。
特征4:高容错
具体Job运行在Spark Cluster之上,此时系统容错就至关重要。
主要思路:
a、限流
b、根据需要调整资源安排
特征5:事务处理
在处理出现崩溃的情况下确保Exactly once的事务语义。主要通过检查点等技术实现。(下一讲再细说)
结合Spark Streaming源码进一步解析:
StreamingContext方法中调用JobScheduler的start方法(StreamingContext.scala,610行代码)

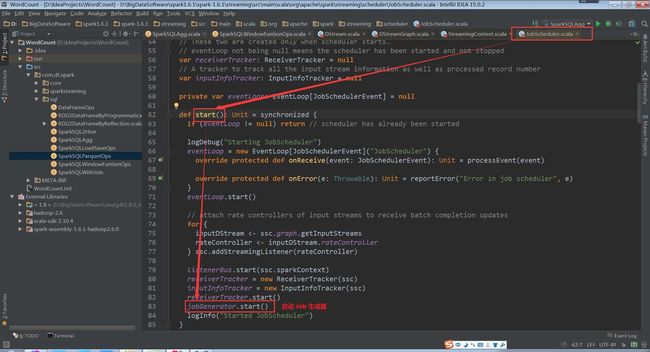
JobGenerator的start方法中,调用startFirstTime方法,来开启定时生成Job的定时器
(JobScheduler.scala,83行代码)
(JobGenerator.scala,98行代码)

startFirstTime方法,首先调用DStreamGraph的start方法,然后再调用RecurringTimer的start方法。
(JobGenerator.scala,193行代码)

(DStreamGraph.scala,39行代码)

(RecurringTimer.scala,59行代码)
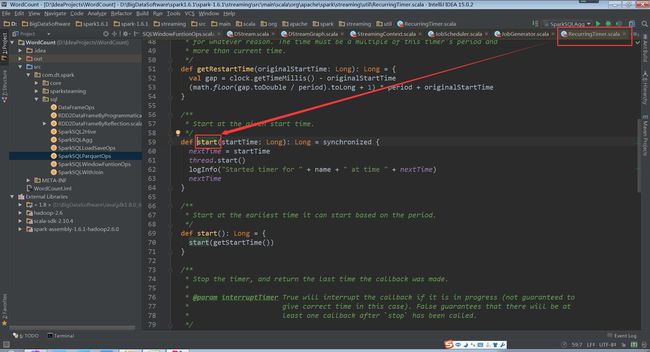
timer对象为一个定时器,根据batchInterval时间间隔定期向EventLoop发送GenerateJobs的消息。
(JobGenerator.scala,58~59行代码)

接收到GenerateJobs消息后,会回调generateJobs方法。
(JobGenerator.scala,181行代码)

generateJobs方法再调用DStreamGraph的generateJobs方法生成Job
(JobGenerator.scala,248行代码)
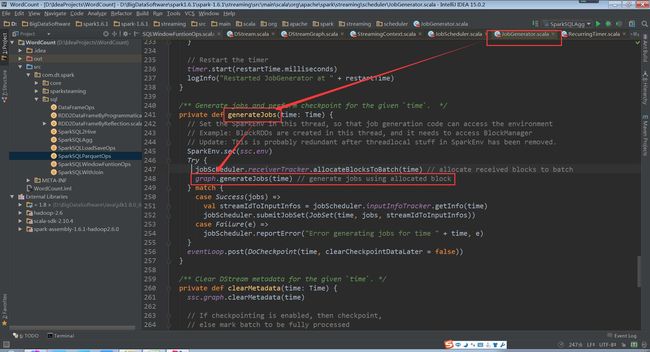
(DStreamGraph.scala,248行代码)

DStreamGraph的实例化是在StreamingContext中的
(StreamingContext.scala,162~164行代码)

在DStreamGraph的类中还保存了输入流和输出流的信息
(DStreamGraph.scala,29~30行代码)

