CUDA_by_Examples_Chapter5
Chapter5
前面出现的问题都是每个处理器都能独立无交互地执行就可以得到最终结果,但是事实上这种问题很少,这章就是介绍processor之间的communicate 和cooperate辣。
》》》Chapter objectives
- what CUDA C calls thread
- how different threads communicate with each other
- how to synchronize the parallel execution of different threads
thread是啥玩意儿这里就不说了……
一、Vector Sums again
还是那个vector sun,还是那个味,只是这回用thread来代替block解决之。
用thread和block现在还看不出有什么差别,但是parallel thread可以做parallel block做不到的事,这个暂且不谈。
首先看主函数中核函数的调用,用parallel block 时,调用核函数:
add <<<N, 1>>>(dev_a, dev_b, dev_c);现在我们用parallel thread:
add <<<1, N>>>(dev_a, dev_b, dev_c);<<<>>>中第一个参数表示一个grid中有多少block,第二个参数表示一个block中有多少thread,现在我们的意图是一个block,每个block N个thread来并行执行kernel code。
那么核函数中的int tid = blockIdx.x;也应该改成int tid = threadIdx.x;因为我们现在只有一个block,一个thread处理一个数,应该对thread做索引。
综上,只要改写两部分就可以将原来parallel block的代码改成parallel thread,下面是完整代码:
//懒得用book.h QAQ
#include <stdio.h>
#include "cuda_runtime.h"
#define N 1000
__global__ void
add(int *a, int *b, int *c){
int tid = threadIdx.x; //*************************
if(tid < N) c[tid] = a[tid] + b[tid];
}
int main(void){
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
//allocate memory on GPU
cudaMalloc((void**)&dev_a, N * sizeof(int));
cudaMalloc((void**)&dev_b, N * sizeof(int));
cudaMalloc((void**)&dev_c, N * sizeof(int));
//fill the array a & b on CPU
for(int i = 0; i < N; ++i){
a[i] = -i;
b[i] = i * i;
}
//copy the arrays a & b to GPU
cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_c, c, N * sizeof(int), cudaMemcpyHostToDevice);
add<<<1, N>>>(dev_a, dev_b, dev_c); //************************
//copy array c to CPU
cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost);
//display
for(int i = 0; i < N; ++i) printf("%d + %d = %d\n", a[i], b[i], c[i]);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
}然而呢,硬件限制了block的数量为65535,similarly,对threads per block也有所限制,这个第三章有讲到辣,就是cudaDeviceProp中的maxThreadsPerBlock成员,我的是1024。那么问题来了,如果我们要处理超过这个数量的vector求和,要怎么做呢?这时候就要双管齐下,block和thread一起上了!
代码的改写还是分上文中的两部分:
1.是数据的索引,看图
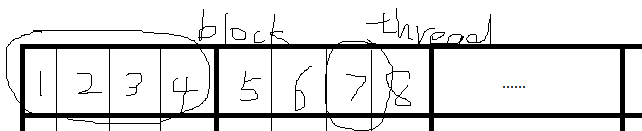
图中的数据就是线程的编号(grid中每个线程都有一个唯一的线程id)。故,我们改成:
int tid = threadIdx.x + blockIdx.x * blockDim.x;blockDim.x表示每个block在x方向有几个thread,blockIdx.x表示是grid中这个block的X方向上的编号,私以为这个图还是很明确的横向就是x方向辣…threadIdx.x则是block中这个thread的编号。(【上下文无关】这里,书上提到,grid可以有二维和一维的blocks,目前不能使用三维。block则可以接受三维thread)
2.现在来看<<<>>>中的参数,假定每个block中有128个thread,则直觉地认为需要N / 128个block,然而这是不对的,当N= 127时,就一个block都没有了……所以我们的代码应该是:
add<<<(N + 127) / 128, 128>>>(dev_a, dev_b, dev_c);这时,我们launch的线程就太多了orz…超过了下标,不过没关系,我们有
if(tid < N) c[tid] = a[tid] + b[tid];有一个判断!这样就不会对不该读写的内存进行改动了!
