TCP拥塞控制算法的演进
TCP拥塞控制算法的演进
TCP协议仅定义框架,也就是发送端和接收端需要遵循的“规则”。TCP协议的实现经过多年的改进,有了多个不同的版本。比较重要的有Tahoe、Reno、NewReno、SACK、Vegas等,有些已经成为了影响广泛的RFC文档,有些则成为了Unix/Linux操作系统的标准选项。
以下简要介绍各个实现版本的主要区别和联系。
1 早期的TCP实现
最早的TCP使用简单的停等协议,每发送一个报文段都要等待收到确认,才能顺序发送下一个报文段,因此效率很低,网络资源不能得到充分利用。如果发生报文段丢失,必须等待重传定时器超时才能重新发送丢失的报文段,对网络拥塞没有采取有效的措施。
具体的实现,可以参考第1章的数据链路层的介绍。
2 TCP Tahoe
Tahoe算法是TCP的早期版本。它的核心思想:让cwnd以指数增长方式迅速逼进可用信道容量,然后慢慢接近均衡。Tahoe包括3个基本的拥塞控制算法:“慢启动”、“拥塞避免”和“快速重传”。同时Tahoe算法实现了基于往返时间的重传超时估计。
(1)TCP Tahoe在连接建立后,cwnd初始化为一个报文段,开始慢启动,如果没有丢包和拥塞发生,直到cwnd等于ssthresh,然后进入拥塞避免。
(2)若重传定时器超时,cwnd重新设置为一个报文段大小,重新开始慢启动,同时ssthresh为当前cwnd的一半。
(3)若发送端收到3个重复ACK,不等到重传定时器超时就执行快速重传,即立刻重传丢失的报文段。
重传超时估计是对重传定时器的超时时间取值的估计。重传定时器是判断报文段丢失的依据,发送端发送一个报文段同时启动重传定时器,如果重传定时器超时,但发送端还没有收到接收端的ACK,就判断该报文段丢失,重传丢失报文段并重新启动重传定时器。每一个TCP连接都维护一个变量,用于计算往返时间RTT。TCP采用动态重传超时估计,即以往返时间RTT为基础来确定重传超时时间。其中最常用的是设置重传超时时间为往返时间RTT的两倍,即
重传超时时间= 2×RTT
另外,往返时间RTT的计算也是动态的,通常可以按下列式子计算:
RTT=a ×最近RTT+(1-a )×当前RTT
其中,a 的取值为0~1,一般取值0.8~0.9。
在检测到报文段丢失后,希望能迅速地将该报文段重传,减少不必要的等待时间,提高TCP的吞吐量。如果设置重传超时时间等于往返时间RTT,那么当网络中的时延变化引起当前往返时间RTT值略大时,就会使重传超时时间小于往返时间RTT,导致不必要的重传,因此一般使用重传超时时间为往返时间RTT的两倍。
Tahoe算法的不足之处在于,收到3个重复ACK或在超时的情况下,Tahoe设置cwnd为1,然后进入慢启动阶段。这一方面会引起网络的激烈振荡,另一方面大大降低了网络的利用率。
3 TCPReno
针对Tahoe算法的不足,提出了Reno算法,主要有两方面改进:一是对于收到连续3个重复的ACK确认,算法不经过慢启动,而直接进入拥塞避免阶段;二是增加了快速重传和快速恢复机制。Reno算法以其简单、有效和鲁棒性好成为TCP控制算法的主流,被广泛应用。
TCP Reno在TCP Tahoe版本上加入“快速恢复”算法。TCP Reno中,如果发送端收到3个重复ACK,不必等到重传定时器超时,就会执行快速重传,然后执行快速恢复算法,进入拥塞避免。
TCP Reno的状态转换图如图3.1所示。
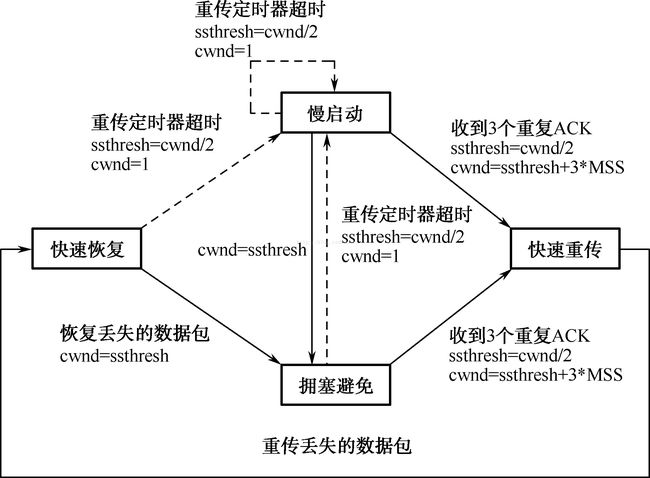 图1 TCP Reno状态转换图
图1 TCP Reno状态转换图