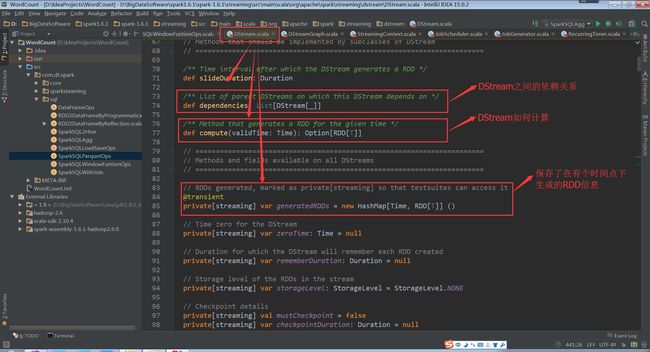
DStream类中依赖、计算、保存RDD信息
(DStream.scala,74、77、85行代码)
回到JobScheduler的start方法中receiverTracker.start()
(JobScheduler.scala,82行代码)
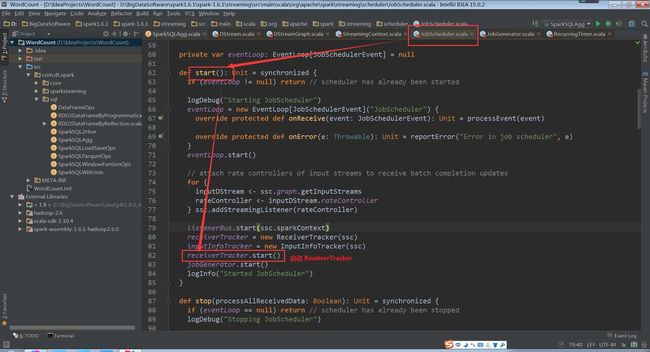
(ReceiverTracker.scala,149行代码)

其中ReceiverTrackerEndpoint对象为一个消息循环体
(ReceiverTracker.scala,449行代码)
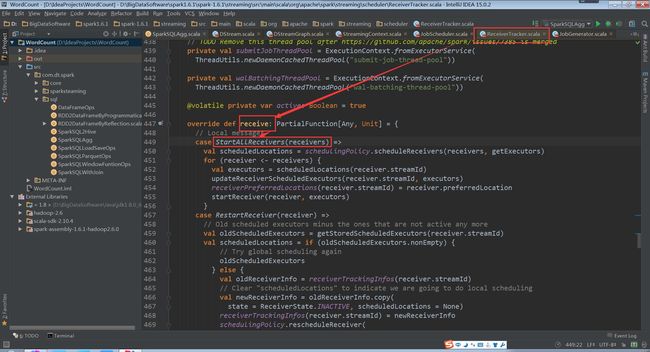
launchReceivers方法中发送StartAllReceivers消息
(ReceiverTracker.scala,413行代码)

接收到StartAllReceivers消息后,进行如下处理
(ReceiverTracker.scala,454行代码)