接下来说任意长度的vector的求和。
grid中block的数量每一维都不能超过65535,当N > 65535 * 128的时候,这个就不对了呀,我们的策略是,把代码改成这样:
__global__ void
add(int *a, int *b, int *c){
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while(tid < N){
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x;
}
}就是每个kernel处理多个元素,我觉得这个图画得还是很明确的,相同颜色表示在同一个thread中处理,这里简化一下,为<<<3, 3>>>.
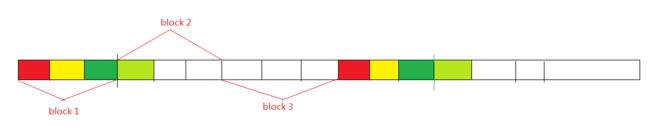
实际程序中原来是<<<(N + 127) / 128, 128>>>,其中第一个参数可能会超过限制,所以我们需要设置一个合理的不朝鲜的数值,eg:
add<<<128,128>>>( dev_a, dev_b, dev_c );这个数值的设定对程序性能会有影响,但是这里先不说了。(我很讨厌这种话说一半的感觉…………………………)
现在我们的程序处理数据的规模大小只受到GPU上RAM大小的限制。完整代码:
#include <stdio.h>
#include "cuda_runtime.h"
#define N 100
__global__ void
add(int *a, int *b, int *c){
int tid = threadIdx.x + blockIdx.x * blockDim.x;
while(tid < N){
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x; //**********
}
}
int main(void){
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);
printf("%d**\n", prop.maxThreadsPerBlock);
//allocate memory on GPU
cudaMalloc((void**)&dev_a, N * sizeof(int));
cudaMalloc((void**)&dev_b, N * sizeof(int));
cudaMalloc((void**)&dev_c, N * sizeof(int));
//fill the array a & b on CPU
for(int i = 0; i < N; ++i){
a[i] = -i;
b[i] = i * i;
}
//copy the arrays a & b to GPU
cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_c, c, N * sizeof(int), cudaMemcpyHostToDevice);
add<<<128, 128>>>(dev_a, dev_b, dev_c); //***********
//copy array c to CPU
cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost);
//display
for(int i = 0; i < N; ++i) printf("%d + %d = %d\n", a[i], b[i], c[i]);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
}二、GPU ripple using threads
虽然看起来很有趣的样子,还是动画呢,然后宝宝又开始担心会出什么幺蛾子QAQ
首先是整体框架:
#include "book.h"
#include "cuda_runtime.h"
#include "cpu_anim.h"
struct DataBlock{
unsigned char * dev_bitmap;
CPUAnimBitmap * bitmap;
};
void cleanup(DataBlock *d){
cudaFree(d->dev_bitmap);
}
int main(){
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
HANDLE_ERROR(cudaMalloc((void**)&data.dev_bitmap, bitmap.image_size()));
bitmap.anim_and_exit((void(*)(void*, int)) generate_frame, (void(*)(void*))cleanup);//传递函数指针
}main()函数中显示很熟悉的,在device上分配空间,然后就交给bitmap.anim_and_exit()去办了,传递给它两个函数指针,一个是generate_frame,另一个是释放设备空间的cleanup函数。
generate_frame函数在每次要生成动画的新的一帧的时候调用,以产生一幅新的图画。接下来来看看它:
void generate_fame(DataBlock *d, int ticks){
dim3 blocks(DIM/16,DIM/16);
dim3 thread(16,16);
kernel<<<blocks, thread>>>(d->dev_bitmap, ticks);
HANDLE_ERROR(cudaMemcpy(d->bitmap->get_ptr(),
d->dev_bitmap,
d->bitmap->image_size(),
cudaMemcpyDeviceToHost));
}我们在这个函数中调用kernel函数,声明了两个二维变量分别描述,下面这个图已经很明白了……
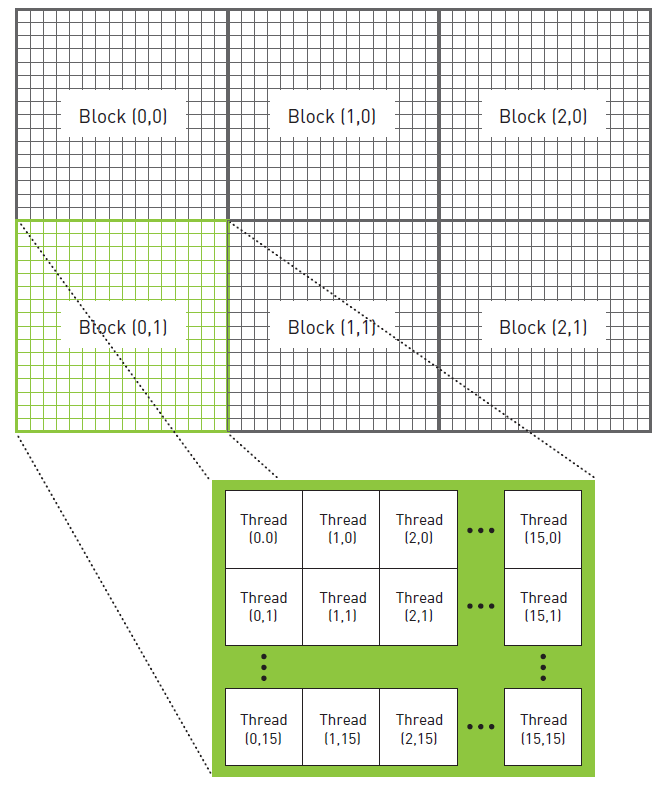
其中的kernel函数由两个参数,第二个参数ticks是时间。下面是kernel函数,x,y什么的,看上面的图,自己模拟一下就知道了,代码如下grey什么的不要太纠结了……
__global__ void kernel(unsigned char *ptr, int ticks){
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float fx = x - DIM / 2;
float fy = y - DIM / 2;
float d = sqrtf(fx * fx + fy * fy);
unsigned char grey = (unsigned char)(128.0f + 127.0f *
cos(d/10.0f - ticks/7.0f)/
(d/10.0f + 1.0f));
ptr[offset * 4 + 0] = grey;
ptr[offset * 4 + 1] = grey;
ptr[offset * 4 + 2] = grey;
ptr[offset * 4 + 3] = 255;
}result:

总算是安全地度过……
三、共享内存和同步
目前为止,我们split block into threads的目的仅是为了摆脱硬件的限制,但是这个不是主要的原因,接下来我们会体会到更重要的原因。
与shared Memory相关的关键字有_ _ devie _ _ , _ _ global _ , _ shared _ 。使用 _ shared _ _声明一个变量位于Shared M上。每个block都有一个shared M,block中每个thread都共享之(进行读写),但是blockA中的thread不能访问blockB中的shared M中的内容。总之,sharedM使得一个block中的thread可以communicate,并且使用sharedM可以大大降低延迟时间,提高运行效率。
但是thread之间的交互需要有同步机制(synchronize),否则会出现问题,比如threadA需要用到threadB的数据,但是threadB在threadA要用到这个数据的时候还没有准备好这个数据,然后就会出错,在接下来的实验中我们会看到这一点。
》》》DOT Product(求向量内积)
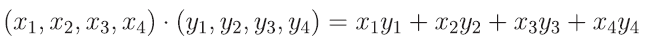
input:两个vector output:一个数
这个类似上文的vector sum,先给出kernel函数:
__global__ void
dot(float *a, float *b, float *c){
__shared__ float cache[threadPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while(tid < N){
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
...//看下文
}这个和vector sum中最终版差不多,一个thread中进行while循环,每个block分配大小与其中thread数相等的sharedM(cache),每个thread的结果写入cache中,然后将它们加起来,但是我们在把结果加起来之前需要保证所有的结果都已经写入,这是我们需要用到_ _syncthreads(),它能保证所有的线程都已经执行到这个函数后才能继续执行。
这里有一个很重要的思想——reduction(规约)
definition:the general process of taking an input array
and performing some computations that produce a smaller array of results。
就是把一个大的问题划成多个子问题 并行 解决之。看下图
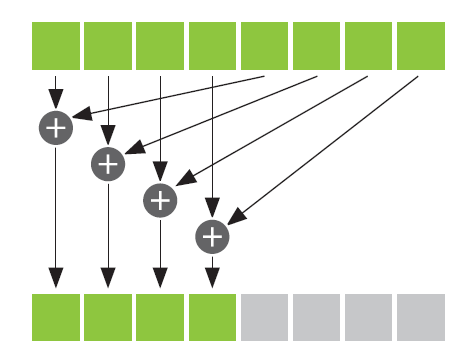
每个上面每个方块都是cache中的元素,每个加号都可以并行进行,处理的时间和元素的数量n是logn的关系,如果是串行的化,一个一个加起来很明显需要的时间和n成线性相关,比如8个元素求和,按照正常的串行思路,要循环7次,而并行处理的化,虽然仍要计算7次,但是其中的加法可以并行进行,以此来缩短计算的时间。
来看dot函数的下文:
__syncthreads();
int i = blockDim.x / 2;
while(i!= 0){ if(cacheIndex < i) cache[cacheIndex] += cache[cacheIndex + i]; __syncthreads(); i /= 2; }
if(cacheIndex == 0)
