HTTP报文
HTTP规范中说明起始行和首部以CRLF表示终止。
报文的语法:
所有HTTP报文都可以分成两类:请求报文(request message)和响应报文(response message)。请求报文会向Web服务器请求一个动作,响应报文会将请求的结果返回给号客户端。请求报文和响应报文的基本报文结构相同。如:

图1:包含请求和响应报文的HTTP事物
请求报文的格式:
<method> <request-URL> <version> <headers> <entity-body>
响应报文的格式:
<version> <status> <reason-phrase> <headers> <entity-bidy>
注意:请求报文和响应报文只有起始行的语法不同。
<1>方法(method):客户端希望服务器对资源执行的动作,是一个单独的词,如:GET、HEAD、POST。
<2>请求URL(request-URL):命名了所请求资源,或者URL路径组件的完整URL,如果直接与服务器直接对话,只要URL的路径组件是资源的绝对路径,通常不会有什么问题——服务器会假定自己是URL的主机/端口。
<3>版本(version):报文所使用的HTTP版本,其格式:
HTTP/<major>.<minor>
其中主要版本号(major)和次要版本号(minor)都是整数。
<4>状态码(status-code):以三位数字描述请求过程中所发生的状况,每个状态的第一位数字都用于描述状态的一般类别(“成功”、“出错”)。
<5>原因短语(reason-phrase):数字状态的可读版本,包含行终止序列之前的所有文本,原因短语只对人类有意义,如:HTTP/1.0 200 NOT OK 和 HTTP/1.0 200 OK。
<6>首部(header):可以有零个或者多个首部,每个首部都包含一个字,后面跟着一个冒号(:),然后是一个可选的空格,接着是一个值,最后是一个CRLF。首部是由一个空行(CRLF)结束的,表示了首部列表的结束和实体主体部分的开始。
<7>实体的主体部分(entity-body):实体的主体部分包含一个由任意数据组成的数据块,并不是所有的报文都包含实体的主体部分,有时,报文只是以一个CRLF结束。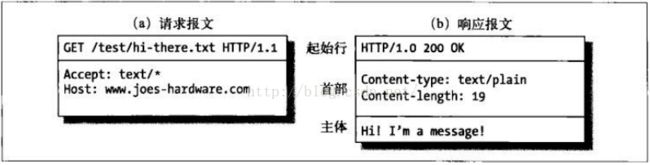
图2:请求和响应报文示例
注意: 一组HTTP首部总是应该以一个空行(单个CRLF)结束,甚至即使没有首部和实体的部分也应该如此。
起始行
所有的HTTP报文都以一个起始行作为开始。请求报文的起始行说明了要做些什么,响应报文的起始行说明发生了什么。
1、请求行(请求报文的起始行称为请求行)
请求报文请求服务器对资源进行一些操作。请求行包含了一个方法和一个URL,这个方法描述了服务器应该执行的操作,请求URL描述了要对那个资源执行这个方法,请求行中还包含HTTP的版本,用来告知服务器,客户端使用的是哪种HTTP。、所有这些字段都由空格分隔符。
2、响应行(响应报文的起始行称为响应行)
响应报文承载了状态信息和操作产生的所有结果数据,将其返回给客户端。响应行包含了响应报文使用的HTTP版本、数字状态码,以及描述操作状态的文本形式的原因短语。例:
HTTP/1.0200 OK;HTTP版本为HTTP/1.0,状态码为200(表示成功),原因短语为OK,表示文档已经被成功返回了。
3、方法
请求的起始行以方法作为开始,方法用来告诉服务器要做些什么。比如:在行:
“GET/special/saw-blage.gif HHTTP/1.0”中,方法就是GET。

