poj2255 Tree Recovery 字典树 解题报告(Ulm Local 1997)
Tree Recovery
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 12530 | Accepted: 7840 |
Description
Little Valentine liked playing with binary trees very much. Her favorite game was constructing randomly looking binary trees with capital letters in the nodes.
This is an example of one of her creations:
To record her trees for future generations, she wrote down two strings for each tree: a preorder traversal (root, left subtree, right subtree) and an inorder traversal (left subtree, root, right subtree). For the tree drawn above the preorder traversal is DBACEGF and the inorder traversal is ABCDEFG.
She thought that such a pair of strings would give enough information to reconstruct the tree later (but she never tried it).
Now, years later, looking again at the strings, she realized that reconstructing the trees was indeed possible, but only because she never had used the same letter twice in the same tree.
However, doing the reconstruction by hand, soon turned out to be tedious.
So now she asks you to write a program that does the job for her!
This is an example of one of her creations:
D
/ \
/ \
B E
/ \ \
/ \ \
A C G
/
/
F
To record her trees for future generations, she wrote down two strings for each tree: a preorder traversal (root, left subtree, right subtree) and an inorder traversal (left subtree, root, right subtree). For the tree drawn above the preorder traversal is DBACEGF and the inorder traversal is ABCDEFG.
She thought that such a pair of strings would give enough information to reconstruct the tree later (but she never tried it).
Now, years later, looking again at the strings, she realized that reconstructing the trees was indeed possible, but only because she never had used the same letter twice in the same tree.
However, doing the reconstruction by hand, soon turned out to be tedious.
So now she asks you to write a program that does the job for her!
Input
The input will contain one or more test cases.
Each test case consists of one line containing two strings preord and inord, representing the preorder traversal and inorder traversal of a binary tree. Both strings consist of unique capital letters. (Thus they are not longer than 26 characters.)
Input is terminated by end of file.
Each test case consists of one line containing two strings preord and inord, representing the preorder traversal and inorder traversal of a binary tree. Both strings consist of unique capital letters. (Thus they are not longer than 26 characters.)
Input is terminated by end of file.
Output
For each test case, recover Valentine's binary tree and print one line containing the tree's postorder traversal (left subtree, right subtree, root).
Sample Input
DBACEGF ABCDEFG BCAD CBAD
Sample Output
ACBFGED CDAB
题意:输入两组数据,分别是前序遍历序列和中序遍历序列,你需要编写程序通过这两组数据求出该树的后序遍历序列(前序序列 + 中序序列 = 后序序列)
可以先按照用笔和纸的形式去推导出后序序列。推导过程省略,在推导过程中我们会发现规律:
假设 前序序列是 A B E H F C G I
中序序列是 H E B F A C I G (图如下)
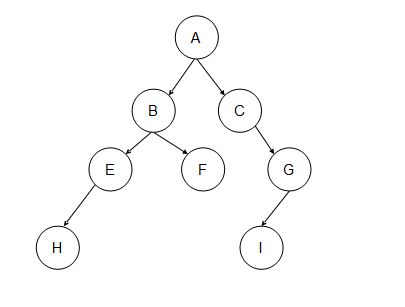
每一次从前序序列里,按顺序抽取出字母就能将中序序列分割,并根据中序遍历的特性。分割后的两部分分别是 左子树 和 右子树(注意,他们也是二叉树!)
就像这样:取A, 中序序列被分割为 左子树:H E B F 右子树 C I G
继续取B,但是这次是对左子树:H E B F 进行分割。 分割结果是: 左子树:H E 右子树 B F
直到不能再分割,递归会返回去到第一次使用 A 分割出来的 右子树 里继续分割
上述整个过程都是递归,所以结合代码和用纸笔画一次会更好理解
代码附上:
#include <stdio.h>
#include <stdlib.h>
typedef struct tn//TreeNode的简写
{
char data;
struct tn *lchild;
struct tn *rchild;
}Node,*PNode;
char pre[28];//前序
char infix[28];//中序
char *Pr;//中转用的字符串指针
void build(char *in,char *pr,PNode *tr);
void getlast(PNode T);
int main()
{
PNode T;
while(scanf("%s %s",&pre[1],&infix[1])==2)
{
build(&infix[1], &pre[1], &T);
getlast(T);
printf("\n");
}
return 0;
}
void build(char *in,char *pr,PNode *tr)
{
char *p=in;
Pr=pr;
if(*in==0)
{
*tr=NULL;
return;
}
while(1)
{
if(*in==*pr)
{
(*tr)=(PNode)malloc(sizeof(Node));
(*tr)->data=*pr;
*in=0;//这样*p就被分割了
break;
}
in++;
}
Pr++;
build(p,Pr,&(*tr)->lchild);
build(in+1,Pr,&(*tr)->rchild);
}
void getlast(PNode T)
{
if(T==NULL)return;
getlast(T->lchild);
getlast(T->rchild);
printf("%c",T->data);
}