c[blockIdx.x] = cache[0];最后得到的数列c中的元素求和不用GPU,因为剩下的只有128个元素,这些数量相对于GPU的运算器来说太少了,不划算,因此剩下的步骤交给Host:
int main(void){
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
a = new float[N];
b = new float[N];
partial_c = new float[blockPerGrid];
//allocate memory
cudaMalloc((void**)&dev_a, N * sizeof(float));
cudaMalloc((void**)&dev_b, N * sizeof(float));
cudaMalloc((void**)&dev_partial_c, blockPerGrid* sizeof(float));
for(int i = 0; i < N; i++){
a[i] = i;
b[i] = i * i;
}
//copy
cudaMemcpy(dev_a, a, sizeof(float) * N, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, sizeof(float) * N, cudaMemcpyHostToDevice);
dot<<<blockPerGrid, threadPerBlock>>>(dev_a, dev_b, dev_partial_c);
...//待续
}下面是关于grid和block数量的设定:
#define imin(a, b) (a < b ? a : b)
const int N = 33 * 1024;
const int threadPerBlock = 256;
const int blockPerGrid =
imin(32, (N + threadPerBlock - 1) / threadPerBlock);blockPerGrid应该设定为对CPU足够大,而又能使得GPU足够忙碌的数量。
如果数据不够多就取最小的能装下所有元素的block数。这里我们又看到了熟悉的(N + threadPerBlock - 1) / threadPerBlock)这是一个很常见的技巧。
然后我们要将dev_partial_c中的数据加到c上,因为这个数组在device上,所以需要调用那个函数:
cudaMemcpy(partial_c,
dev_partial_c,
blockPerGrid * sizeof(float),
cudaMemcpyDeviceToHost);然后是最后的代码:
#include <stdio.h>
#include "cuda_runtime.h"
#include "cuda_device_runtime_api.h"
#define imin(a, b) (a < b ? a : b)
const int N = 33 * 1024;
const int threadPerBlock = 256;
const int blockPerGrid =
imin(32, (N + threadPerBlock - 1) / threadPerBlock);
__global__ void dot(float *a, float *b, float *c){
__shared__ float cache[threadPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while(tid < N){
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
__syncthreads();
int i = blockDim.x / 2;
while(i!= 0){
if(cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if(cacheIndex == 0)
c[blockIdx.x] = cache[0];
}
int main(void){
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
a = new float[N];
b = new float[N];
partial_c = new float[blockPerGrid];
//allocate memory
cudaMalloc((void**)&dev_a, N * sizeof(float));
cudaMalloc((void**)&dev_b, N * sizeof(float));
cudaMalloc((void**)&dev_partial_c, blockPerGrid* sizeof(float));
for(int i = 0; i < N; i++){
a[i] = i;
b[i] = i * 2;
}
//copy
cudaMemcpy(dev_a, a, sizeof(float) * N, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, sizeof(float) * N, cudaMemcpyHostToDevice);
dot<<<blockPerGrid, threadPerBlock>>>(dev_a, dev_b, dev_partial_c);