尽管Reno算法对Tahoe算法做出了改进,但Reno算法仍然存在不足。
(1)首先发送端在检测到丢包或拥塞后,重传从数据丢失到检测到丢失这段时间发送端发送的所有报文段,但是其中有些报文段被接收端正确收到,可以不必重传。
(2)其次,准确测量往返时间RTT是很重要的。理论上往返时间RTT的测量比较简单,是指报文段从发出到ACK返回发送端的时间,但是由于TCP是使用一个ACK确认所有已经收到的报文段的“累积”确认方式,往返时间RTT的估值在实际中往往比较复杂,因此准确测量往返时间RTT也是研究问题之一。
(3)Reno算法的另一个不足之处在于,它不能有效地处理多个报文分组从同一数据窗口丢失的情况。
4 TCP NewReno
TCP NewReno的主要改进在于一个窗口内多个报文段丢失的问题。这样可以避免TCP Reno中的多次重传超时。另外,TCP NewReno算法在快速恢复中引入了部分确认(Partial ACK)。它在快速恢复阶段到达并且确认新数据,但它只确认进入快速重传之前发送的一部分数据。
部分确认是指在快速恢复阶段对新报文段的确认(不包括还在传输中未接收到的数据)。在Reno中,部分确认导致离开快速恢复状态,即发送端收到一个不重复的ACK就退出快速恢复阶段。在NewReno中,只有当所有报文段的ACK都收到后才退出快速恢复。
具体来说,就是重传定时器溢出或者重复地确认ACK到达时,TCP Reno会退出快速恢复状态,等待,但是TCP NewReno并不退出快速恢复状态,而是按以下步骤执行。
(1)重传紧接着那个部分确认ACK之后的报文段,拥塞窗口减去部分确认ACK的大小;
(2)对于得到确认的新数据,设置cwnd等于其加上SMSS:
(3)对于第一个或每一个Partial ACK,重传定时器复位。
举例说明,序号为1的报文段丢失了,TCP发送端又发送了序号为2、3、4、5的报文段之后才收到3个重复的ACK。进入快速重传,重传序号为1及其之后的报文段,然后进入快速恢复,等待序号为1的报文段的ACK。此时,TCP发送端记录序号为5,就是说TCP发送端希望收到序号为6的ACK。如果收到序号为6的ACK,那么这个ACK就确认了重传之前的所有报文段。
但是如果收到序号小于6的ACK,那么这个ACK只是确认了重传之前的部分报文段,也就说明此时丢失了多个报文段,这个ACK就是部分确认的ACK。例如,收到序号为3的ACK,那么能够确定序号为1的丢失的报文段和序号为2的报文段重传后都被接收到,也说明序号为3的报文段也丢失了,需要重传。
如果执行TCP Reno算法,收到部分确认的ACK即序号为3的ACK就退出快速恢复回到拥塞避免,然后收到3个重复的序号为3的ACK再进入快速重传,重传序号为3的报文段再进入快速恢复。这样TCP发送端不仅增加了发送的时间,而且拥塞窗口一直重复地减半,如果丢失的报文段更多的话,整个TCP的吞吐量就会变得很低。
如果执行TCP NewReno算法,收到部分确认的ACK即序号为3的ACK就继续进行快速重传,重传序号为3的报文段,然后继续快速恢复,如果还有报文段丢失,那么重复这个过程。这样TCP发送端发送时间缩短,而且避免了拥塞窗口不必要的减小。
5 TCP SACK
TCP SACK(Selective Acknowledgement)也是对TCP Reno的改进,当检测到拥塞后,不必重传从数据丢失到检测到丢失这段时间发送端发送的所有报文段,而是对这些报文段进行有选择的确认和重传,避免不必要的重传。