(ReceiverTracker.scala,594行代码)
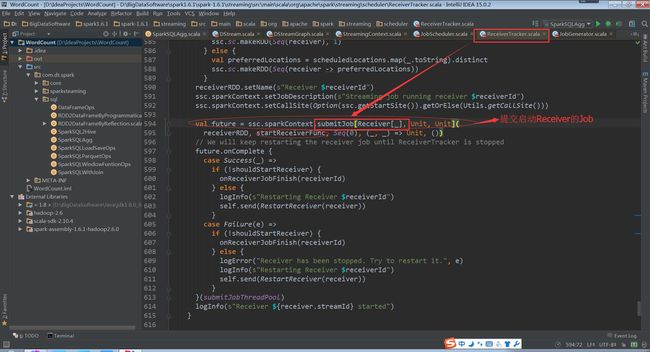
StartReceiverFunc方法如下,实例化Receiver监控者,开启并等待退出
(ReceiverTracker.scala,573行代码)
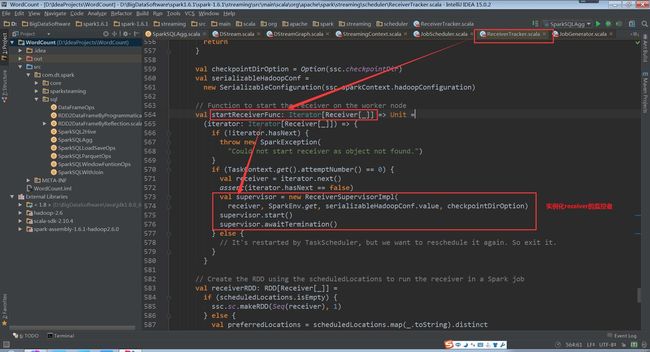
supervisor的start方法中调用startReceiver方法
(ReceiverSupervisor.scala,130行代码)
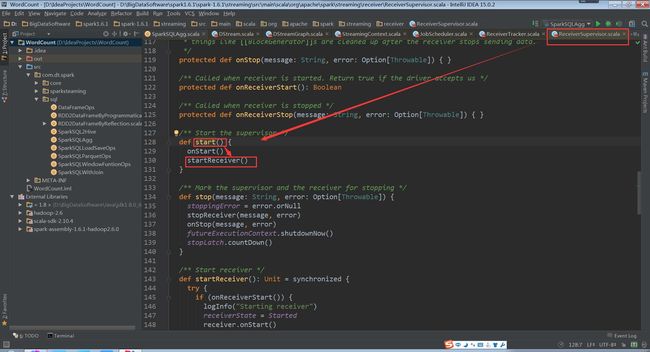
(ReceiverSupervisor.scala,148行代码)

举例解析:
以socketTextStream为例,其启动的是SocketReceiver,内部开启一个线程,来接收数据
(SocketInputDStream.scala,55~60行代码)

(SocketInputDStream.scala,73、77行代码)

store(iterator.next)内部调用Receiver中的store方法里supervisor的pushSingle方法,最终将数据聚集后存放在内存中
(Receiver.scala,73、77行代码)
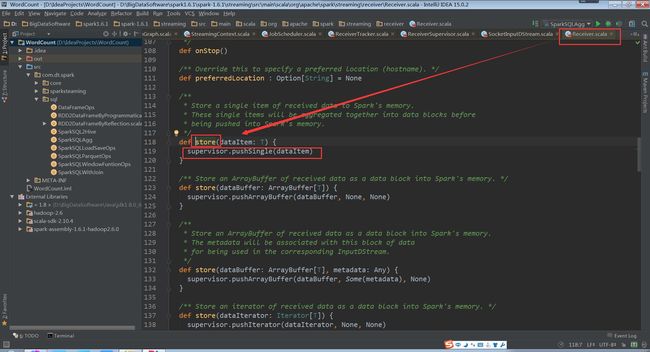
supervisor的pushSingle方法如下,将数据放入到defaultBlockGenerator中,defaultBlockGenerator为BlockGenerator,保存Socket接收到的数据
(ReceiverSupervisorImpl.scala,118行代码)

(BlockGeneratorListener.scala,162、165行代码)
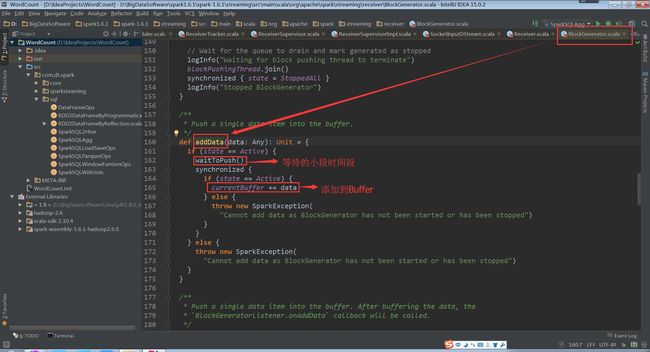
BlockGenerator对象中有一个定时器,来更新当前的Buffer
(BlockGenerator.scala,106行代码)
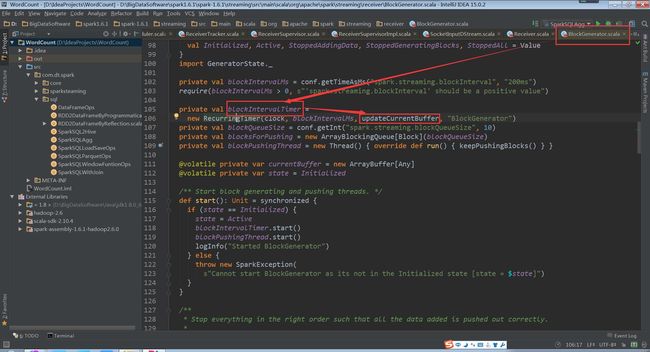
(BlockGenerator.scala,241、246行代码)
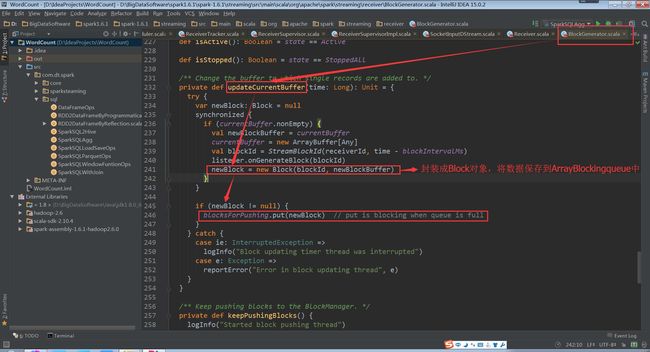
BlockGenerator对象中有一个线程,来从阻塞队列中取出数据
(BlockGenerator.scala,109行代码)

(BlockGenerator.scala,278行代码)

(BlockGenerator.scala,296行代码)

接下来会调用ReceiverSupervisorImpl类中的继承BlockGeneratorListener的匿名类中的onPushBlock方法
(ReceiverSupervisorImpl.scala,108行代码)

(ReceiverSupervisorImpl.scala,123、128行代码)
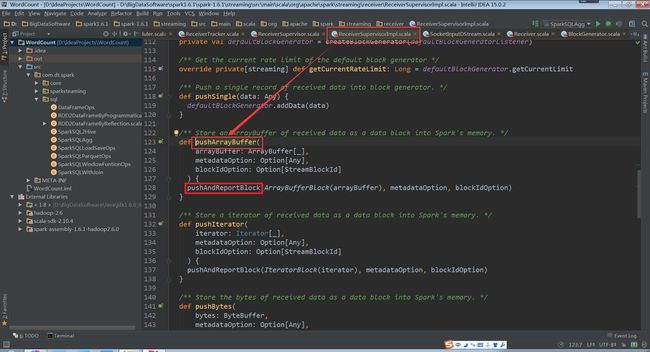
(ReceiverSupervisorImpl.scala,157、161行代码)

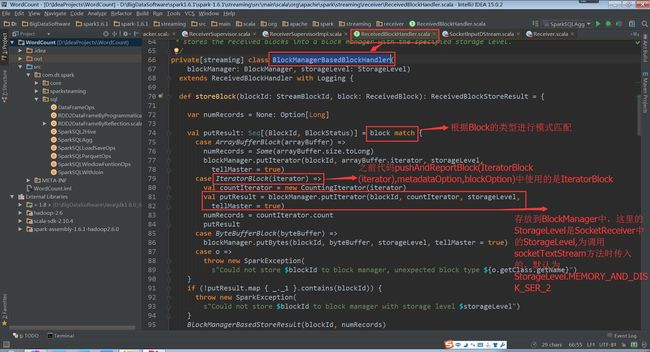
receivedBlockHandler对象如下
(ReceiverSupervisorImpl.scala,53~64行代码)

