进程—Linux进程描述符初印象
进程内核栈结构:union task_union
在../include/linux/sched.h中定义了如下一个联合结构用来创建内核栈空间。
//../include/linux/sched.h
union task_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
}:
线程描述符:struct thread_info
每一个进程都有一个进程描述符task_struct,且有一个用来定位它的结构thread_info,thread_info位于其进程内核栈中(有些实现没有用到thread_info,而是使用一个寄存器来记录进程描述符的地址),操作系统使用这个结构中的task指针字段找到进程的进程描述符,从而得到执行一个进程所需的全部信息。
//../arch/xtensa/include/asm
struct thread_info {
struct task_struct *task; //指向当前进程内核栈对应的进程的进程描述符
struct exec_domain *exec_domain;
__u32 flags;
__u32 status;
__u32 cpu;
int preempt_count;
mm_segment_t addr_limit;
struct restart_block restart_block;
void *sysenter_return;
int uaccess_err;
};内核使用
alloc_thread_info和free_thread_info宏分配和释放存储thread_info结构和内核栈的内存区。使用current_thread_info()函数获取当前操作的进程的thread_info 。为了获得当前在CPU上运行的进程的进程描述符指针,内核要调用current宏,该宏本质上等价于current_thread_info()->task。详见【深入理解Linux内核】中文第三版91页。
进程描述符:task_struct
从内核观点看,进程的目的就是担当分配系统资源(CPU 时间、内存等)的实体。为此目的,操作系统为每个进程维持着一个进程描述符。
task_struct 示意图:

源代码
在../include/linux/sched.h中定义了task_struct,其中包含了一个进程所需的全部信息。其结构体实例在内存中的大小一般在1KB以上。
//../include/linux/sched.h
//---------------------------------------------------进程描述符结构定义---------------------------------------------------
struct task_struct
{
//---------------------------------------------------------进程状态------------------------------------------------------------
long state; //任务的运行状态
//---------------------------------------------------------进程标识信息---------------------------------------------------------
pid_t pid; //进程ID
pid_t pgrp; //进程组标识,表示进程所属的进程组,等于进程组的领头进程的pid
pid_t tgid; //进程所在线程组的ID,等于线程组的领头线程的pid,getpid()系统调用返回tgid值。
pid_t session; //进程的登录会话标识,等于登录会话领头进程的pid。
struct pid pids[PIDTYPE_MAX]; //PIDTYPE_MAX=4,一共4个hash表。
char comm[TASK_COMM_LEN]; //记录进程的名字,即进程正在运行的可执行文件名
int leader; //标志,表示进程是否为会话主管(会话领头进程)。
//-------------------------------------------------------进程调度相关信息-------------------------------------------------------
long nice;//进程的初始优先级,范围[-20,+19],默认0,nice值越大优先级越低,分配的时间片
//可能越少。
int static_prio;//静态优先级。
int prio;//存放调度程序要用到的优先级。
/* 0-99 -> Realtime process 100-140 -> Normal process */
unsigned int rt_priority;//实时优先级,默认情况下范围[0,99]
/* 0 -> normal 1-99 -> realtime */
unsigned long sleep_avg;//这个字段的值用来支持调度程序对进程的类型(I/O消耗型 or CPU消耗型)进行
//判断,值越大表示睡眠的时候更多,更趋向于I/O消耗型,反之,更趋向于CPU消耗型。
unsigned long sleep_time;//进程的睡眠时间
unsigned int time_slice;//进程剩余时间片,当一个任务的时间片用完之后,要根据任务的静态优先级
//static_prio重新计算时间片。task_timeslice()为给定的任务返回一个新的时间片。对于交互性强的进程,时间片用完之后,它
//会被再放到活动数组而不是过期数组,该逻辑在scheduler_tick()中实现。
#if defined(CONFIG_SCHEDSTATS)||define(CONFIG_TASK_DELAY_ACCT)
unsigned int policy;//表示该进程的进程调度策略。调度策略有:
//SCHED_NORMAL 0, 非实时进程, 用基于优先权的轮转法。
//SCHED_FIFO 1, 实时进程, 用先进先出算法。
//SCHED_RR 2, 实时进程, 用基于优先权的轮转法
#endif
struct list_head tasks;//任务队列,通过这个寄宿于PCB(task_struct)中的字段构成的双向循环链表将宿主
//PCB链接起来。
struct list_head run_list;//该进程所在的运行队列。这个队列有一个与之对应的优先级k,所有位于这个队列中
//的进程的优先级都是k,这些k优先级进程之间使用轮转法进行调度。k的取值是0~139。这个位于宿主PCB中的struct list_head类
//型的run_list字段将构成一个优先级为k的双向循环链表,像一条细细的绳子一样,将所有优先级为k的处于可运行状态的进程的
//PCB(task_struct)链接起来。
prio_array_t *array; //typedef struct prio_array prio_array_t; 可以说,这个指针包含了操作
//系统现有的所有按PCB的优先级进行整理了的PCB的信息。
//---------------------------------------------------------进程链接信息---------------------------------------------------------
struct task_struct *real_parent;//指向创建了该进程的进程的进程描述符,如果父进程不再存在,就指向进程
//1(init)的进程描述符。
struct task_struct *parent;//recipient of SIGCHLD, wait4() reports. parent是该进程现在的父进程,
//有可能是“继父”
struct list_head children;//list of my children. children指的是该进程孩子的链表,使用
//list_for_each和list_entry,可以得到所有孩子的进程描述符。
struct lsit_head sibling;//linkage in my parent's children list.
