SparkSQL基础应用(1.3.1)
一.概述
从1.3版本开始Spark SQL不再是测试版本,之前使用的SchemaRDD重命名为DataFrame,统一了Java和ScalaAPI。
SparkSQL是Spark框架中处理结构化数据的部分,提供了一种DataFrames的概念,同时允许在Spark中执行以SQL,HiveQL或Scala表示的关系型查询语句。
就易用性而言,对比传统的MapReduceAPI,说Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。为了解决这一矛盾,Spark SQL1.3.0在原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。新的DataFrame API不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。
新的DataFrame API在R和Python Dataframe的设计灵感之上,专门为了数据科学应用设计,具有以下功能特性:
· 从KB到PB级的数据量支持;
· 多种数据格式和多种存储系统支持;
· 通过Spark SQL的Catalyst优化器进行先进的优化,生成代码;
· 通过Spark无缝集成所有大数据工具与基础设施;
· Python、Java、Scala和R语言(SparkR)API。
二.DataFrame
2.1 DataFrame是什么
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
2.2 数据格式和数据来源
DataFrame的创建有几种方式,可以是其他已存在的RDD,hive table中的数据或其他的数据源中的数据(Json,parquet等)
SQL返回DF
//caseclass需要定义在Object外
case classPerson(name:String,age:Int)
val peopleDF = sc.textFile(args(0)).map(_.split(",")).
map(p=>Person(p(0),p(1).trim.toInt)).toDF()
//可以调用cacheTable方法将表中的数据都存于内存中,而不用每次查询都去磁盘上找数据
peopleDF.registerTempTable("people")
cacheTable("people")
//sql查询的结果是DF
val teenagers = sqlContext.sql("SELECTname FROM people WHERE age >= 13 AND age <= 19")
teenagers.show()
RDD
数据

代码
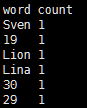
//导入SparkSql数据类型 import org.apache.spark.sql.types.{StructType,StructField,StringType}; import org.apache.spark.sql.Row; val schemaString = "word count" val schema = StructType( schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true))) //从其他RDD转化而来 val rdd = sc.textFile(args(0)).flatMap(_.split(',')).map(x=>(x,1)).
reduceByKey(_+_).map(x=>Row(x._1,x._2))
val df =sqlContext.createDataFrame(rdd,schema)
df.show()
结果
Json
数据

代码
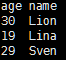
//从Json中获取数据,下面两种方式皆可
val json = sqlContext.jsonFile(args(0))
val json1 = sqlContext.load(args(0),"json")
json.show()
//保存为parquet文件供下次使用
json.saveAsParquetFile("hdfs://master:9000/SparkSql/people.parquet")
结果
Parquet
Parquet文件允许将schema信息和数据信息固化在磁盘上,以供下一次的读取。
代码
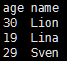
//从parquet文件中获取数据,以下两种方法皆可
val parquetData = sqlContext.parquetFile(args(0)) val parquetData1 = sqlContext.load(args(0),"parquet") parquetData.show()
结果
Mysql
载入驱动包
有三种方式:
1.在SPARK_CLASSPATH中加入mysql驱动包
2.在spark-submit提交时用--driver-class-path参数加入驱动包地址
3.在sparkConf中加入spark.driver.extraClassPath属性。
不能同时使用,否则会报错!!!!
数据
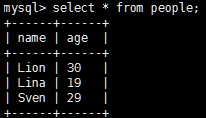
代码
//连接mysql数据库
val mysqlData = sqlContext.jdbc("jdbc:mysql://master:3306/sparkSql?user=root&password=123","people")
mysqlData.show()
结果
其它数据源(Hive,s3)
//加载S3上的JSON文件
val logs = sqlContext.load("s3n://path/to/data.json","json")
//从Hive中的people表构造DataFrame
val hiveData= sqlContext.table("people")
2.3 DataFrame操作
import org.apache.spark.sql.SQLContext import org.apache.spark.{SparkContext, SparkConf} case class Person(name:String,age:Int) object sqlTest { def main(args: Array[String]) { val conf = new SparkConf() val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) //将RDD隐式转化为DataFrame import sqlContext.implicits._ val people = sc.textFile(args(0)).map(_.split(",")).
map(p=>Person(p(0),p(1).trim.toInt)).toDF() //输出全表内容 people.show() //将name字段的数据输出 people.select("name").show() //把所有人的年龄加1 people.select(people("name"), people("age") + 1).show() //筛选出年龄大于21并且小与30的人 people.filter(people("age")>21 and people("age")<30).show() //统计名字出现的次数 people.groupBy("name").count().show() //树状图的形式输出表结构 people.printSchema() sc.stop() } }
2.3.1 结果
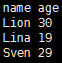
people.show()
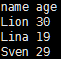
people.select(“name”).show()
![]()
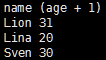
people.select(people(“name”),people(“age”)+1).show()
people.filter(people(“age”)>21 andpeople(“age”)<30).show()
![]()
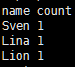
people.groupBy(“name”).count().show()
people.printSchema()
2.4 Parquet Files
2.4.1 介绍
需要提出的是registerTempTable注册的表是存在内存中的一个临时表,使用cacheTable方法可以把表中的数据存于内存中便于查询,生命周期只在所定义的sqlContext或hiveContext中,换句话说在一个sqlContext/hiveContext中注册的表在其他的sqlContext/hiveContext中无法使用。
因此我们可以把临时表以ParquetFile的格式固化到磁盘中,以便以后多次使用。
Spark SQL从一开始便内置支持Parquet这一高效的列式存储格式。在开放外部数据源API之后,原有的Parquet支持也正在逐渐转向外部数据源。1.3.0以后,Parquet外部数据源的能力得到了显著增强。主要包括schema合并和自动分区处理。
2.4.2 表合并(schema Merging)
与ProtocolBuffer,Avro和Thrift类似,Parquet也允许用户在定义好schema之后随时间推移逐渐添加新的列,只要不修改原有列的元信息,新旧schema仍然可以兼容。这一特性使得用户可以随时按需添加新的数据列,而无需操心数据迁移。
2.4.3 分区发现
按目录对同一张表中的数据分区存储,是Hive等系统采用的一种常见的数据存储方式。新的Parquet数据源可以自动根据目录结构发现和推演分区信息。
2.4.4 分区剪枝
分区实际上提供了一种粗粒度的索引。当查询条件中仅涉及部分分区时,通过分区剪枝跳过不必要扫描的分区目录,可以大幅提升查询性能。
2.4.5 Parquet File操作
//表1字段为(id,name) val df1 = sc.makeRDD(1 to 5).map(x=>(x,x*2)).toDF("id","name") df1.save("hdfs://master:9000/SparkSql/key/key=1","parquet") //表2字段为(id,age) val df2 = sc.makeRDD(6 to 10).map(x=>(x,x*3)).toDF("id","age") df2.saveAsParquetFile("hdfs://master:9000/SparkSql/key/key=2") //表3字段为(id,name,age)
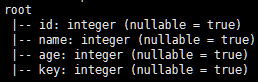
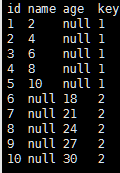
//通过分区发现进行表合并 val df3 = sqlContext.load("hdfs://master:9000/SparkSql/key","parquet") df3.printSchema() df3.show() val df4 = df3.filter($"key" >= 2) df4.show()
结果
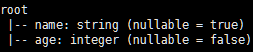
df3.printSchema
df3.show
df4.show
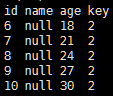
可见,Parquet数据源自动从文件路径中发现了key这个分区列,并且正确合并了两个不相同但相容的schema。值得注意的是,在最后的查询中查询条件跳过了key=1这个分区。Spark SQL的查询优化器会根据这个查询条件将该分区目录剪掉,完全不扫描该目录中的数据,从而提升查询性能。
2.5.统一的load/save API
在Spark 1.2.0中,要想将SchemaRDD中的结果保存下来,便捷的选择并不多。常用的一些包括:
· rdd.saveAsParquetFile(...)
· rdd.saveAsTextFile(...)
· rdd.toJSON.saveAsTextFile(...)
· rdd.saveAsTable(...)
· ....
可见,不同的数据输出方式,采用的API也不尽相同。更令人头疼的是,我们缺乏一个灵活扩展新的数据写入格式的方式。
针对这一问题,1.3.0统一了load/save API,让用户按需自由选择外部数据源。这套API包括:
1.SQLContext.table
从SQL表中加载DataFrame。
2.SQLContext.load
从指定的外部数据源加载DataFrame。
3.SQLContext.createExternalTable
将指定位置的数据保存为外部SQL表,元信息存入Hivemetastore,并返回包含相应数据的DataFrame。
4.DataFrame.save
将DataFrame写入指定的外部数据源。
5.DataFrame.saveAsTable
将DataFrame保存为SQL表,元信息存入Hive metastore,同时将数据写入指定位置。
小结
DataFrame API的引入一改RDD API高冷的FP姿态,令Spark变得更加平易近人,使大数据分析的开发体验与传统单机数据分析的开发体验越来越接近。外部数据源API体现出的则是兼容并蓄。目前,除了内置的JSON、Parquet、JDBC以外,社区中已经涌现出了CSV、Avro、HBase等多种数据源,Spark SQL多元一体的结构化数据处理能力正在逐渐释放。
参考:
http://www.csdn.net/article/2015-04-03/2824407
http://www.tuicool.com/articles/eINjueA