Windows 使用Eclipse配置连接hadoop,编译运行MapReduce --本地调试WordCount
一 . 准备工作
操作系统:windows 10
开发工具:eclipse 4.5
java虚拟机 :jdk 1.8 (jdk-8u91-windows-x64.exe) 官网下载地址http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-windows-x64.exe
hadoop版本:hadoop2.6 (hadoop-2.6.4.tar.gz) 官网下载地址http://apache.fayea.com/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
hadoop插件:hadoop-eclipse-plugin-2.6.0 是一个专门用于eclipse的hadoop插件,可以根据使用的hadoop版本编译,这里使用的是hadoop-eclipse-plugin-2.6.0.jar
hadoop2.6插件包:在hadoop2.6.0源码的hadoop-common-project\hadoop-common\src\main\winutils下,有一个vs.net工程,编译这个工程可以得到这一堆文件,输出的文件中,
hadoop.dll、winutils.exe (主要是防止插件报各种莫名错误,比如空对象引用)
注:如果不想编译,可直接下载编译好的文件hadoop2.6(x64).zip
二 . 安装过程
2.1 jdk
a. 安装过程
略
b. 环境变量
JAVA_HOME=C:\Program Files\Java\jdk1.8.0_91
classpath=.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
Path=;%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin
2.2 hadoop
a.安装过程
解压 hadoop-2.6.4.tar.gz 到 D:\hadoop >>D:\hadoop\hadoop-2.6.4 即可
b. 环境变量
HADOOP_HOME=D:\hadoop\hadoop-2.6.4
Path=;%HADOOP_HOME%\bin
2.3 hadoop eclipse插件
将下载后的hadoop-eclipse-plugin-2.6.0.jar复制到eclipse/plugins目录下,然后重启eclipse就OK了
2.4 hadoop2.6插件包
将winutils.exe复制到$HADOOP_HOME\bin目录,将hadoop.dll复制到%windir%\system32目录
三、Eclipse远程配置
重启Eclipse后,左侧出现DFS Localtions,下面Map/Reduce Localtions。
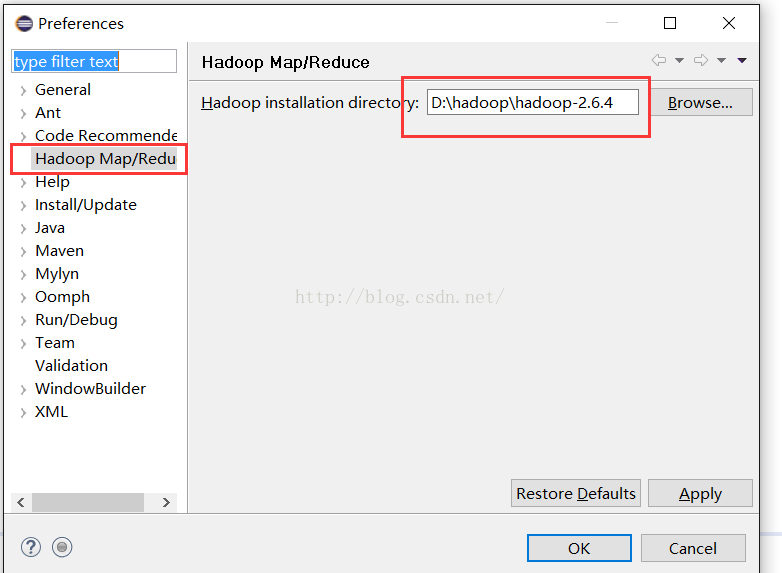
配置hadoop路径:Window 》Preferences ,选择Hadoop Map/Reduce ,输入hadoop的路径,如下
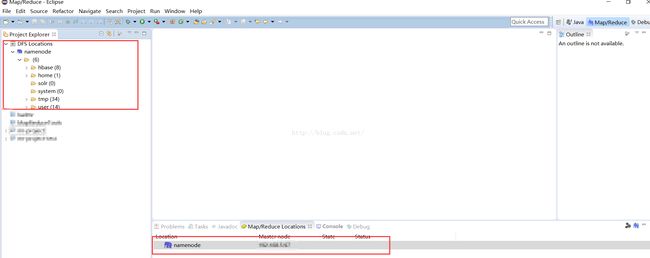
在Map/Reduce Localtions 下 点击“new hadoop location..” ,输入name node 节点的IP和端口,自定义Location name >> "namenode"

配置成功,则显示如下;否则会提示连接失败,如果失败,请检查IP和端口是否正确
四 新建MapReduce项目并运行--WordCount测试
1.新建MapReduce工程: File>New>Other>MapReduce,命名"mr-project"

2 .在src目录下创建package:org.apache.hadoop.examples
3 .把MapReduce的例子WordCount.java拷贝到org.apache.hadoop.examples
4.在src目录下创建log4j.properties日志,并配置以下信息

log4j.properties配置信息
- log4j.rootLogger=INFO, stdout
- log4j.appender.stdout=org.apache.log4j.ConsoleAppender
- log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
- log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
- log4j.appender.logfile=org.apache.log4j.FileAppender
- log4j.appender.logfile.File=target/spring.log
- log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
- log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5.点击WordCount.java右击-->Run As-->Run COnfigurations 设置输入和输出目录路径(注意,这个输入路径必须已经存在,并且有文件,输出目录则相反),点击Apply。如图所示:

6.点击WordCount.java右击-->Run As-->Run on Hadoop ,控制台打印如下信息
2016-05-04 09:42:55,326 INFO [org.apache.hadoop.conf.Configuration.deprecation] - session.id is deprecated. Instead, use dfs.metrics.session-id 2016-05-04 09:42:55,328 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId= 2016-05-04 09:42:56,050 WARN [org.apache.hadoop.mapreduce.JobResourceUploader] - No job jar file set. User classes may not be found. See Job or Job#setJar(String). 2016-05-04 09:42:56,125 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 1 2016-05-04 09:42:56,267 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:1 2016-05-04 09:42:56,351 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local384499348_0001 2016-05-04 09:42:56,571 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/ 2016-05-04 09:42:56,572 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local384499348_0001 2016-05-04 09:42:56,573 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null 2016-05-04 09:42:56,581 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 2016-05-04 09:42:56,688 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks 2016-05-04 09:42:56,689 