表1 常用的HTTP方法
4、状态码
方法是用来告诉服务器做什么事情的,状态码则是用来告诉客户端发生了什么事情。状态码位于响应行中,如:HTTP/1.0 200 OK中,状态码就是200.
状态码是在每条响应报文的起始行中返回的,会返回一个数字状态和一个可读的状态。数字码便于程序进行差错处理,而原因短语则便于人们理解。
可以通过三位数字代码对不同状态码进行分类。200~299之间的状态码表示成功。 300~399之间的状态码表示资源已经被移走。400~499之间的状态码表示客户端的请求出错,500~599之间的状态码表示服务器出错了。
图3 状态码分类
表2 常用的状态码

5、原因短语
原因短语是响应行的最后一个组件,它为状态码提供了文本形式的解释。原因短语和状态码是成对出现的,原因短语是状态码的可读版本,应程序开发者将其传送给用户,用以说明在请求期间发生了什么情况。
6、版本号
版本号会以HTTP/x.y的形式出现在请求行和响应行中,为HTTP应用程序提供了一种将自己所遵循的协议版本告知对方的方式。
注意:版本号不会被当作分数来处理,版本中的每个数字都会被当做一个单独的数字来处理,因此,在比较HTTP版本时,每个数字都必须单独进行比较,以便确定哪个版本更高,比如:
HTTP/2.22就比HTTP/2.3的版本要高,因为22比3大。
首部
跟在起始行后面的 就是零个、一个或多个HTTP首部字段。HTTP首部字段向请求和响应的报文中添加了一些附加信息,本质上来说只是一些名/值对的列表
1、首部分类
•通用首部:既可以出现在请求报文也可以出现在响应报文中。
•请求首部:提供更多有关请求得信息。
•响应首部:提供更多有关响应信息。
•实体首部:描述主体的长度和内容、或者资源自身。
•扩展首部:规范中没有定义的新首部。
HTTP首部的简单语法:名字后面跟(:),然后跟上可选的空格,再跟上字段值,最后一个是一个CRLF。

图4 常见首部示例
2、首部延续行将长的首部分为多行可以提高可读性,多出来的每行前面至少要有一个空格或者制表符(tab)。例如:
HTTP/1.0 200 OK Content-Type:image/gif Content-Length:8572 Server:TestServer Version 1.0
主体的实体部分
响应报文里包含了一个Server首部,其值被划分为多个延续行,该首部的完整值为Test Server Version 1.0.
实体的主体是HTTP报文的负荷,就是HTTP要传输的内容。HTTP报文可以承载很多数据类型的数字数据:图片、视频。HTML文档、软件应用程序、信用卡事物、电子邮件。
方法
1、GET
GET是最常用的方法,通常用于请求服务器发送某个资源。如下图客户端使用GET方法发起一次HTTP请求。
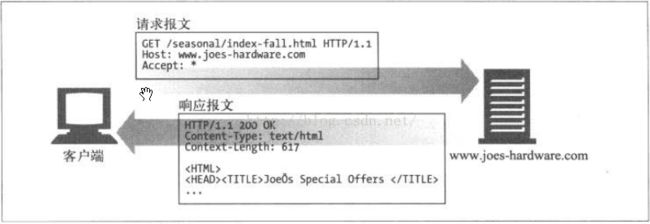
图5 GET 示例
2、HEAD
HEAD方法与GET方法类似,但是服务器在响应中只返回首部,不会返回实体的主体部分,这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。使用HEAD,可以:
·在不获取资源的情况下了解资源的情况(比如,判断其类型);
·通过查看响应中的状态码,看看某个对象是否存在;
·通过查看首部,测试资源是否被修改了;
如下图实际的HEAD方法:

图6 HEAD示例
3、 PUTPUT方法是向服务器写入文档。PUT方法的语义就是让服务器用请求的主体部分来创建一个由所请求的URL命名的新文档,或者,如果那个URL已经存在的话,就用这个主题来替换它。因为PUT允许用户对内容进行修改,所以很多Web服务器都要求在执行PUT之前,用密码登录。
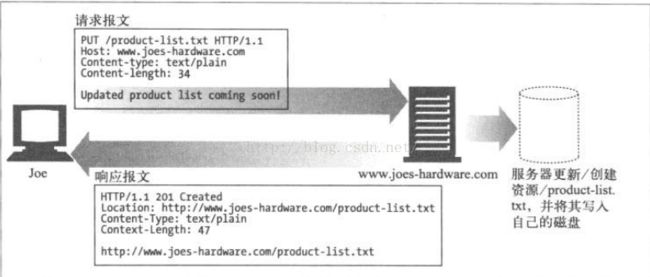
图7 PUT示例
4、POST
POST方法起初是用来向服务器输入数据的,实际上,通常会用它来支持HTML的表单,表单中填好的数据通常会被送给服务器,然后有服务器将其发送到它要去的地方。如下图,显示了一个用POST方法发起HTTP请求——向服务器发送表单数据——的客户端。
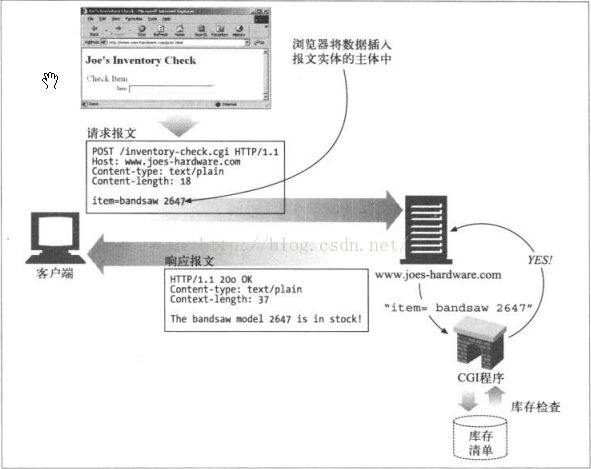
图8 POST示例
5、TRACE
客户端发起每一个请求时,这个请求可能要穿过防火墙、代理、网关或其他一些应用程序。中间每个节点都可能会修改原始的HTTP请求。TRACE方法允许客户端在最终将请求发送给服务器时,看看它变成了什么样子。
TRACE请求会在目的服务器端发起一个“环回”诊断,行程最后一站的服务器会弹出一条TRACE响应,并在响应主体中携带它收到的原始请求报文,这样客户端就可以查看所有中HTTP应用程序组成的请求/响应链上,原始报文是否以及如何被毁坏或者修改过。

图9 TRACE示例
TRACE方法主要用于诊断,也就是说,用于验证请求是否穿过了请求/响应链。它是一种很好的工具,可以用来查看代理和其他应用程序对用户请求所产生的效果。
TRACE请求中不能带有实体的主体部分,TRACE响应的实体主体部分包含了相应服务器收到的请求的精确副本。
6、OPTIONS
OPTIONS方法请求Web服务器告知其支持的各种功能,可以询问服务器通常支持哪些方法,或者对某些特殊资源支持哪些方法。这为客户端应用程序提供一种手段,使其不用实际访问那些资源就能判定访问各种资源的最优方式。下图是OPTION方法的请求示例:
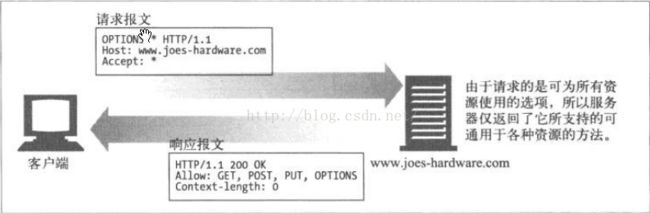
图10 OPTIONS 示例
7、DELETEDELETE方法就是请求服务器删除请求URL所指定的资源。但是,客户端应用程序无法保证删除操作一定会被执行,因为HTTP规范允许服务器在不通知客户端的请求下撤销请求。
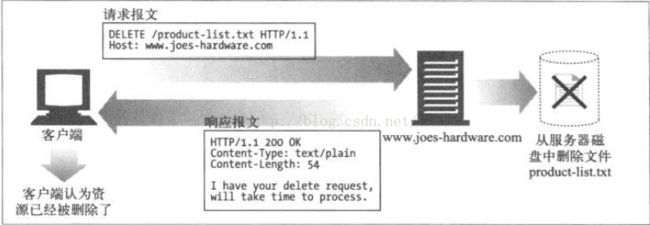
图11 DELETE示例
状态码
1、100~199(1xx)——信息性状态码
HTTP/1.1向协议中引入了信息性状态码,如下图已经定义的信息性状态码。