//sibling为该进程的兄弟的链表,也就是其父亲的所有孩子的链表。用法与children相似。
struct task_struct *group_leader;//threadgroup leader,主线程描述符
struct list_head thread_group; //线程组链表,也就是该进程所有线程的链表。
//----------------------------------------------------------......------------------------------------------------------------
};参考
进程描述符结构定义的部分注释
反斜杠作用“\”
Linux3.0.6内核task_struct注释
do {…} while (0) 在宏定义中的作用
进程状态:state
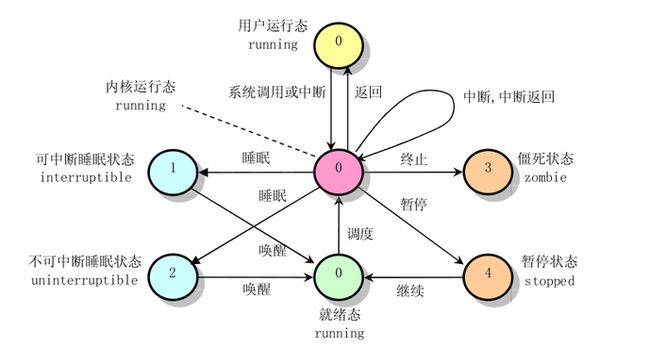
state字段的值通常用一个简单的赋值语句设置。例如:
p->state = TASK_RUNNING;,内核也使用set_task_state和set_current_state宏,分别设置指定进程的状态和当前执行进程的状态。
//../include/linux/sched.h
#define set_task_state(tsk, state_value) \
set_mb((tsk)->state, (state_value))
#define set_current_state(state_value) \
set_mb(current->state, (state_value))set_mb函数确保编译程序或CPU 控制单元不把赋值操作与其他指令混合。混合指令的顺序有时会导致灾难性的后果。
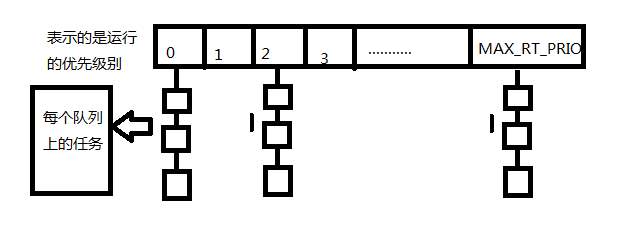
优先级数组:struct prio_array
//../kernel/sched.c
struct prio_array{
int nr_active;//各个优先级任务的总数目
unsigned long bitmap[BITMAP_SIZE];//优先级位图
struct list_head queue[MAX_PRIO];//优先级队列
}MAX_PRIO定义了系统拥有的优先级个数,默认值是140,每个优先级都有一个list_head结构体队列。
BITMAP_SIZE是优先级位图数组的大小,每一位代表一个优先级,140个优先级需要5个长整型才能表示,所以bitmap含有5个数组项,共160位(unsigned long 是32位)。当某个拥有一定优先级的进程开始准备执行时(state为TASK_RUNNING),位图中的相应位就会被置1。查找系统中最高的优先级就变成了查找位图中被设置的第一个位。因为优先级个数是个定值,所以查找时间恒定,并不受系统到底有多少可执行进程的影响
