Spark学习二
Spark学习二
标签(空格分隔): Spark
- Spark学习二
- 一RDD
一,RDD
[hadoop001@xingyunfei001 spark-1.3.0-bin-2.5.0]$ sbin/start-master.sh
[hadoop001@xingyunfei001 spark-1.3.0-bin-2.5.0]$ sbin/start-slaves.sh
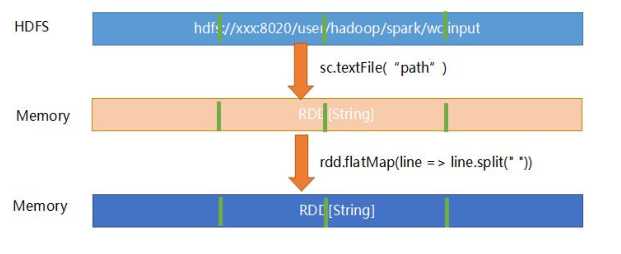

RDD创建的2种方式
第一种:
val list=List("spark","hdfs","yarn")
val listrdd=sc.parallelize(list)第二种:
val rdd=sc.textFile("/input")- RDD Operations
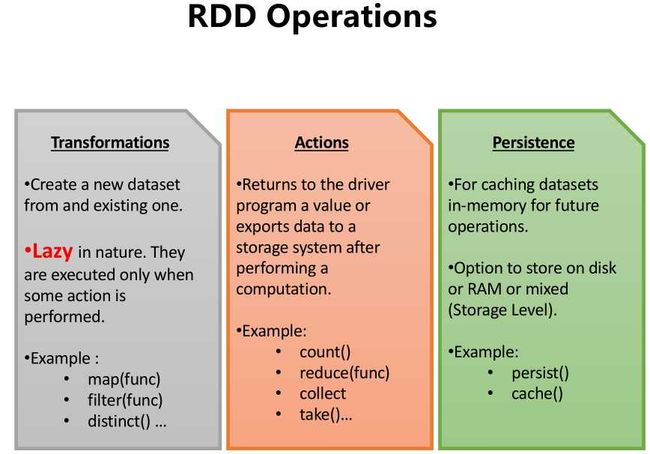

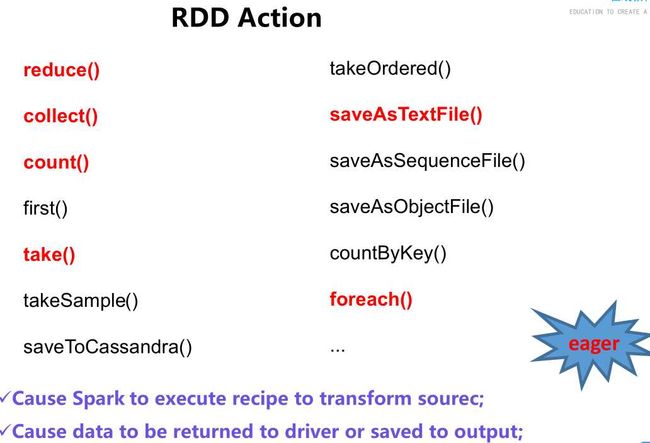
val temp=sc.parallelize(List(9,3,4,5,2,8))
temp.top(1)
temp.saveAsTextFile("/test")
temp.foreach(println(_))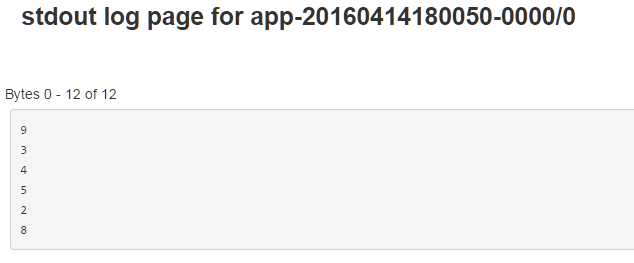
val rdd=sc.parallelize(List(("hadoop",12),("word",32),("hadoop",45),("hadoop",12),("word",32),("yarn",65),("word",32)))
rdd.groupByKey().map(x => (x._1, x._2.toList)).collect
rdd.groupByKey().map(x => (x._1, x._2.toList.sorted)).collect
rdd.groupByKey().map(x => (x._1, x._2.toList.sorted.takeRight(3))).collect
rdd.groupByKey().map(x => (x._1, x._2.toList.sorted.takeRight(3).reverse)).collect
=============
rdd.groupByKey().map(x => (x._1, x._2.toList.sorted.reverse.takeRight(3))).collect
性能要差些
=============rdd.map(_.split(" ")).map(x => (x(0), x(1).toInt)).groupByKey().map(x =>{
val xx = x._1
val yy = x._2
val yx = yy.toList.sorted.reverse.take(3)
(xx, yx)
} ).collect
- RDD依赖
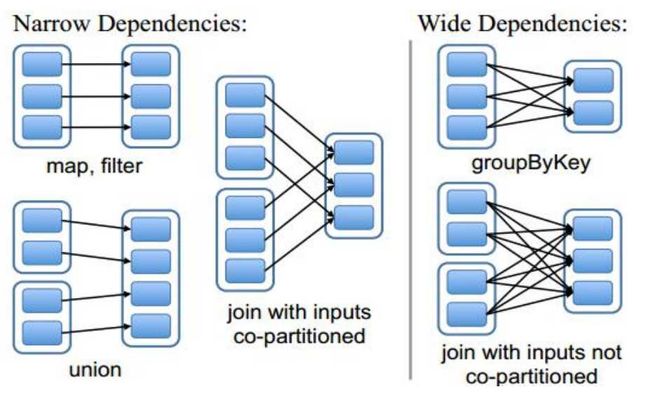