图12 信息性状态码及原因短语
100Continue状态码的目的是:HTTP客户端应用程序有一个实体的主体部分要发送给服务器,但希望在发送之前查看一下服务器是否会接受这个实体。由于比较难理解,现在详细讨论:
·客户端与100 Continue
如果客户端在向服务器发送一个实体,并且愿意在发送实体之前等待100 Continue响应,那么,客户端就要发送一个携带值为100 Continue的Expect请求首部。如果客户端没有发送实体,就不应该发送100 Continue Expect首部,因为这样会使服务器误以为客户端要发送一个实体。
客户端应用程序只有在避免向服务器发送一个无法处理或使用的大实体时,才应该使用100 Continue。
在发送了100 Continue的Expect首部的客户端不应该永远在那儿等待服务器发送100 Continue响应。超时一定时间之后,客户端应该直接将实体发送出去。
·服务器与100 Continue
如果服务器收到了一条带有值为100Continue的Expect首部的请求,它会用100 Continue响应或一条错误代码来进行响应。服务器永远也不应该向没有发送100 Continue期望的客户发送100 Continue期望的客户端发送100 Continue状态码。
如果出于某种原因,服务器在有机会发送100Continue响应之前就收到了部分或者全部的实体,就是说明客户端已经决定继续发送数据了,这样,服务器就不需要发送这个状态码了。但服务器读完请求之后,还是应该为请求发送一个最终状态码(它可以跳过100 Continue状态)。
如果服务器接收到带有100Continue期望的请求,但是服务器决定在读取主体部分之前(比如,因为出错)结束请求,就不应该仅仅是发送一条响应并关闭连接,因为这样会妨碍客户端的接收响应。
·代理与100 Continue
如果代理从客户端收到了一条带有100 Continue期望的请求,那么它需要知道下一跳服务器是否是HTTP/1.1兼容的,或者不知道下一跳服务器与哪个版本兼容,它都应该将Expect首部放在请求中向下转发。
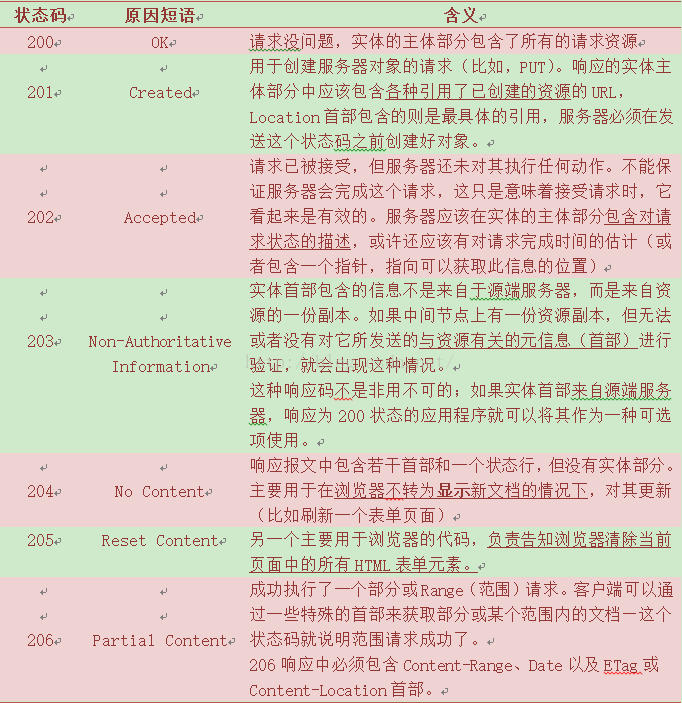
2、200~299——成功状态码
客户端发起请求的时候,这些请求通常都是成功的
表3 成功状态码和原因短语
3、300~399——重定向状态码
重定向状态码是用来告知客户端使用替代位置来访问他们所感兴趣的资源,或者提供一个替代的响应,而不是资源的内容。如果资源已经被移走,可以发送一个重定向状态码和一个可选的Location首部来告知客户端资源已经被移走,以及现在在哪里可以找到它,这样浏览器就可以在不打扰使用者的情况下,透明地转入新的位置了。如下图:
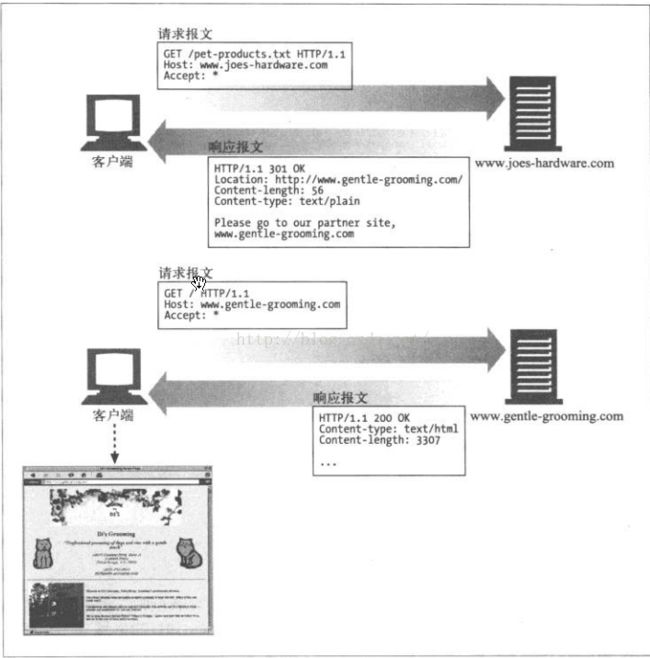
图13 将请求重定向到新的位置
可以通过重定向状态码对资源的应用程序本地副本与源端服务器上的资源进行验证。比如HTTP应用程序可以查看资源的本地副本是否仍然是最新的,或者在源端服务器上资源是否被修改过。如下图所示的例子,客户端发送了一个特殊的If-Modified-Since首部,说明只读取1977年10月之后修改过的文档。这个日期之后,此文档并未被修改过,因此服务器送回了一个304状态码,而不是文档的内容。