sched_find_first_bit()函数实现了对位图的快速查找算法。优先级数组中包含一个struct list_head队列,队列一共有MAX_PRIO个struct list_head链表,每个链表与一个给定的优先级相对应,事实上,每个链表都包含该处理器队列上相应优先级的全部可运行进程。对于给定的优先级,按轮转方式调度任务。
为什么要使用带头结点的循环链表:
这是一个在设计系统的数据结构时需要考虑的问题,例如,如果使用不带头结点的循环链表的实现,prio_array的queue字段内的元素就可以用struct list_head*的头指针来代替原来的struct list_head的头结点,这样queue就是一个struct list_head*的数组,因为struct list_head结构体有两个指针字段,所以这种实现可以节省一半的空间,可是,如果没有头结点,后续对循环链表的操作(插入、删除)将存在不一致性,每次操作还得考虑是不是涉及到了头指针的变化。
实例图:
添加到非头指针指向结点之前:
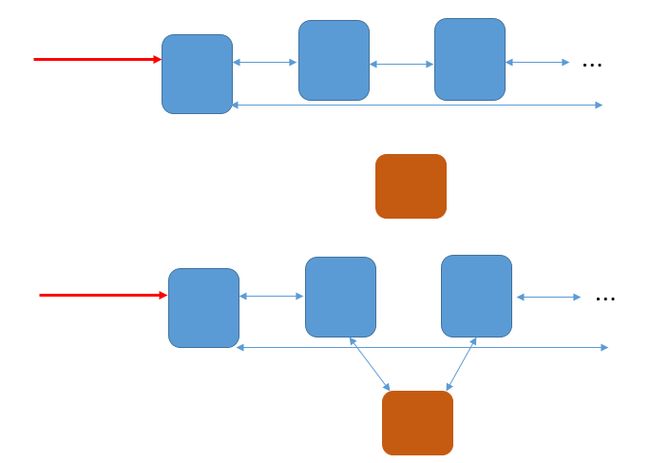
添加到头指针指向结点之前:

这两种添加的操作是不相同的。采用带有头结点的循环链表的实现就不会出现这种不一致性的问题,减少了在每一次操作前的判断步骤,如果对链表的操作十分频繁,就能提高一些性能。
可执行队列结构:struct runqueue
可执行队列是给定处理器上的可执行进程的链表,每个处理器一个。每个可投入运行的进程都唯一的归属于一个可执行队列。这里面还包含每个处理器的调度信息。
//../kernel/sched.c
//---------------------------------可执行队列结构定义---------------------------------
struct runqueue {
spinlock_t lock; //保护运行队列的自旋锁,自旋锁用于防止多个任务同时对可执行队列进行操作。
unsigned long nr_uninterruptible;//处于不可中断睡眠状态的任务数目
struct task_struct *curr;//CPU当前运行的任务指针
struct prio_array *active;//活动优先级数组
struct prio_array *expired;//超时(过期)优先级数组
};有一组宏定义用于获取与给定处理器或进程相关的可执行队列。
cpu_rq(processor)用于返回给定处理器可执行队列的指针。this_rq()宏用来返回当前处理器的可执行队列。最后,宏task_rq(task)返回给定任务所在的处理器的可执行队列指针。在对可执行队列进行操作之前,先锁住它。需要用到task_rq_lock()和task_rp_unlock()函数:
//例1
struct runqueue *rq;
unsigned long flags;
//上锁
rq = task_rq_lock(task, &flags);
//对rq的操作代码...
//开锁
task_rq_unlock(rq, &flags);
//例2
struct runqueue *rq1;
//上锁
rq1 = this_rq_lock();
//操作代码...