cudaMemcpy(partial_c,
dev_partial_c,
blockPerGrid * sizeof(float),
cudaMemcpyDeviceToHost);
c = 0;
for(int i = 0; i < blockPerGrid; ++i)
c += partial_c[i];
#define sum_squares(x) (x*(x+1)*(2*x+1) / 6)
printf("Does GPU value %.6g = %.6g?\n",
c, 2 * sum_squares((float)(N - 1)));
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
delete []a;
delete []b;
delete []partial_c;
}![]()
》》》回忆一下kernel函数中的:
while(i!= 0){
if(cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i]; __syncthreads(); i /= 2; }这里加一个__syncthreads();是因为使得下次循环时每个要用到的数据都是正确的,而一个block中每次都有一半的数据不会在下个循环中用到,就不需要同步了,那么我们可不可以改成:
while(i!= 0){ if(cacheIndex < i){ cache[cacheIndex] += cache[cacheIndex + i]; __syncthreads(); }
i /= 2;
}不可以,程序会崩溃。
首先介绍一下thread divergence线程分支。所有线程执行的指令都是一样,但是它们操作的数据不同。上端代码中出现了if判断句,当一个block中所有线程有一部分满足条件而另一部分不满足的时候,满足条件的线程执行程序,而不满足的线程什么都不做,而不是执行另一分支的指令。
当程序中出现__syncthreads();时,要求:直到一个block中所有线程都执行到这句时,才能执行之后的指令。如果有部分线程不执行这个指令,则所有线程永远在等待。这真是个悲剧。
__syncthreads();很有用也很必要,但是一定要注意让所有的线程都执行到这句。
》》》shared memory bitmap
这个实验展示了正确使用__syncthreads()是多么重要啊!!!
首先是主函数,基本上和Julia Set差不多, 就是<<<>>>中的内容变了下,变成了,嗯…:
int main( void ) {
CPUBitmap bitmap( DIM, DIM );
unsigned char *dev_bitmap;
HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size()));
dim3 grids(DIM/16, DIM/16); //
dim3 threads(16, 16); //
kernel<<<grids, threads>>>(dev_bitmap);
HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost));
bitmap.display_and_exit();
cudaFree(dev_bitmap);
}下面是uncorrect的kernel函数:
__global__ void kernel(unsigned char *ptr){
//熟悉的计算……
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
//因为用到shared M所以分配空间:
__shared__ float shared[16][16];
const float period = 128.0f;
//计算每个点(不明觉厉)(谁看谁傻逼):
shared[threadIdx.x][threadIdx.y] =
255 * (sinf(x*2.0f*PI/ period) + 1.0f) *
(sinf(y*2.0f*PI/ period) + 1.0f) / 4.0f;
ptr[offset*4 + 0] = 0;
ptr[offset*4 + 1] = shared[15-threadIdx.x][15-threadIdx.y];
ptr[offset*4 + 2] = 0;
ptr[offset*4 + 3] = 255;
}然后我们得到了破碎的绿色小球:

很显然少了一句
shared[threadIdx.x][threadIdx.y] =
255 * (sinf(x*2.0f*PI/ period) + 1.0f) *
(sinf(y*2.0f*PI/ period) + 1.0f) / 4.0f;
__syncthreads(); ///////////////////////////
ptr[offset*4 + 0] = 0;
ptr[offset*4 + 1] = shared[15-threadIdx.x][15-threadIdx.y];
ptr[offset*4 + 2] = 0;
ptr[offset*4 + 3] = 255;这样以后的结果是:

》》》chapter review
- reduction
- shared merory
- sychronization
这章特别长,又长又臭……但是介绍的东西很重要!