C++实现动态哈希,包括插入删除。并将结果写入到文件中。
之前学数据库管理系统,一个课程实验里面的一部分。
在这个动态哈希之前写了两个版本,一个静态哈希,一个想写动态哈希结果写成了B树,囧。。。
最近写的这个版本,主要实现了从一个文件中读取一系列整数,使用动态哈希的方法插入到『桶』中。并且,设计了数据结构,将『桶』里的信息和数据写到文件中。
动态哈希有挺多blog介绍的,这里就不多介绍了。
看完原理,自己动手写一下才能更好的理解这一原理。而且,这也是一个挺有意思的散列解决方案,无愧于『动态』这两个字。
自动动手设计、实现文件结构还是一件蛮有意思的事情。
我设计了两个文件来记录『桶』中的信息,一个是头结点文件,一个是用于存储结点数据的文件。这样两个文件中的结构体都相对独立,增删都比较容易。
数据结构如下:
#define bucketSize 10//bucket capcity
#define splitPoint 0//waiting for spliting,这个就是待分裂指针开始指向的位置。
#define iniListSize 2//initialize the bucket number
//Structure area
//define information structure of the external file
typedef struct{
int split_point;//waiting for split
int entry;//entries number
int m_bucketMaxCapacity;
int m_currentLevel;//know the max of split point
//int m_currentMaxBucketsBeforeSplit;
//int m_nextBucketIndexToSplit;
}Information;
//define the struct for bucket
typedef struct{
int head_pos;//the first node's position
int tail_pos;//the last node's position,
}H_bucket;
//define the record node, this is extendable for modification
typedef struct{
int pos;//the position of this record in the database
int value;// the value form the data files
}H_record;
//define the node struct
typedef struct{
int parent;//define the position of the node behind
int next;//define the position of the node next to it. If there is no node followed, then next == 0
H_record record;
}H_node;
首先在存储结构信息的index文件中,写入一个Information结点,记录现有数据库的信息,包括:待分裂结点的序号、DB中的数据条数、桶的个数和当前分裂层次。然后,在后面依次写入存储着桶结点。每一个桶结点保存了该桶中数据结点在数据存储文件中的头结点和尾结点的位置。我用在文件中的绝对位置作为指针。
也就是说,index文件中,存了一个Information结点和若干个H_bucket结点。数据文件中就只有H_node结点。同时为了方便以后扩展,用H_record结构体来保存数据。
插入数据之前,先把存数据的文件初始化:
void initialize(FILE* head)
{
Information infor;
H_bucket hbuc;
infor.entry = 0;
infor.m_bucketMaxCapacity = 2;
infor.m_currentLevel = 1;
infor.split_point = 0;
//information node
rewind(head);
fwrite(&infor, 1, sizeof(Information), head);
hbuc.head_pos = hbuc.tail_pos = -1;
hbuc.count = 0;
//first two buckets
fwrite(&hbuc, 1, sizeof(H_bucket), head);
fwrite(&hbuc, 1, sizeof(H_bucket), head);
}
插入数据的时候,主要是要注意以下几个方面
depth:当前的分裂层次
work_pointer:待分裂指针
value:待插入的数据。这次实验的所有数据都正数。
插入代码如下:
void insert(FILE* head, FILE* index, int value)//insert function
{
//bool split = false;//do or not need to be split
rewind(head);
Information infor;
fread(&infor, 1, sizeof(Information), head);
int key = hashFunction(value, infor.m_currentLevel);
if (key<infor.split_point)
{
key = hashFunction(value, infor.m_currentLevel + 1);
}
//insert
//define the variation
H_bucket hbuc;
H_node hnode, hnode_temp;
hnode.record.value = value;
hnode.next = hnode.parent = -1;
//fine the bucket position
fseek(head, sizeof(Information) + key*sizeof(H_bucket), SEEK_SET);
int pos_buc = ftell(head);
//read the bucket
fread(&hbuc, 1, sizeof(H_bucket), head);
//write into the bucket
fseek(index, 0, SEEK_END);
int pos = ftell(index);
//int pos = findPosition(index);//iteration for first blank position