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local384499348_0001_m_000000_0 2016-05-04 09:42:56,730 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux. 2016-05-04 09:42:56,780 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4e95064f 2016-05-04 09:42:56,786 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://192.168.5.97:8020/tmp/htb/mr/input/testcount.txt:0+168 2016-05-04 09:42:56,833 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584) 2016-05-04 09:42:56,833 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100 2016-05-04 09:42:56,833 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080 2016-05-04 09:42:56,833 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600 2016-05-04 09:42:56,833 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600 2016-05-04 09:42:56,837 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 2016-05-04 09:42:57,188 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 2016-05-04 09:42:57,191 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output 2016-05-04 09:42:57,191 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output 2016-05-04 09:42:57,191 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 295; bufvoid = 104857600 2016-05-04 09:42:57,191 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 26214272(104857088); length = 125/6553600 2016-05-04 09:42:57,212 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0 2016-05-04 09:42:57,219 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local384499348_0001_m_000000_0 is done. And is in the process of committing 2016-05-04 09:42:57,370 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map 2016-05-04 09:42:57,370 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local384499348_0001_m_000000_0' done. 2016-05-04 09:42:57,370 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local384499348_0001_m_000000_0 2016-05-04 09:42:57,370 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete. 2016-05-04 09:42:57,373 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks 2016-05-04 09:42:57,373 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local384499348_0001_r_000000_0 2016-05-04 09:42:57,382 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux. 2016-05-04 09:42:57,437 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@57df67ff 2016-05-04 09:42:57,441 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1cab5431 2016-05-04 09:42:57,454 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1310195712, maxSingleShuffleLimit=327548928, mergeThreshold=864729216, ioSortFactor=10, memToMemMergeOutputsThreshold=10 2016-05-04 09:42:57,457 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local384499348_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events 2016-05-04 09:42:57,490 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local384499348_0001_m_000000_0 decomp: 325 len: 329 to MEMORY 2016-05-04 09:42:57,497 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 325 bytes from map-output for attempt_local384499348_0001_m_000000_0 2016-05-04 09:42:57,500 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 325, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->325 2016-05-04 09:42:57,503 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning 2016-05-04 09:42:57,504 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied. 2016-05-04 09:42:57,505 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs 2016-05-04 09:42:57,521 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments 2016-05-04 09:42:57,522 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 