rq_unlock(rq1);可执行队列结构中,活动数组内的可执行队列上的进程都还有时间片剩余,而过期数组内的可执行队列上的进程都耗尽了时间片。当一个进程的时间片艳尽时,它会被移至过期数组,但在此之前,已经给它重新计算好了新的时间片。当活动数组为空的时候,交换活动数组和过期数组的指针值,这样就完成了时间片的重分配过程。因为数组是通过指针进行访问的,所以交换它们用的时间就是交换指针需要的时间。这个动作由schedule()完成:
struct prio_array *array = rq->active;
if(!array->nr_active){
rq->active = rq->expired;
rq->expired = array;
}这种交换时实现O(1)级调度程序的核心。
返回宿主:list_entry
作用:使用list_entry()宏,返回linux链表中链表结点的宿主。
原理为指针ptr指向结构体type中的成员member;通过指针ptr,返回结构体type的基地址。
//../include/linux/list.h
/* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.*/
#define list_entry(ptr, type, member) \
((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member))) 解释:
1.&((type *)0)->member:
把0强制转化为指针类型,即0是一个地址,为段基址。取以0为结构体基址的结构体的域变量member的地址,那么这个地址就等于member域到结构体基地址的偏移字节数。
2.((unsigned long) &((type *)0)->member):
把0地址转化为type结构的指针,然后获取该结构中member成员的指针,并将其强制转换为unsigned long类型,得到member域到type基地址的偏移字节数。
3.((type *)((char *)(ptr) - (unsigned long)(&((type *)0)->member))):
ptr是指向类型为type的结构体实例中的成员member的指针,(char*)(ptr)将指针ptr的按char*来解释,使得对ptr的加减操作都是按字节移动,减去该member在结构体中的字节偏移量,即得到这个type结构体的实例的起始地址。
next = list_entry(queue->next, struct task_struct, run_list)经过预处理器的解释就变成了((struct task_struct *)((char *)(queue->next) - (unsigned long)(&((struct task_struct *)0)->run_list)))这行代码的作用是:计算queue->next所在的struct task_struct容器的起始地址。为了帮助理解,设有如下结构体定义:
typedef struct xxx
{
……(结构体中其他域)
type1 member;
……(结构体中其他域)
}type;
定义变量:
type a;
type * b;
type1 * ptr;
执行:
ptr=&(a.member);
b=list_entry(ptr,type,member);
则可使b指向a,得到了a的地址。
//因为这种结构比较常见,所以在../include/kernel.h中专门定义了一个container_of宏。
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
//../include/kernel.h
#define container_of(ptr, type, member) ({ \
const typeof( ((type *)0)->member ) *__mptr = (ptr); \ (type *)( (char *)__mptr - offsetof(type,member) );}) //ptr有一个地址值,指向一个type类型实例的member成员变量,通过ptr的地址值减去偏移offsetof(type,member), //可以得到这个type实例的基地址,然后强制转换指针类型。 //../include/linux/stddef.h #define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) //type的基地址 和 member成员 的相对地址空间距离循环锁链:struct list_head
struct list_head{
struct list_head *next, *prev;
}这里链表初看起来比较奇怪,但是联系到上面提到的list_entry(ptr, type, member) 宏,才发现这个结构的精妙之处,它就像一条细细的链条,不包含任何冗余的东西,完全只是用来将包含它的容器(宿主)和其他的宿主容器链接起来。包含struct list_head结构的容器叫做宿主。task_struct就是一个宿主。
以后就可以这么理解:所有对list_head结构的操作都“等同于”对宿主的操作。可以把所有类似这种结构的结构体的双向队列抽象成一条锁链环。对于环上的结点的宿主,用宏定义:
list_entry(ptr, type, member)获取。示意图:
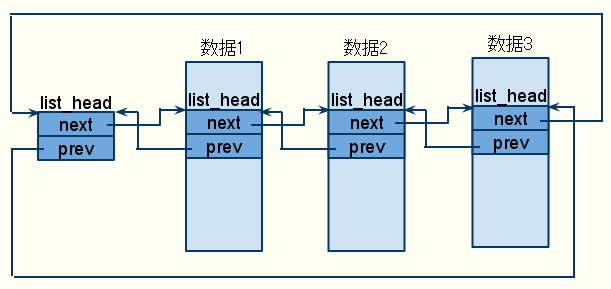
为什么要内嵌一个list_head结构:通用性。
也可以说这是c向面向对象做出的一个努力,在大系统设计中,可能需要管理各种类型的数据结构的队列,如果不用这种内嵌的方式,就得为每一个不同的数据结构都写一个链表类的操作函数的集合,而使用这种结构,就将链表作为一个接口抽象出来了。对这个链表的操作函数和宏参见【深入理解Linux内核】中文第3版93页。源代码参见
../include/linux /list.h
添加
list_add(struct list_head *new, struct list_head *head) :
将指针new指向的结点插入到指针head所指向的结点的后面。这就间接地把new的宿主添加到了head的宿主所在的双向循环链表之中。
//../include/linux/list.h
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}示意图:

list_add_tail(struct list_head *new, struct list_head *head)将new插入到head结点之前
//../include/linux/list.h
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}示意图:(注意,图中head和tail结点之间的指针标注有误,正好将next和prev给弄反了)

遍历
list_for_each(pos, head)用pos对表头地址head指定的链表进行遍历,其实在经过预处理器翻译后,它就成了一个不带循环体的for循环,使用这个宏的时候,需要给它加上循环体。
//../include/linux/list.h
#define list_for_each(pos, head) \
for (pos = (head)->next; prefetch(pos->next), pos != (head); \
pos = pos->next)
//这种宏是不是让人联想到了STL中迭代器的性质。
//给了迭代过程,剩下的操作语句(或操作函数)自己写。小插曲:用
prefetch(address)提高内存访问速度
参考 数据预取 __builtin_prefetch()
prefetch(address)的定义在../include/linux/prefetch.h中,其功能是对地址address的数据的预先读取,prefetch的一个单元常常是一个cacheline的大小。当你需要继续读取地址address的数据的时候,可以采用prefetch将这一块数据读取到cache之中,以便快速访问。
list_for_each(pos, head)
使用举例:
struct task_struct *task;
struct list_head *list;
list_for_each(list,¤t->chilidren)//循环条件
{//加上循环体
//利用list进行一些操作
task = list_entry(list, struct task_struct, sibling);/*task指向当前的某个子进程*/
}判空
list_empty(const struct list_head *head)判断链表是否为空
//../include/linux/list.h
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}还有几个函数就懒得写了…
进程描述符链表

进程链表把所有进程的进程描述符链表链接起来,一种方式是利用寄宿于每个task_struct结构中的list_head类型的tasks字段组成的双向循环链表将所有的进程的进程描述符(宿主)链接起来。
进程链表的表头是init_task描述符,它是所谓的0进程(process 0)的进程描述符(进程0的描述符init_task定义在arch/arm/kernel/init_task.c中,由INT_TASK宏初始化),是所有其他进程的祖先,也称作idle进程或swapper进程,是在系统初始化时由kernel自身从无到有创建。
如图:

for_each_process(p)用p来遍历整个进程链表。
//../include/linux/sched.h
#define next_task(p) \
list_entry_rcu((p)->tasks.next, struct task_struct, tasks) //利用list_head链表进行PCB的遍历 #define for_each_process(p) \ for (p = &init_task ; (p = next_task(p)) != &init_task ; )TASK_RUNNING状态的进程链表
当内核要调度一个进程投入CPU上运行时,只会从处于可运行状态的进程中选择优先级最高的一个。
为了提高调度程序运行速度,建立了多个可运行进程链表,每种进程优先权对应一个不同的链表。这是一个以空间代价换取时间的典型做法,在早期的Linux版本中,内核只维护一个可运行进程链表,在内存十分紧张的情况下,这种做法是可取的。(为什么对进程的PCB的组织用队列这种结构实现而不用树来实现呢,考虑用堆实现的优先队列的树结构,在调度的时候能实现O(1)的操作,但是要维护这样的结构,例如删除一个PCB,增加一个PCB就需要O(logN)的操作,这样的开销是比较大的。现在反倒成了队列能够提高操作的效率,这有点让人不敢相信,当然,如果只用一个毫无组织的队列,这是提高不了操作效率的,因为每种算法都得是O(n)级的,例如在调度时,调得度算法得在整个队列中寻找优先级最大的PCB。后面会看到,对PCB精心组织成队列后,算法的复杂度能降到O(1)。)
task_struct描述符中的run_list字段将所有优先级一样的处于可运行状态的进程的PCB链接了起来,这样,当知道链表中的任意一个list_head结点时,就可以遍历这个链表。
内核为管理可运行队列,专门定义了一个运行队列结构runqueue,runqueue中有类型为prio_array的数据结构指针,专门用来组织各个优先级对应的PCB链表。
enqueue_task(p,array)函数把进程描述符p插入到对应优先级为p->prio的运行队列中。
//../kernel/sched.c
其代码本质上等同于:
list_add_tail(&p->run_list, &array->queue[p->prio]);
_set_bit(p->prio,array->bitmap);
array->nr_active++;
p->array = array;类似的
dequeue_task(p,array)函数从运行队列中删除一个进程的描述符。
4个哈希表
有些情况需要从PID得到相应的进程描述符指针,比如kill()系统调用。由于顺序扫描进程链表并检查进程描述符的pid字段是比较低效的,因此引入了4种类型的哈希表分别对应进程描述符中的4种ID:
//../include/linux/pid.h
enum pid_type
{
PIDTYPE_PID, //对应进程的PID
PIDTYPE_TGID, //对应线程组领头进程的PID
PIDTYPE_PGID, //对应进程组领头进程的PID
PIDTYPE_SID //对应会话领头进程的PID
};内核定义了4个全局的hash表,分别对应pid_type中的4种类型:
static struct hlist_head *pid_hash[PIDTYPE_MAX];//../kernel/pid.c
这4个hash表由内核在初始化的时候动态地分配空间。

hash桶的结点的数据结构
//../include/linux/list.h
//hash桶的头结点
struct hlist_head {
struct hlist_node *first;//指向每一个hash桶的第一个结点的指针
};
//hash桶的普通结点
struct hlist_node {
struct hlist_node *next;//指向下一个结点的指针
struct hlist_node **pprev;//指向上一个结点的next指针的地址,下面会解释为什么要用一个二级指针。
};这些点的宿主是进程的PCB,所以对这些点的操作等价于对PCB的操作,找到了这些点,也就找到了宿主。所以接下来的任务就是将这些点散列到对应的桶。
示意图:

pid结构
//../include/linux/pid.h
struct pid
{
/* Try to keep pid_chain in the same cacheline as nr for find_pid */
int nr;//xid值,用来计算散列值,找到散列入口。
struct hlist_node pid_chain;//对于同一类型的ID,如果其值不相同,而又有同样的散列值,这时
//就出现了散列冲突,需要维持一个开放的链表,又名开散列。
/* list of pids with the same nr, only one of them is in the hash */
struct list_head pid_list;//对于属于同一个进程组的进程,或属于同一个线程组的进程,它们的组
//ID是一样的,所以尽管PID不同,它们在对组ID进行计算时得到的散列值是一样的,这时需要为这些进程
//维持一个双向链表。注意,链表中只把`代表PCB`看做被散列的PCB,其他的PCB被当作未散列的PCB。
//(这里说的散列是相对于pid_type的散列)。例如,在用(id,pid_type)查找id对应的PCB时,会返回`代表PCB`,
//一旦有了这个代表PCB,就可以通过它的pid.pid_list字段对同组进程遍历。
//pid_chain和pid_list的差别在:
//pid_chain是散列冲突链表。也就是说nr不同,散列结果相同。
//pid_list是同组进程链表。它们的nr相同,散列结果自然相同,但这并不是散列冲突。
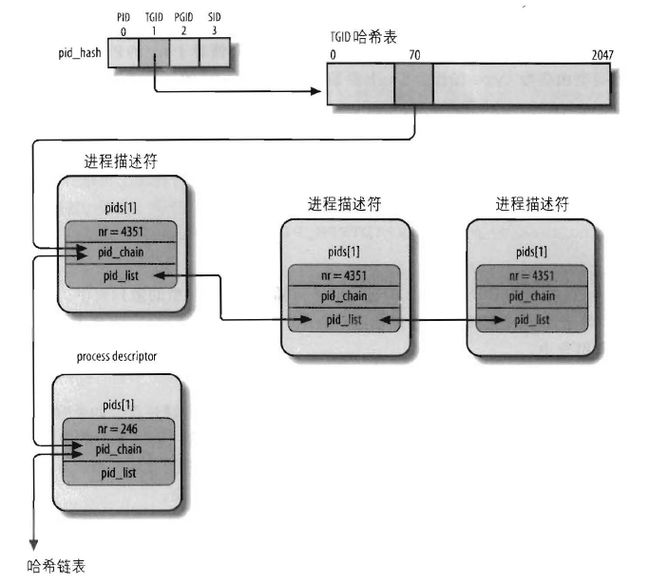
};图示:pid类型相同,nr值不同,但hash(nr)值相同,就用pid_chain开散列,pid类型相同,nr相同,例如,属于同一组的进程,用pid_list链接成一个双向链表。
为什么要用一个二级指针pprev:
散列数组中存放的是hlist_head结构体的指针。hlist_head结构体只有一个域,即first。 first指针指向一个hlist_node的双向链表中的一个结点(因为是双向链表,所以不用考虑谁是第一的问题)。
hlist_node结构体有两个域,next 和pprev。 next指针指向下个hlist_node结点,倘若该节点是链表的最后一个节点,next指向NULL。
pprev是一个二级指针, 它指向前一个节点的next指针的地址。显然,如果hlist_node采用传统的next,prev指针(一级指针),对于第一个节点和后面其他节点的处理会不一致。hlist_node巧妙地用pprev指向上一个节点的next指针的地址,由于hlist_head的first域和hlist_node的next域的类型都是hlist_node *,这样就解决了通用性问题!之于为什么不全部用hlist_node而非要定义一个专门的只含有一个hlist_node * 域的hlist_head结构体,答案当然是节省内存,而且还不失通用与优雅性。Linux链表设计者认为双头(next、prev)的双链表对于HASH表来说”过于浪费”,因而另行设计了一套用于HASH表应用的hlist数据结构–单指针表头双循环链表,hlist的表头仅有一个指向首节点的指针,而没有指向尾节点的指针,这样在HASH表中存储的表头就能减少一半的空间消耗。
参考标准C的标记化结构初始化语法
//hlist中常用的几个宏:
//在对hlist_head结点的初始化中会用到。
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
//在对hlist_node的初始化中会用到。
#define INIT_HLIST_NODE(ptr) ((ptr)->next = NULL, (ptr)->pprev = NULL)
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)//返回ptr的宿主
//从head开始遍历
#define hlist_for_each(pos, head) \
for (pos = (head)->first; pos && ({ prefetch(pos->next); 1; }); \
pos = pos->next)
//从head开始遍历宿主
#define hlist_for_each_entry(tpos, pos, head, member) \
for (pos = (head)->first; \
pos && ({ prefetch(pos->next); 1;}) && \
({ tpos = hlist_entry(pos, typeof(*tpos), member); 1;}); \
pos = pos->next)
操作散列链表的相关函数:
hlist_del(struct hlist_node *n)
//../include/linux/list.h
#define LIST_POISON1 ((void *) 0x00100100)
#define LIST_POISON2 ((void *) 0x00200200)
//对链表上所有hlist_node结点的删除一视同仁。
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
*pprev = next;
if (next)
next->pprev = pprev;
}
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);
//指针指向了LIST_POSION,表示不可使用的地方
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}hlist_add_x(struct hlist_node *n, struct hlist_node *next)
//../include/linux/list.h
/* next must be != NULL */
static inline void hlist_add_before(struct hlist_node *n,
struct hlist_node *next)
{
//n是待插入结点
//先调整插入结点n的指向。
n->pprev = next->pprev;
n->next = next;
//调整n结点后面结点的指向
next->pprev = &n->next;
//调整n结点前面的结点的指向
*(n->pprev) = n;
}
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
//n是待插入结点
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
/*其实这里完全可以用hlist_add_before内联函数实现,反正都写好了,还是 内联的,不会影响效率: if(h->first) hlist_add_before(n, h->first); else { n->next = first; h->first = n; n->pprev = &h->first; } 这样写应该是没有问题的,但是代码量没有减少,效率也没有提高。 */
}
static inline void hlist_add_after(struct hlist_node *n,
struct hlist_node *next)
{
//next是待插入结点
next->next = n->next;
n->next = next;
next->pprev = &n->next;
if(next->next)
next->next->pprev = &next->next;
}根据pid找PCB:find_pid&pid_task
求索引
用
pid_hashfn宏可以把pid转化为表索引:
#define pid_hashfn(pid) hash_long((unsigned long)pid, pidhash_shift)
//../kernel/pid.c
#define pid_hashfn(nr) hash_long((unsigned long)nr, pidhash_shift)
//../include/linux/hash.h
//计算val的hash值,其中bits是保留的高位的位数,也就是索引长度。0~2^bits-1, 在32位cpu中,bits=11,散列表的长度为2^11 = 2048
static inline unsigned long hash_long(unsigned long val, unsigned int bits)
{
unsigned long hash = val;
#if BITS_PER_LONG == 64
/* Sigh, gcc can't optimise this alone like it does for 32 bits. */
unsigned long n = hash;
n <<= 18;
hash -= n;
n <<= 33;
hash -= n;
n <<= 3;
hash += n;
n <<= 3;
hash -= n;
n <<= 4;
hash += n;
n <<= 2;
hash += n;
#else
/* On some cpus multiply is faster, on others gcc will do shifts */
hash *= GOLDEN_RATIO_PRIME;
#endif
/* High bits are more random, so use them. */
return hash >> (BITS_PER_LONG - bits);
}
为了防止出现哈希运算带来的冲突,Linux采用拉链法来解决,即引入具有链表的哈希表来处理。
find_pid
find_pid(enum pid_type type, int nr)
在存放type类型PID的散列表(pid_chain)中找XPID值为nr的pid结构,并返回。
//../kernel/pid.c
struct pid * fastcall find_pid(enum pid_type type, int nr)
{
struct hlist_node *elem;
struct pid *pid;
//其中elem 和 &pid_hash[type][pid_hashfn(nr)]用来遍历链表
//pid 和 pid_chain 用来计算成员pid_chain的相对偏移。
hlist_for_each_entry(pid, elem,
&pid_hash[type][pid_hashfn(nr)], pid_chain) {
if (pid->nr == nr)
return pid;
}
return NULL;
}pid_task
pid_task(elem, type)
返回pid_list链表第一个结点的宿主。
//../include/linux/pid.h
//elem是pid_list*类型的。
//这个宏用elem的地址值和它在PCB中的字段pids[type].pid_list与PCB的基地址的相对偏移相减得到PCB的基地址。
#define pid_task(elem, type) \
list_entry(elem, struct task_struct, pids[type].pid_list)
find_task_by_pid_type(int type, int nr)
//../kernel/pid.c
//type为链表类型,task为进程描述符。
task_t *find_task_by_pid_type(int type, int nr)
{
struct pid *pid;
pid = find_pid(type, nr);
if (!pid)
return NULL;
//在pid_list链表中选择第一个PCB
return pid_task(&pid->pid_list, type);
}hlist_unhashed(const struct hlist_node *h)
static inline int hlist_unhashed(const struct hlist_node *h)
{
return !h->pprev;
}
//用来判断h是否已被散列。define do_each_task_pid(who, type, task)
while_each_task_pid(who, type, task)
遍历pid_list链表。从后面的attach_pid(task,type,nr)函数可以看到,pid_list链表中只有一个代表PCB被散列了,组内的其它进程都未被散列。
//../include/linux/pid.h
//一个do-while循环,使用时需要两个宏结合起来,其间加上操作。
/*
do_each_task_pid(who, type, task)
//对task的操作...
while_each_task_pid(who, type, task)
*/
#define do_each_task_pid(who, type, task) \
if ((task = find_task_by_pid_type(type, who))) { \
prefetch((task)->pids[type].pid_list.next); \
do {
#define while_each_task_pid(who, type, task) \
} while (task = pid_task((task)->pids[type].pid_list.next,\
type), \
prefetch((task)->pids[type].pid_list.next), \
hlist_unhashed(&(task)->pids[type].pid_chain)); \
}
//循环条件是遍历到的PCB还未被散列。attach_pid
attach_pid(task,type,nr)
将一个PCB按类型type散列。
//../include/sched.h
//typedef struct task_struct task_t;
//../kernel/pid.c
//其中nr为PID,type为链表类型,task为进程描述符。
int fastcall attach_pid(task_t *task, enum pid_type type, int nr)
{
struct pid *pid, *task_pid;
task_pid = &task->pids[type];
pid = find_pid(type, nr);
if (pid == NULL) {
//散列表中没有,加入到对应的pid_chain中
hlist_add_head(&task_pid->pid_chain,
&pid_hash[type][pid_hashfn(nr)]);
//初始化pid_list字段
INIT_LIST_HEAD(&task_pid->pid_list);
} else {//散列表中已存在PCB所在的组中的一个进程
//初始化pid_chain字段
INIT_HLIST_NODE(&task_pid->pid_chain);
//将PCB加入到同组PCB链表中
list_add_tail(&task_pid->pid_list, &pid->pid_list);
}
task_pid->nr = nr;
return 0;
}在type类型的散列表中插入一个task指向的PID等于nr的进程描述符。如果一个PID等于nr的进程描述符已经在散列表中,这个函数就只把task插入已有的PID进程链表中(pid_list)。
完结示例
下面的代码用来选择当前最高优先级的进程
struct task_struct *prev, *next;
struct list_head *queue;
struct prio_array *array;
int idx;
prev = current;
array = rq->active;
idx = sched_find_first_bit(array->bitmap);
queue = array->queue +idx;
next = list_entry(queue->next, struct task_struct, run_list);
//run_list在task_struct结构体中定义,运行队列就是由这个字段组织起来的,其类型为
//struct list_head。