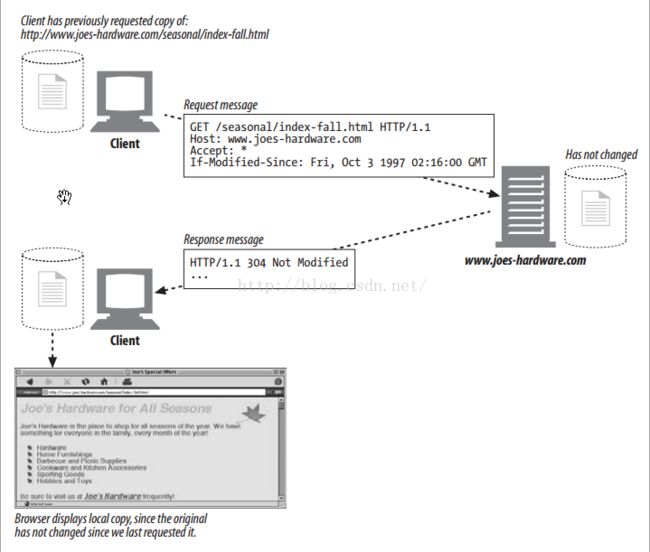
图14 重定向使用本地副本的请求
在对那些包含了重定向状态码的非HEAD请求进行响应时,最好要包含一个实体,并在实体中包含描述信息和指向(多个)重定向URL的连接,如图13;
表4 重定向状态码及原因短语
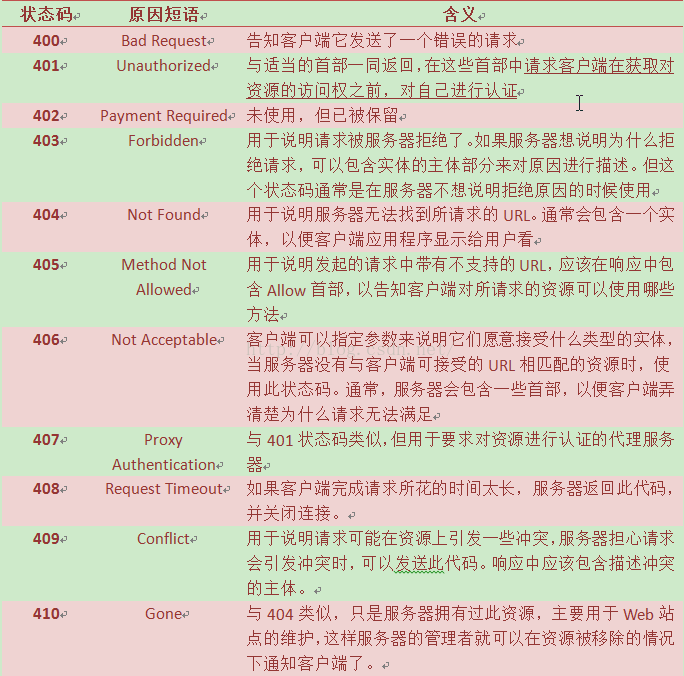
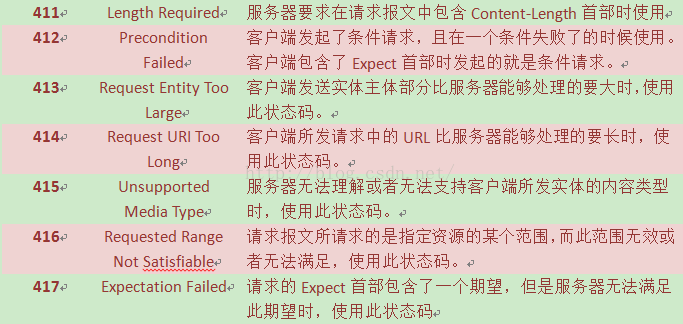
4、400~499——客户端错误状态码
有时客户端会发送一些服务器无法处理的东西,比如格式错误的请求报文,或者请求一个不存在的URL。比如404 Not Found错误代码,表示服务器对我们的请求一无所知。很多客户端错误都是由浏览器来处理的,甚至不会打扰到你,只有少量错误,比如404,会穿过浏览器呈现到用户面前。
表5 客户端错误状态码及原因短语
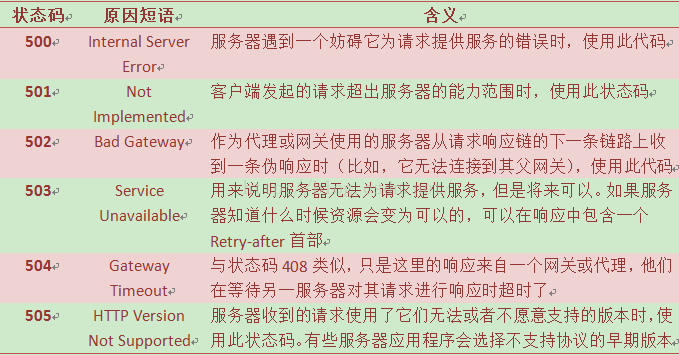
5、500~599——服务器错误状态码
有时候客户端发送了一条有效请求,服务器自身却出现错误了,可能是服务器缺陷,或者网关资源出错了。
表6服务器错误状态码及原因短语
首部
首部和方法配合工作,共同决定了客户端和服务器能做什么事务。
•通用首部
这些是客户端和服务器都可以使用的通用首部,可以在客户端、服务器和其他应用程序之间提供一些非常有用的通用功能,比如,Date首部,每一端都可以用它来说明构建报文的时间和日期:
Date: Tue, 3 Oct 1974 02:16:00 GMT
表7 通用的信息性首部