if (hbuc.head_pos==-1)
{
hnode.next = hbuc.head_pos;
hnode.parent = pos_buc;
hbuc.head_pos = pos;
}else
{
hnode.next = hbuc.head_pos;
fseek(index, hnode.next, SEEK_SET);
fread(&hnode_temp, 1, sizeof(H_node), index);
hnode_temp.parent = pos;
fseek(index, -sizeof(H_node), SEEK_CUR);
fwrite(&hnode_temp, 1, sizeof(hnode_temp), index);
hbuc.head_pos = pos;
hnode.parent = pos_buc;
}
fseek(index, pos, SEEK_SET);
fwrite(&hnode, 1, sizeof(H_node), index);
hbuc.count++;
infor.entry++;
rewind(head);
fwrite(&infor, 1, sizeof(Information), head);
fseek(head, pos_buc, SEEK_SET);
fwrite(&hbuc, 1, sizeof(H_bucket), head);
//if split
if (hbuc.count>bucketSize)
{
//test
//printf("current count: %d\n",hbuc.count);
splitHash(head, index);
}
rewind(head);
fread(&infor, 1, sizeof(Information), head);
printf("1 current level: %d\n", infor.m_currentLevel);
}
分裂时候,要把分裂的桶中的数据重新分配到两个桶中:
void splitHash(FILE* head, FILE* index)
{
//find the bucket to be split
H_bucket hbuc;
Information infor;
rewind(head);
fread(&infor, 1, sizeof(Information), head);
//add a new bucket
hbuc.count = 0;
hbuc.head_pos = hbuc.tail_pos = -1;
fseek(head, 0, SEEK_END);
fwrite(&hbuc, 1, sizeof(H_bucket), head);
//modify the information
infor.split_point++;
int next_split = infor.split_point;
infor.m_bucketMaxCapacity++;
fseek(head, 0, SEEK_SET);
fwrite(&infor, 1, sizeof(Information), head);
//reinsert
//fseek(head, sizeof(Information) + infor.split_point*sizeof(H_bucket), SEEK_SET);
//fread(&hbuc, 1, sizeof(H_bucket), head);
//modify one bucket
splitInsert(head, index, next_split);
//fread(&hbuc, 1, infor.split_point*sizeof(H_bucket), head);
//modify the information
rewind(head);
fread(&infor, 1, sizeof(Information), head);
if (infor.split_point>=topLevel(infor.m_currentLevel))
{
infor.split_point = 0;
printf("2 current level: %d\n", infor.m_currentLevel);
infor.m_currentLevel++;
}
fseek(head, 0, SEEK_SET);
fwrite(&infor, 1, sizeof(Information), head);
}
void splitInsert(FILE* head, FILE* index, int next_split)
{
Information infor;
H_bucket hbuc, hbuc_new;
int buc_pos, new_pos;
rewind(head);
fread(&infor, 1, sizeof(Information), head);
fseek(head, sizeof(Information) + (next_split-1)*sizeof(H_bucket), SEEK_SET);
buc_pos = ftell(head);
fread(&hbuc, 1, sizeof(H_bucket), head);
fseek(head, -sizeof(H_bucket), SEEK_END);
new_pos = ftell(head);
fread(&hbuc_new, 1, sizeof(H_bucket), head);
//int key = hashFunction(hnode.record.value, infor.m_currentLevel + 1);
int count = hbuc.count;
int next = hbuc.head_pos;
for (int i=0,j=0;i<count;i++,j++)
{
H_node hnode, hnode_temp;
fseek(index, next, SEEK_SET);
fread(&hnode, 1, sizeof(H_node), index);
int new_next = hnode.next;//save
int key = hashFunction(hnode.record.value, infor.m_currentLevel + 1);
if (key>(next_split-1))
{
//delete
//parent
if (j==0)
{
j--;
hbuc.head_pos = hnode.next;
}
else
{
fseek(index, hnode.parent, SEEK_SET);
fread(&hnode_temp, 1, sizeof(H_node), index);