321 bytes 2016-05-04 09:42:57,525 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 1 segments, 325 bytes to disk to satisfy reduce memory limit 2016-05-04 09:42:57,526 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 329 bytes from disk 2016-05-04 09:42:57,527 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce 2016-05-04 09:42:57,527 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments 2016-05-04 09:42:57,529 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 321 bytes 2016-05-04 09:42:57,530 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied. 2016-05-04 09:42:57,576 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local384499348_0001 running in uber mode : false 2016-05-04 09:42:57,577 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0% 2016-05-04 09:42:57,616 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords 2016-05-04 09:42:58,053 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local384499348_0001_r_000000_0 is done. And is in the process of committing 2016-05-04 09:42:58,095 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 1 / 1 copied. 2016-05-04 09:42:58,095 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local384499348_0001_r_000000_0 is allowed to commit now 2016-05-04 09:42:58,254 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local384499348_0001_r_000000_0' to hdfs://192.168.5.97:8020/tmp/htb/mr/ouput/_temporary/0/task_local384499348_0001_r_000000 2016-05-04 09:42:58,255 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce 2016-05-04 09:42:58,255 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local384499348_0001_r_000000_0' done. 2016-05-04 09:42:58,255 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local384499348_0001_r_000000_0 2016-05-04 09:42:58,256 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete. 2016-05-04 09:42:58,579 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100% 2016-05-04 09:42:59,580 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local384499348_0001 completed successfully 2016-05-04 09:42:59,592 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 38 File System Counters FILE: Number of bytes read=1104 FILE: Number of bytes written=509445 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=336 HDFS: Number of bytes written=211 HDFS: Number of read operations=13 HDFS: Number of large read operations=0 HDFS: Number of write operations=4 Map-Reduce Framework Map input records=2 Map output records=32 Map output bytes=295 Map output materialized bytes=329 Input split bytes=120 Combine input records=32 Combine output records=28 Reduce input groups=28 Reduce shuffle bytes=329 Reduce input records=28 Reduce output records=28 Spilled Records=56 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=5 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=503840768 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=168 File Output Format Counters Bytes Written=211
查看输出目录,如下
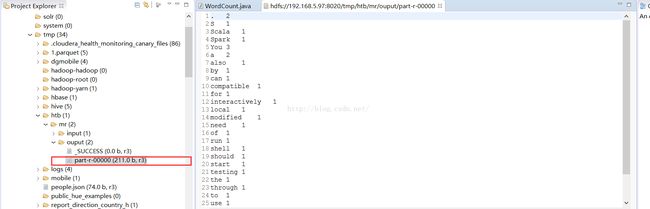
测试到这里,Eclipse远程调试hadoop就配置成功了,这里也可以设置断点调式!
log4j.properties主要解决Eclipse中运行MapReduce程序时控制台无法打印进度信息的问题,
如果没有log4j.properties配置文件,控制台只输出以下这些信息
- log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
- log4j:WARN Please initialize the log4j system properly.
- log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
配置过程中遇到可能会过几个问题,这里可以参考 http://my.oschina.net/muou/blog/408543
参考:http://www.cnblogs.com/yjmyzz/p/how-to-remote-debug-hadoop-with-eclipse-and-intellij-idea.html
参考:http://blog.csdn.net/hipercomer/article/details/27063577