- RDD shuffle


- 提交应用给spark
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://bigdata-senior01.ibeifeng.com:7077 \
/opt/modules/spark-1.3.0-bin-2.5.0/lib/spark-examples-1.3.0-hadoop2.5.0.jar \
100- IDE的安装
1,解压安装包到指定目录

2,启动idea
bin/idea.sh3,设置页面风格
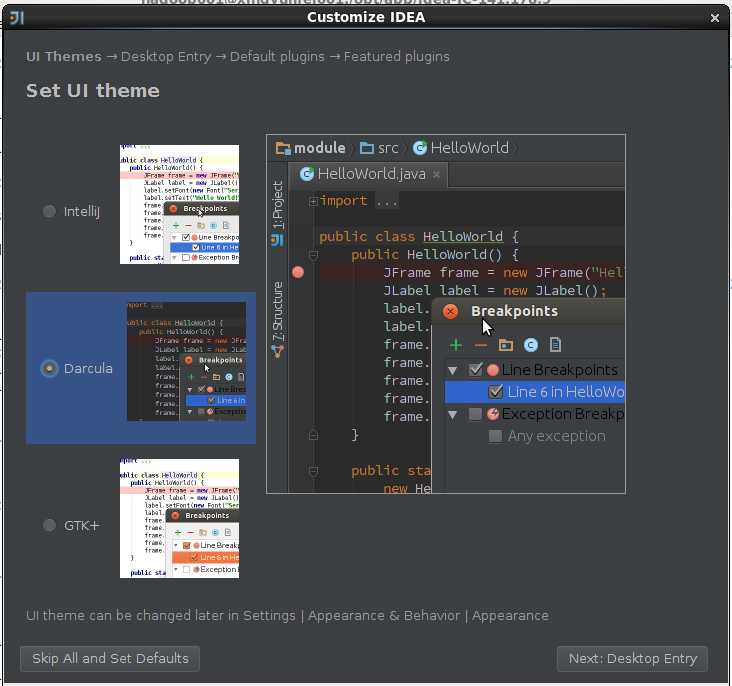
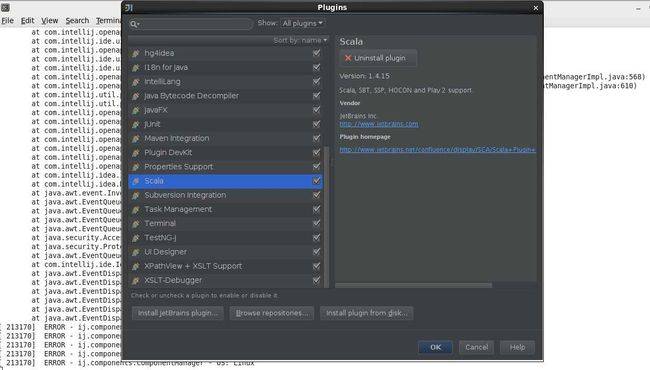
4,配置scala插件

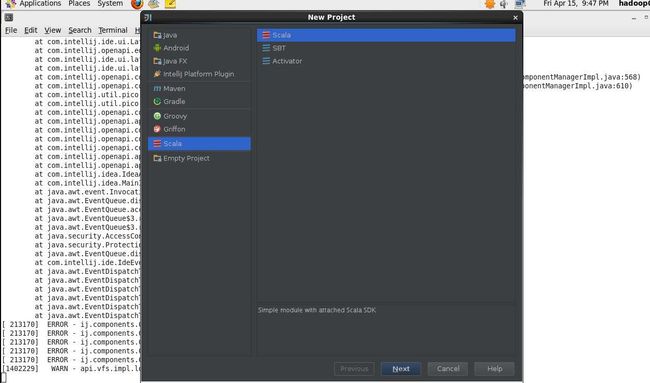
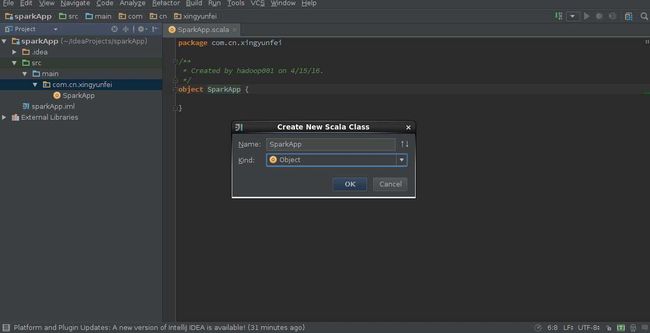
5,创建工程
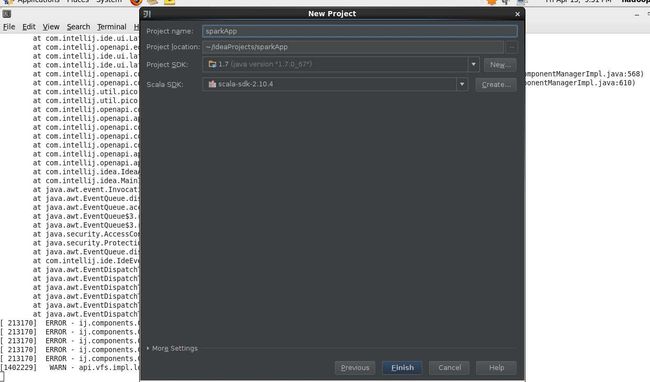
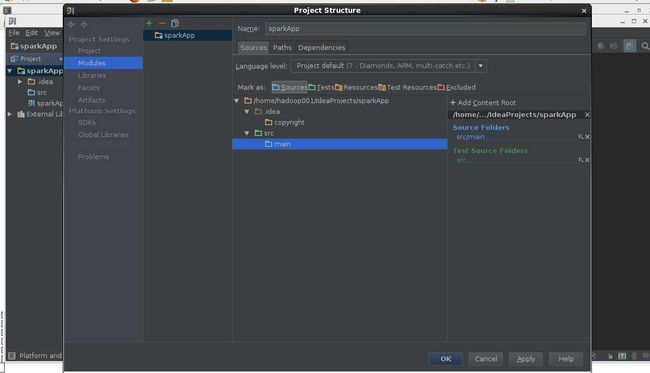
6,配置工程

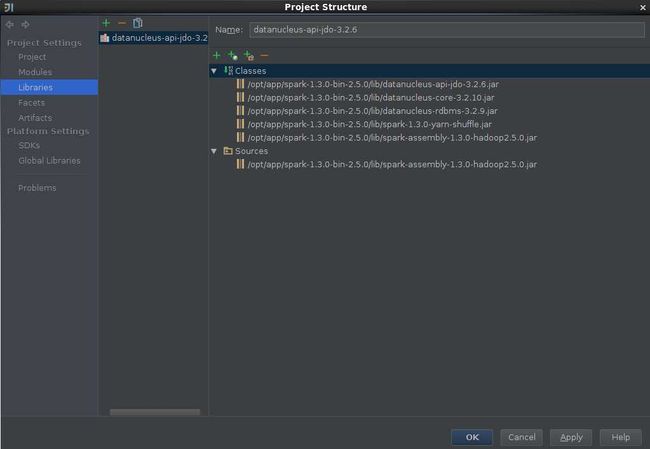
7,添加spark需要的jar包

8,导出jar包


- 启用历史服务器
sbin/start-history-server.sh修改spark-defaults.conf文件:
# Default system properties included when running spark-submit.
# This is useful for setting default environmental settings.
# Example:
spark.master spark://xingyunfei001.com.cn:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://xingyunfei001.com.cn:8021/spark/log
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
修改spark-env.sh文件:
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://xingyunfei001.com.cn:8021/spark/log"
sbin/start-history-server.sh