hnode_temp.next = hnode.next;
fseek(index, hnode.parent, SEEK_SET);
fwrite(&hnode_temp, 1, sizeof(H_node), index);
}
//next
if (hnode.next!=-1)
{
fseek(index, hnode.next, SEEK_SET);
fread(&hnode_temp, 1, sizeof(H_node), index);
hnode_temp.parent = hnode.parent;
fseek(index, hnode.next, SEEK_SET);
fwrite(&hnode_temp, 1, sizeof(H_node), index);
}
hbuc.count--;
//insert
hnode.next = hbuc_new.head_pos;
hnode.parent = new_pos;
if (hnode.next!=-1)
{
fseek(index, hnode.next, SEEK_SET);
fread(&hnode_temp, 1, sizeof(H_node), index);
hnode_temp.parent = next;
fseek(index, -sizeof(H_node), SEEK_CUR);
fwrite(&hnode_temp, 1, sizeof(hnode_temp), index);
}
hbuc_new.head_pos = next;
hbuc_new.count++;
fseek(index, next, SEEK_SET);
fwrite(&hnode, 1, sizeof(H_node), index);
}
next = new_next;
}
fseek(head, buc_pos, SEEK_SET);
fwrite(&hbuc, 1, sizeof(H_bucket), head);
fseek(head, new_pos, SEEK_SET);
fwrite(&hbuc_new, 1, sizeof(H_bucket), head);
}
删除
bool deleteNode(FILE* head, FILE* index, int value)
{
rewind(head);
Information infor;
fread(&infor, 1, sizeof(Information), head);
//test
printf("1current value: %d\n",value);
int pos = searchNode(head, index, &value);
printf("2 current value: %d\n",*&value);
if (pos>-1)
{
//rewind(index);
fseek(index, pos, SEEK_SET);
H_node hnode, hnode_temp;
fread(&hnode, 1, sizeof(H_node), index);
if (value==-1)//father node is bucket
{
fseek(head, hnode.parent, SEEK_SET);
H_bucket hbuc;
fread(&hbuc, 1, sizeof(H_bucket), head);
hbuc.head_pos = hnode.next;
fseek(head, hnode.parent, SEEK_SET);
fwrite(&hbuc, 1, sizeof(H_bucket), head);
}else
{
fseek(index, hnode.parent, SEEK_SET);
fread(&hnode_temp, 1, sizeof(H_node), index);
hnode_temp.next = hnode.next;
fseek(index, hnode.parent, SEEK_SET);
fwrite(&hnode_temp, 1, sizeof(H_node), index);
}
if (hnode.next>-1)//has next node
{
fseek(index, hnode.next, SEEK_SET);
fread(&hnode_temp, 1, sizeof(H_node), index);
hnode_temp.parent = hnode.parent;
fseek(index, hnode.next, SEEK_SET);
fwrite(&hnode_temp, 1, sizeof(H_node), index);
}
int key = hashFunction(hnode.record.value, infor.m_currentLevel);
if (key<infor.split_point)
{
key = hashFunction(hnode.record.value, infor.m_currentLevel + 1);
}
fseek(head, sizeof(Information) + key*sizeof(H_bucket), SEEK_SET);
H_bucket hbuc;
fread(&hbuc, 1, sizeof(H_bucket), head);
hbuc.count--;
fseek(head, sizeof(Information) + key*sizeof(H_bucket), SEEK_SET);
fwrite(&hbuc, 1, sizeof(H_bucket), head);
hnode.next = hnode.parent = -1;
fseek(index, pos, SEEK_SET);
fwrite(&hnode, 1, sizeof(H_node), index);
infor.entry--;
rewind(head);
fwrite(&infor, 1, sizeof(Information), head);
return true;
}
return false;
}
查找
int searchNode(FILE* head, FILE* index, int* valuep)
{
int pos = -1;
int flag = 0;
rewind(head);
Information infor;
fread(&infor, 1, sizeof(Information), head);
int key = hashFunction(*valuep, infor.m_currentLevel);
if (key<infor.split_point)
{
