openstack基础_eventlet
0. 说明
本博客欢迎转载,但请注明出处 http://blog.csdn.net/RingoShen/article/details/51119232
由于能力与时间有限,文章内容难免错漏,望大家多加指正,相互进步!
1. greenlet学习
1.1 greenlet简介
greenlet本质上讲是串行的,是通过程序控制的方式来协同调度的,与多线程/多进程的方式有本质的区别。多线程/多进程模型从并发的角度考虑问题,运行过程需要考虑互斥等问题,需要对互斥资源进行加锁保护。而greenlet则是从避免阻塞的方式进行开发的,是一种合理安排的串行。
1.2 greenlet使用
greenlet的基本使用较为简单,首先看一下官网上的例子。
from greenlet import greenlet
def test1():
print 12
gr2.switch()
print 34
def test2():
print 56
gr1.switch()
print 78
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch()程序的输出是:
12
56
34
观察程序输出可以发现78并未输出,这边就得提到几个知识点:
- Parent,parent可以理解为一个greenlet的上层对象,举个例子说,可以理解为gr1=greenlet(test1)是在当前主进程声明的,所以gr1的parent是当前主进程的greenlet对象。
- greenlet.switch()为切换greenlet对象的函数,值得一提的是,当要切换到的目标对象还未激活(从未运行过)时,在切换过程中会执行初始化动作并运行。
- 被调用的greenlet对象返回时,程序会切换至当初调用它的switch处继续运行,也就是“在哪摔倒,在哪站起来”。
- greenlet对象执行结束之后返回它的parent继续执行。
综合以上几点,不难得出程序输出结果。
再举个简单的例子,测试一下是否对上述几点要求已经理解。
from greenlet import greenlet
def test1(x):
print x
gr2.switch()
print 34
def test2():
print 56
return 78
gr1 = greenlet(test1)
gr2 = greenlet(test2)
gr1.switch(12)程序的输出是:
12
56
78
原因不再阐述,详见上述几点。
需要简单说明的是switch也是可以传参的。
通过上诉两个例子应该已经简单了解了greenlet的使用,如想了解greenlet更多的操作可以详见greenlet官方文档。
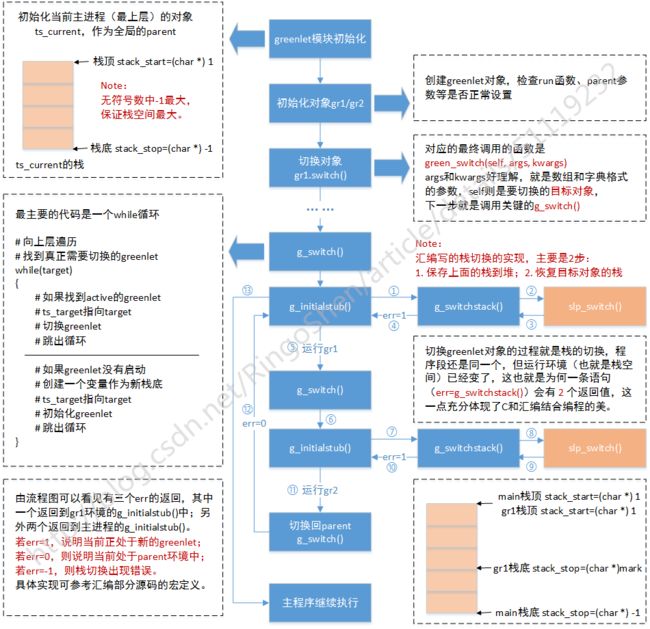
1.3 greenlet源码分析 *
greenlet源码是C写的,主要的栈切换部分代码是用汇编写的,看起来还是比较累的。我并没有深入到细节去看,有兴趣的可以看一下greenlet的源码,思想还是挺有意思的。接下来就上面第二个例子我画了流程图进行源码解析。如果想要了解更为详细的代码解析可以参考这篇博客python协程的实现和greenlet源码
2. eventlet学习
2.1 eventlet简介
eventlet是python的一个网络库,它将协程称之为GreenThread,通过创建多个GreenThread并管理的方式实现并发。可以发现,eventlet在协程这一块几乎是完全采用greenlet的方式。
2.2 eventlet使用
2.2.1 简单例子
可以先看一个非常简单的例子。
import eventlet
def func(*args, **kwargs):
... ...
return 0
gt = eventlet.spawn(func, *args, **kwargs)
gt.wait() # 真正开始执行我们可以发现,整个流程与greenlet十分相似,相当于是从当前进程切换到了gt,如果有什么不理解,可以参考上面的greenlet流程。当然,eventlet的使用方法还有很多,以上是OpenStack中最为常用的方式。
2.2.2 WSGI Server
接下来我们看一个官网的简单的例子,是eventlet实现WSGI Server的例子。
"""This is a simple example of running a wsgi application with eventlet. For a more fully-featured server which supports multiple processes, multiple threads, and graceful code reloading, see: http://pypi.python.org/pypi/Spawning/ """
import eventlet
from eventlet import wsgi
def hello_world(env, start_response):
if env['PATH_INFO'] != '/':
start_response('404 Not Found', [('Content-Type', 'text/plain')])
return ['Not Found\r\n']
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['Hello, World!\r\n']
wsgi.server(eventlet.listen(('', 8090)), hello_world)例子中,函数hello_world(env, start_response)是一个app,相当于一个http响应处理函数,服务开启之后由这个app对接收到的http请求进行处理,更多的关于WSGI的内容可以参见下一篇日志。在这一节中我们主要关注最后一句,显而易见是创建了一个wsgi的server,监听所有到8090端口的请求(socket),使用函数hello_world进行处理。
为什么讲这个例子呢,因为在OpenStack中就有类似的实现,我们可以看一下Nova部分的源码。
# nova/wsgi.py
class Server(service.ServiceBase):
... ...
def start(self):
... ...
wsgi_kwargs = {
'func': eventlet.wsgi.server,
'sock': dup_socket,
'site': self.app,
'protocol': self._protocol,
'custom_pool': self._pool,
'log': self._logger,
'log_format': CONF.wsgi_log_format,
'debug': False,
'keepalive': CONF.wsgi_keep_alive,
'socket_timeout': self.client_socket_timeout
}
if self._max_url_len:
wsgi_kwargs['url_length_limit'] = self._max_url_len
self._server = utils.spawn(**wsgi_kwargs)我们可以看见,虽然形式不一样,但是本质是不变的,我们关注前面三个参数,func是wsgi的server,sock是监听端口的socket,site是响应http请求的app。封装完成之后开始调用spawn方法,我们可以看一下utils中的代码。
# nova/utils.py
def spawn(func, *args, **kwargs):
_context = common_context.get_current()
@functools.wraps(func)
def context_wrapper(*args, **kwargs):
# NOTE: If update_store is not called after spawn it won't be
# available for the logger to pull from threadlocal storage.
if _context is not None:
_context.update_store()
return func(*args, **kwargs)
return eventlet.spawn(context_wrapper, *args, **kwargs)我们可以发现最终还是调用eventlet的spawn方法来创建一个GreenThread对象。
2.2.3 绿色线程池(GreenPool)
eventlet.GreenPool是一个类,在这个类中用set集合来容纳所创建的绿色线程,并且可以指定容纳线程的最大数量(默认是1000个),它的内部是用Semaphore和Event这两个类来对池进行控制的,这样就构成了线程池,下面有一些重要的方法:
running():返回当前池中的绿色线程数
free():返回当前池中可容纳的绿色线程数
spawn()/spawn_n():创建新的绿色线程
starmap()/imap():生成迭代器计算结果[和标准库itertools中的效果一样]
GreenPool跟直接使用eventlet在创建线程的操作上并没有太大区别,两者调用spawn等方法时都是直接调用的GreenThread来实现的,接下来简单看一下一个官网的爬虫的例子。
import eventlet
from eventlet.green import urllib2
urls = ["http://www.google.com/intl/en_ALL/images/logo.gif",
"https://wiki.secondlife.com/w/images/secondlife.jpg",
"http://us.i1.yimg.com/us.yimg.com/i/ww/beta/y3.gif"]
def fetch(url):
return urllib2.urlopen(url).read()
pool = eventlet.GreenPool()
for body in pool.imap(fetch, urls):
print("got body", len(body))程序不难理解,首先创建一个绿色线程池,然后调用imap方法迭代爬取urls中的网址获取内容并计算长度。
而有关GreenPool的使用在Nova中也有相应的操作。
# nova/compute/manager.py
class ComputeManager(manager.Manager):
... ...
def __init__(self, compute_driver=None, *args, **kwargs):
... ...
self._sync_power_pool = eventlet.GreenPool()
... ...
@periodic_task.periodic_task(spacing=CONF.sync_power_state_interval, run_immediately=True)
def _sync_power_states(self, context):
... ...
def _sync(db_instance):
# NOTE(melwitt): This must be synchronized as we query state from
#two separate sources, the driver and the database.
#They are set (in stop_instance) and read, in sync.
@utils.synchronized(db_instance.uuid)
def query_driver_power_state_and_sync():
self._query_driver_power_state_and_sync(context, db_instance)
try:
query_driver_power_state_and_sync()
except Exception:
LOG.exception(_LE("Periodic sync_power_state task had an " "error while processing an instance."), instance=db_instance)
self._syncs_in_progress.pop(db_instance.uuid)
for db_instance in db_instances:
# process syncs asynchronously - don't want instance locking to
# block entire periodic task thread
uuid = db_instance.uuid
if uuid in self._syncs_in_progress:
LOG.debug('Sync already in progress for %s' % uuid)
else:
LOG.debug('Triggering sync for uuid %s' % uuid)
self._syncs_in_progress[uuid] = True
self._sync_power_pool.spawn_n(_sync, db_instance)这是nova同步数据库和VMM的一个方法,里面创建了一个绿色线程池,然后以_sync作为处理函数func,db_instance作为_sync的参数传入spawn_n方法创建一个GreenThread对象(即绿色线程)。
2.2.4 补丁(Patch)
eventlet.green中的模块改写了部分Python标准库的实现,如果想要使用eventlet.green中的模块可以通过打补丁的方式。
打补丁主要有两种方式,这里只介绍最常用的一种。
import eventlet
eventlet.monkey_patch(all=True, os=False, select=False, socket=False, thread=False, time=False)在全局中为指定的系统模块打补丁,补丁后的模块是“绿色线程友好的”,关键字参数指示哪些模块需要被打补丁,如果all=True,则所有模块都打补丁。
值得一提的是,多数参数为与自己同名的模块打补丁,如os, time, select,但是 socket 参数为真时,如果 ssl 模块也存在,会同时补丁socket模块和ssl模块,类似的,thread参数为真时,会补丁thread, threading 和 Queue 模块。
这边直接看一个nova打补丁的例子。
# nova/cmd/__init__.py
import eventlet
from nova import debugger
if debugger.enabled():
# turn off thread patching to enable the remote debugger
eventlet.monkey_patch(os=False, thread=False)
else:
eventlet.monkey_patch(os=False)这段代码意味着在调试模式的时候禁用多线程的方式,在其他模式时不禁用多线程。调试过OpenStack代码的童鞋都知道,如果不禁用多线程,代码会直接进入python的thread模块,调试是很难进行的。
以上就是eventlet的一些简单的应用,如想了解更多内容可参见eventlet官方文档以及官网文档翻译