在连接建立阶段,发送端和接收端进行“协商”,确定是否使用SACK选项。SACK选项需要在TCP报文段中设置标识位,标识接收端最近收到的序列号连续的三个报文段。如果使用SACK选项,那么在数据传输中,当接收端缓存队列中出现序号不连续的报文段时,就向发送端发送标识SACK选项的重复ACK。发送端得知哪些报文段已经被接收,哪些报文段丢失,从而选择性地重传丢失的报文段。
SACK选项已经成为Linux系统的标准选项,在目前的系统部署中,这个标准选项通常都已经选中。
6 TCP Vegas
1994年,Brakmo提出了TCP Vegas算法。TCP Vegas是一种截然不同的拥塞控制算法,它采用一种更巧妙的带宽估计策略,根据期望的流量速率与实际速率的差估计网络瓶颈处的可用带宽。
由于TCP Vegas只和往返时间RTT的改变有关,所以往返时间RTT的准确度非常重要。实际过程中采取了许多措施来保证往返时间RTT测量的精确度,如细粒度的时间计算等。同时,TCP报文段大小也会对往返时间RTT有一定影响。
7 TCP Veno
无线环境的高误码率对TCP性能产生很大影响。因为高误码率引起数据包丢失,通常被认为是拥塞,采取拥塞控制机制,但是实际网络中并没有拥塞产生。所以频繁的拥塞控制降低了传输速率,导致吞吐量下降。TCP Veno采取测量网络拥塞状况的方法,判断拥塞丢包还是随机丢包,采取不同的拥塞控制机制。新的拥塞控制机制针对随机丢包尽量保持传输速率,适当减小拥塞窗口,提升吞吐量。
3.3.8 TCP BIC
TCP BIC由北卡罗来纳州立大学(North Carolina State University)的网络研究实验室提出,该算法在提出不久后就成为了当时Linux内核中的TCP默认拥塞算法。
BIC的提出者们发现了TCP拥塞窗口调整的一个本质问题:那就是找到最适合当前网络的一个发送窗口。为了找到这个窗口值,一般拥塞控制算法采取的策略是缓慢探测,也就是每个RTT加1,缓慢上升,丢包时下降一半,接着再来慢慢上升。BIC算法的提出者们则直指事情的本质,认为这是一个搜索过程,可以认为这个值是在1和一个比较大的数之间,那么显然最好的方式就是二分搜索。
9 TCP CUBIC
CUBIC在设计上简化了BIC的窗口调整算法,CUBIC的模型使用了一个三次函数(即立方函数)。鉴于CUBIC更出色的表现,在Linux2.6.18版本后,CUBIC取代了BIC,成为默认的TCP算法。
10 FAST TCP
加州理工学院的StevenLow教授提出了一种改进的DelayBased TCP拥塞控制算法,称为FASTTCP(FAST AQMScalable TCP)。和TCP Vegas相同,FAST TCP也使用网络的排队延迟作为链路拥塞的唯一标识信号。
Fast TCP后来没有对开源社区做贡献了,因为Steven Low自己创办了公司,把Fast TCP变成了商业产品,所以后续的学术研究就比较少了。Fast TCP是从TCP Vegas的思想发展而来,利用网络延时进行拥塞判断。基于延迟的算法是对整个网络的拥塞控制有好处的,但是相对当前基于丢包的算法来说,两者不公平。所以估计Steven Low后面也做了很多的改进。
11 Compound TCP
Compound TCP是微软亚洲研究院的谭焜博士提出的一种混合型TCP拥塞控制算法。该算法的设计思想是结合基于时延的算法和基于丢包的算法的优点,在充分利用高速网络带宽的同时,仍然保持和传统TCP Reno算法的公平性。
参考:
大数据时代下的通信需求——TCP传输原理与优化 http://www.phei.com.cn/module/goods/wssd_content.jsp?bookid=43284