key = hashFunction(*valuep, infor.m_currentLevel + 1);
}
H_bucket hbuc;
//fine the bucket position
fseek(head, sizeof(Information) + key*sizeof(H_bucket), SEEK_SET);
fread(&hbuc, 1, sizeof(H_bucket), head);
int next = hbuc.head_pos;
while (next>-1)
{
flag ++;
H_node hnode;
fseek(index, next, SEEK_SET);
fread(&hnode, 1, sizeof(H_node), index);
if (hnode.record.value==*valuep)
{
pos = next;
break;
}
next = hnode.next;
}
if (flag == 1)
{
*valuep = -1;
}
return pos;
}
打印出结果
void print_hash(FILE* head, FILE* index)
{
FILE *fp;
H_bucket hbuc;
H_node hnode;
Information infor;
int next = -1;
if (!(fp=fopen("HashTableOutput","w")))
{
//fp=fopen("HashTableOutput","w");
printf("Create output file failed\n");
exit(0);
}
else
printf("Create output file succeed!\n");
rewind(head);
fread(&infor, 1, sizeof(Information), head);
//implementation
int i;
for (i=0; i<infor.m_bucketMaxCapacity; i++)
{
//print bucket
fseek(head, sizeof(Information) + i*sizeof(H_bucket), SEEK_SET);
fread(&hbuc, 1, sizeof(H_bucket), head);
next = hbuc.head_pos;
printf("bucket %d :", i);
fprintf(fp,"bucket %d :", i);
//rewind(index);
//fseek(index, hbuc.head_pos, SEEK_SET);
//fread(&hbuc, 1, sizeof(H_bucket), index);
//next = hbuc.head_pos;
//print chains
int bracket = 0;
while (next>-1)
{
if ((bracket%bucketSize)==0)
{
printf("[ ");
fprintf(fp,"[ ");
}
if ((bracket%bucketSize)==(bucketSize-1))
{
fseek(index, next, SEEK_SET);
fread(&hnode, 1, sizeof(H_node), index);
printf("%d ",hnode.record.value);
fprintf(fp,"%d ",hnode.record.value);
printf("]");
fprintf(fp,"]");
}else
{
fseek(index, next, SEEK_SET);
fread(&hnode, 1, sizeof(H_node), index);
printf("%d, ",hnode.record.value);
fprintf(fp,"%d, ",hnode.record.value);
}
bracket++;
next = hnode.next;
}
if (bracket%bucketSize!=0)
{
while ((bracket%bucketSize)!=(bucketSize-1))
{
printf("%d, ",-1);
fprintf(fp,"%d, ",-1);
bracket++;
}
printf("-1]");
fprintf(fp,"-1]");
}
printf("end\n");
//printf(" |\n");
//printf(" V\n");
printf(" %c\n",25);
fprintf(fp,"end\n");
//fprintf(fp,"%c\n",25);
fprintf(fp," |\n");
fprintf(fp," V\n");
}
printf(" end\n");
fprintf(fp," end\n");
fclose(fp);
rewind(head);
//Information infor;
fread(&infor, 1, sizeof(Information), head);
printf("current lever is : %d\n", infor.m_currentLevel);
printf("current split point is : %d\n", infor.split_point);
}
哈希函数如下:
int hashFunction( int value, int depth)//this is the hash function, depth is the work round
{
if ( value < 0 || depth < 0 )
return FAILURE;
if ( value == 0 || depth == 0 )
return 0;
int key = 0;
for ( depth-- ; depth >= 0 ; depth-- )
{
key <<= 1;
if ( value & (1 << depth) )//only lift the remain number : 00010000...
key++;
}
return key;
}
top level 值
int topLevel(int level)//the number for 2^level
{
int result = 1;
for ( level-- ; level >= 0 ; level-- )
{
result <<= 1;
}
return result;
}
总得来说,文件操作还是一件挺有助于理解数据存储的事情。它比内存操作更具体形象一点。
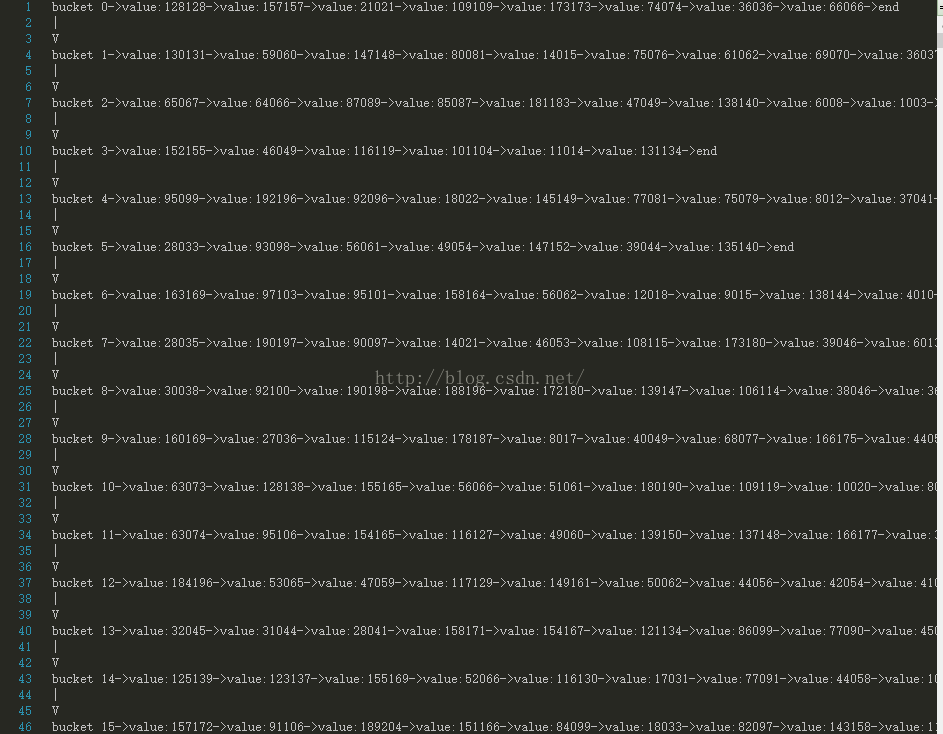
附插入数据后的打印效果图: