hadoop2.6上部署spark
注:本文中的操作都是在虚拟机中进行的
Hadoop2.6的安装可以看之前的文章,这里就不再赘述 http://blog.csdn.net/yuzhuzhong/article/details/50000307
相对于前文所建的Hadoop集群这里有了一些简单的变化。在安装eclipse的时候、还有在哪儿我也忘了的一个地方都提示JDk版本低了,为了防止以后使用的时候JDK出现问题我将JDK重装上最新的1.8.0_65版本,同时增加了一个节点Slave2。现在Hadoop集群为
Master 192.168.9.131
Slave1 192.168.9.133
Slave2 192.168.9.134
一、准备
本次将使用到两个软件scala-2.11.7.tgz和spark-1.5.2-bin-hadoop2.6.tgz
http://www.scala-lang.org/download 这里可以下载各个版本的scala
http://spark.apache.org/downloads.html 这里下载各个版本的spark
二、scala安装配置
1、因为安装包内有文件夹我就没有新建了,将桌面上安装包/复制到/usr 目录下直接解压的
../Desktop$ sudo cp scala-2.11.7.tgz /usr
../usr$ sudo tar zxvf scala-2.11.7.tgz

2、添加环境变量
vim ~/.bashrc
打开后在文件的最下方添加export SCALA_HOME=/usr/scala-2.11.7
export PATH=$PATH:$SCALA_HOME/bin
![]()
source ~/.bashrc
3、验证scala -version
![]()
这样在Master上的安装就完成了
scp ~/.bashrc [email protected]:~/.bashrc
scp ~/.bashrc [email protected]:~/.bashrc
三、spark的安装配置
1、和scala安装一样直接在/usr目录下解压
../Desktop$ sudo cp spark-1.5.2-bin-hadoop2.6.tgz /usr
../usr$ sudo tar zxvf spark-1.5.2-bin-hadoop2.6.tgz
文件夹名字太长我给它改成spark152-hadoop26
sudo mv spark-1.5.2-bin-hadoop2.6 spark152-hadoop26
修改文件夹权限:sudo chown -hR zhong /usr/spark152-hadoop26/ 否则开启集群的时候可能出现问题
2、设置环境变量vim ~/.bashrc
打开文件后在最后添加export SPARK_HOME=/usr/spark152-hadoop26
export PATH=$PATH:$SPARK_HOME/bin
保存退出,source命令使 之生效
source ~/.bashrc
3、修改spark的conf目录下spark-env.sh文件(一下命令都是在conf目录下)conf只有spark-env.sh.templat文件,需先将其改为spark-env.sh
..conf$ sudo cp spark-env.sh.template spark-env.sh
vim spark-env.sh 打开spark-env.sh文件在最后添加
export JAVA_HOME=/usr/lib/java/jdk1.8.0_65 ###jdk安装目录
export SCALA_HOME=/usr/scala-2.11.7 ###scala安装目录
export SPARK_MASTER_IP=192.168.9.131 ###spark集群的master节点的ip
export SPARK_WORKER_MEMORY=2g ###指定的worker节点能够最大分配给Excutors的内存大小
export HADOOP_CONF_DIR=/usr/hadoop/hadoop-2.6.1/etc/hadoop ###hadoop集群的配置文件目录

source spark-env.sh 使之生效
注:设置环境变量时,直接复制过去的如果出现问题可以删除出问题的那个改成手打的。
修改conf目录下面的slaves文件将worker节点都加进去
sudo cp slaves.template slaves
vim slaves
4、在slave节点上同样安装spark(可以直接复制过去)
四、开启及验证
首先开启Hadoop集群,进入spark根目录(/usr/spark152-hadoop26)执行sbin/start-all.sh命令启动spark集群。
成功启动后用jps命令查看,Master节点上

slave节点上

可直接访问http://ip:8080查看spark的web界面
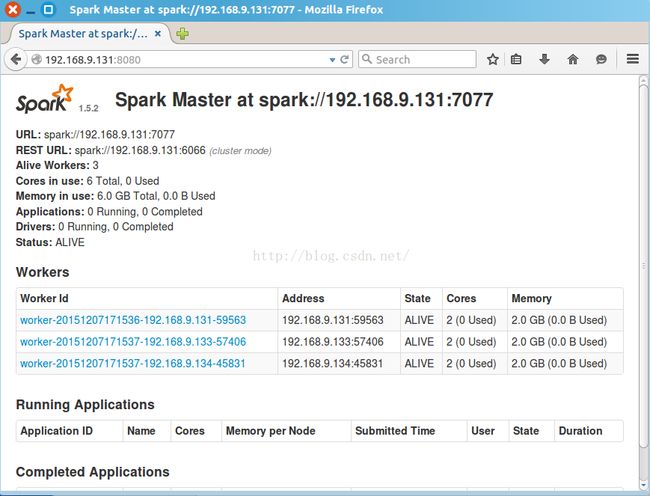
参考:http://my.oschina.net/sucre/blog/360286?fromerr=WaYVc6mZ
http://blog.csdn.net/jiangkai_nju/article/details/7338177