这里我们讲解BlockManagerBasedBlockHandler的方式
(BlockManagerBasedBlockHandler.scala,74、79、81行代码)
trackerEndpoint如下
(ReceiverSupervisorImpl.scala,70行代码)
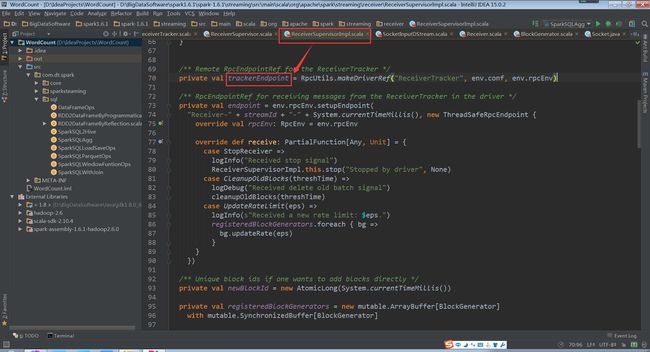
(RpcUtils.scala,31行代码)

其实是发送给ReceiverTrackerEndpoint类
(ReceiverTracker.scala,156行代码)

(ReceiverTracker.scala,495、507行代码)
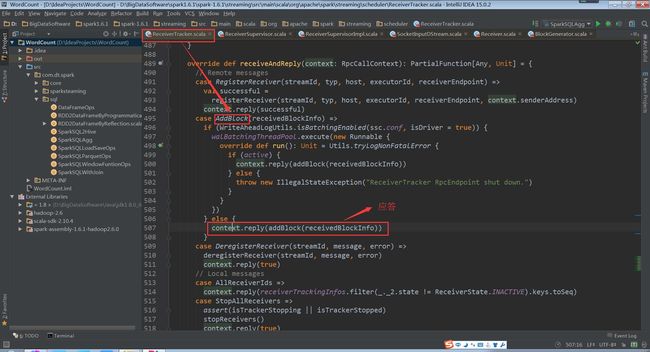
(ReceivedBlockTracker.scala,90行代码)

(ReceiverInputDStream.scala,69、81、85行代码)

InputInfoTracker类的reportInfo方法只是对数据进行记录统计
(InputInfoTracker.scala,64行代码)
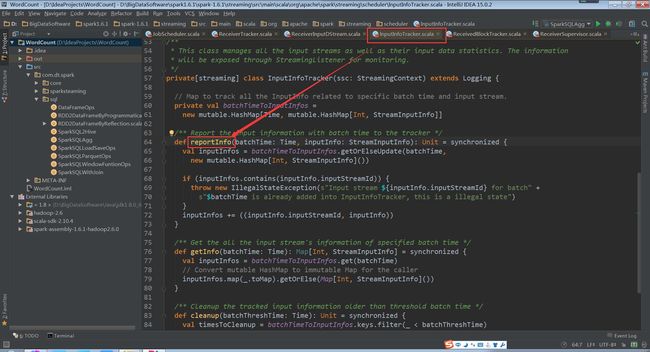
(DStreamGraph.scala,442、446、448行代码)
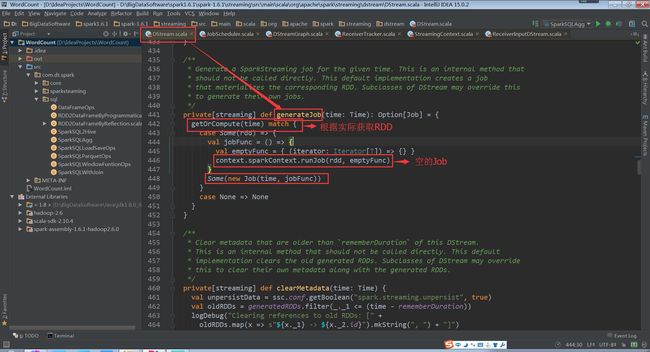
(DStreamGraph.scala,352行代码)
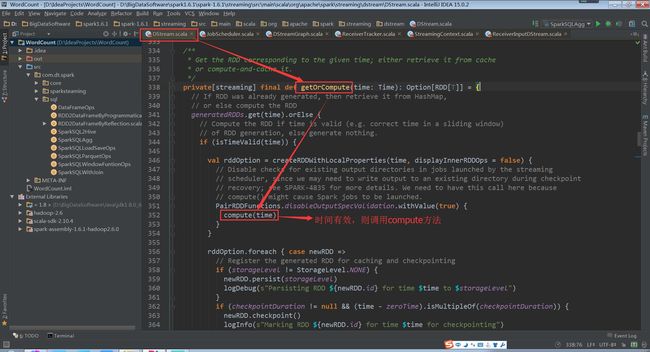
其generateJob方法是被DStreamGraph调用
(DStreamGraph.scala,115行代码)
DStreamGraph的generateJobs方法是被JobGenerator类的generateJobs方法调用
(JobGenerator.scala,248行代码)