通用缓存首部
HTTP/1.0引入了第一个允许HTTP应用程序缓存对象的本地副本的首部,这样就不需要总是直接从源服务器获取了。
表8 通用缓存首部

·请求首部
它们为服务器提供一些额外的信息,比如客户端希望接收什么类型的数据。例如,下面的Accepted首部就用来告知服务器客户端会接受与请求相符的任意媒体类型:
Accept: */*
请求首部只在请求报文中有意义,用于说明是谁或者什么在发送请求、请求来自何处、或者客户端的喜好及能力。服务器可以根据请求首部给出的客户端信息,试着为客户端提供更好的响应。
表 9 请求的信息性首部

<1>.Accept首部
Accept首部为客户端提供了一种将其喜好和能力告知服务器的方式,包括他们想要什么,可以使用什么,以及什么最重要,他们不想要什么。这样服务器就可以根据这些额外的信息,对要发送的内容作出更明智的决定。
表10 Accept 首部

<2>.条件请求首部
有时客户端希望请求加上某些限制,比如,如果客户端已经有了一份文档副本,那么只有当服务器上的文档和客户端的文档不同时,才请求服务器传输文档,通过条件请求首部,客户端就可以为请求加上这种限制,要求服务器在对请求响应之前,确保某个条件为真。
表 11 条件请求首部

<3>.安全请求
HTTP本身就支持一种简单的机制,可以对请求进行质询/响应认证。这种机制要求客户端在获取特定的资源之前,先对自身进行认证,这样就可以使事物稍微安全些。
表 12 安全请求首部

<4>.代理请求首部
表13代理请求首部

·响应首部
响应首部有自己的首部集,以便为客户端提供信息(比如,客户端在与哪种类型的服务器进行交互、响应者的功能,甚至与响应相关的特殊命令)。例如:下列Server首部就用来告知客户端它在与一个版本1.0的Tiki-Hut服务器进行交互:
Server: Tiki-Hut/1.0
表 14 响应的信息性首部

<1>.协商首部
如果资源有多种表示方法—比如,如果服务器有某文档的语法和德语译稿,HTTP/1.1可以为服务器和客户端提供对资源的协商能力。
表 15 协商首部

<2>.安全响应首部
安全响应首部则是HTTP的质询/响应认证机制的响应侧。
表16 安全响应首部

·实体首部
实体首部指的是应用于对应实体主体部分的首部。比如,可以实体首部来说明实体主体部分的数据类型。例如,可以通过下列Content-Type首部告知应用程序,数据是以iso-latin-1字符集表示的HTML文档。
Content-Type: text/html; charset=iso-latin-1
实体首部可以告知报文的接受者它在对什么进行处理。
表17 实体信息性首部

<1>.内容首部
内容首部提供了实体类型、尺寸以及处理它所需的其他有用信息。比如Web浏览器可以通过查看返回的内容类型,得知如何显示对象。
表 18 内容首部

<2>.实体缓存首部
通用的缓存首部说明了如何或什么时候进行缓存。实体的缓存首部提供了与被缓存的实体有关的信息—比如,验证已缓存的资源副本是否仍然有效,所需的信息。以及更好地估计已缓存资源合适失效,所需的线索。
表 19 实体缓存首部