JobGenerator类中有一个定时器,batchInterval发送GenerateJobs消息
(JobGenerator.scala,59行代码)
源码解密总结:
a,当调用StreamingContext的start方法时,启动了JobScheduler
b,当JobScheduler启动后会先后启动ReceiverTracker和JobGenerator
c,ReceiverTracker启动后会创建ReceiverTrackerEndpoint这个消息循环体,来接收运行在Executor上的Receiver发送过来的消息
d,ReceiverTracker在启动时会给自己发送StartAllReceivers消息,自己接收到消息后,向Spark提交startReceiverFunc的Job
e,startReceiverFunc方法中在Executor上启动Receiver,并实例化ReceiverSupervisorImpl对象,来监控Receiver的运行
f,ReceiverSupervisorImpl对象会调用Receiver的onStart方法,我们以SocketReceiver为例,启动一个线程,连接Server,读取网络数据先调用ReceiverSupervisorImpl的pushSingle方法,
保存在BlockGenerator对象中,该对象内部有个定时器,放到阻塞队列blocksForPushing,等待内部线程取出数据放到BlockManager中,并发AddBlock消息给ReceiverTrackerEndpoint。
ReceiverTrackerEndpoint为ReceiverTracker的内部类,在接收到addBlock消息后将streamId对应的数据阻塞队列streamIdToUnallocatedBlockQueues中
g,JobGenerator启动后会启动以batchInterval时间间隔发送GenerateJobs消息的定时器
h,接收到GenerateJobs消息会先后触发ReceiverTracker的allocateBlocksToBatch方法和DStreamGraph的generateJobs方法
i,ReceiverTracker的allocateBlocksToBatch方法会调用getReceivedBlockQueue方法从阻塞队列streamIdToUnallocatedBlockQueues中根据streamId获取数据
j,DStreamGraph的generateJobs方法,继而调用变量名为outputStreams的DStream集合的generateJob方法
k,继而调用DStream的getOrCompute来调用具体的DStream的compute方法,我们以ReceiverInputDStream为例,compute方法是从ReceiverTracker中获取数据
经典直说:
在空间维度上的业务逻辑作用于DStream,随着时间的流逝,每个Batch Interval形成了具体的数据集,产生了RDD,对RDD进行transform操作,进而形成了RDD的依赖关系RDD DAG,形成job。然后jobScheduler根据时间调度,基于RDD的依赖关系,把作业发布到Spark Cluster上去运行,不断的产生Spark作业。
备注:
1、DT大数据梦工厂微信公众号DT_Spark
2、Spark大神级专家:王家林
3、新浪微博: http://www.weibo.com/ilovepains