Kafka 0.9.0 文档翻译-1、Getting Started
kafka目前应用比较广泛,中小规模的公司都把kafka当做大数据平台的数据总线,成为很多流计算系统的输入源,比如storm,flink,spark-streaming等。同时各种应用的日志做离线处理的时候,架构上倾向于使用kafka作为消息管道,日志push到kafka,然后使用分布式task将数据写入hdfs等,诸如此类的应用还有很多,这些正说明kafka有不错的高吞吐低延时性能。一些大的公司bat可能有自己的更加定制化的消息系统,比如阿里的metaq等。一直以来,没能系统地研究一下这些消息系统,现在打算先把kafka文档翻译一遍,然后看下kafka为什么这么受欢迎。
首先看下getting started:
kafka是一个分布式的,数据可分区的,分区有多个副本的消息系统,它很特别,特别在哪?
首先,review一下消息系统几个基本的语义:
1、消息怎么区分,topics,不同的topic代表不同类型的日志,这个就是tt(timetunnel)里的日志的概念
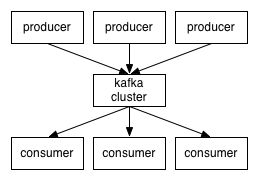
2、生产者 写消息到消息系统的角色
3、消费者 从消息系统订阅消息的角色
4、消息系统的服务端,由1个或者多个角色构成,这些角色叫做broker
生产、消费关系图:
我们之前接触的分布式系统,一般都有一些rpc协议,比如thrift,protobuffer,或者hadoop、hbase里面用的那套rpc框架等,kafka没用这些,控制流或者数据流都是最简单高效的tcp协议,serversocket,socket那一套。rpc框架可以提高编程效率,更倾向于做高并发的控制流通信。
kafka 大家都知道是scala编写的核心,但是它也支持java以及其他很多语言的客户端。
下面再讲讲kafka的topics的概念
topic其实是一个逻辑概念,对于用户来说,我需要用你kafka传输数据的时候,订阅数据的时候,我需要知道一个topic,我的数据因为有topic不至于跟其他日志混淆。
在kafka里,topic的物理意义就是指存储数据的目录名字啊,之类的,不同topic的数据放到不同的目录里。tt的不同日志其实对应的是多个queue,这些queue对应的是hbase表的region,不同topic对应不同的一组region,即消息系统的topic其实就是底层存储系统上,独立的存储单元的集合。
Topics and Logs
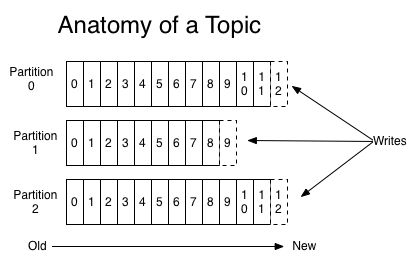
topic下面是queue的语义,kafka里成为partition,什么是queue、partition?我们可以统一叫做分区,分区有自己的特点:有序的,数据不可变的消息集合,卧槽,说的太学术了,直接点就是追加写的一个文件,只能追加,不许改写过的数据,这个分区内是有序的,分区内每条消息都有个点位,叫做offset,即一条消息在这个分区内的唯一的位置标号,如果这个分区消息是写在一个文件中的,你可以理解成一行在这个文件中的偏移量,读的时候只要seek到这个位置,就能读到这一行数据。
kafka接收读写,一个个的topic,每个topic又有多个分区,这些数据是持久化存储的,一般保存3天,这个时间你可以配置的,过期的数据,kafka会安排线程清理掉前面提到分区的点位,这个点位是最关键的信息,比如你再storm里处理数据,对于ack_failed的数据重发,你可能需要replay,重放那些失败的数据,怎么重放?就是重新调整点位,重新从消息系统拉取数据。
一个文件顺序追加,数据就在那躺着,你想读哪些数据,你只要让点位动一动就行了,一般来说这个点位包含时间信息,我想读15点的数据,就直接操作点位就行了。
点位系统其实是一个比较复杂的系统,一个topic的每个分区都有自己的点位,怎么衡量整个topic的点位,一般是取消费最慢的那个分区的点位当做整个分区的点位,点位怎么存储,怎么计算,不简单,做一个好的点位系统其实很复杂。kafka避开了点位系统,自己不管,让消费者自己控制,你可以把点位存储在zk上面,也可以存储到mysql等等。
实现,点位为什么不好做,首先,服务端需要记住每个订阅,即给每个订阅分配一个subid,我要记住全部subid的点位。
kafka省心啊,不做点位,谁订阅可以,自己记住你的点位,别来找我要,这样的话,服务端就省去了很多状态管理的开销。
分区的作用不必细说了,主要是解决并发的问题,以及分布式数据管理的问题,即扩展的问题。比如你的数据量很大,我没有分区的话,就相当于只有一个分区,这个分区追加写,读的时候只能单线程读啊,还有就是追加写,我如果多台机器管理同一个“分区”,怎么追加写,怎么跨机器读,显然不合理,因此多分区是必然的。
下面再看看kafka的分布式化特点。所谓分布式化其实就是管理的分区的分布式,你不把分区放到多台机器上,网卡能受了,tps,qps也满足不了业务需求,所以一个topic的数据分区肯定要分散到不同的机器上,就跟hdfs的块一样的道理,同样的,为了提供更好的并发性和容错,读写尽量散列到不同的机器上,那么最好每个分区还有多个副本,这样的话,我读一个分区,到A机器也行,到B机器也行。当然这样做就得考虑副本数据一致性,副本之间的数据复制等,或者双写。
其实说到这,感觉消息系统跟分布式数据库有很多类似的地方,消息系统是顺序写,连续读,因为有点位也可以做基于点位的“随机读”,数据库也是支持随机读的,数据也要分片,做副本,同时副本之间要做数据复制,一致性等时,就需要选主,即一个数据分多个副本之间要有一个leader,所有的读写请求都会交给这个leader。leader挂了,剩下的follower里再选出来一个当leader。leader选举过程当中可能会有短暂的数据不可用,因此副本的leader选举时间要尽可能短。基于这种设计,消息系统或者分布式数据库就要保证每台机器上都有leader,尽量均匀,才能做到负载均衡。
kafka的server就是broker,broker说白了就是数据分区管理器,当然本身也做存储。
tt因为数据写到hbase,broker成了数据转发,代理读取的一个真正的broker,相对kafka,少了很多存储的设计。客户端发消息过来。我要先持久化了,写到commit-log(redolog)我才告诉你ok了,tt写hbase,不用管这些,因为hbase写到hlog ok了才会返回ok,tt利用hbase的hlog做了redolog这一层。
再来看看生产者:
生产者控制消息写入哪个topic,以及怎么写到各个分区,比如一个topic有多个分区,我可以写到一个分区,也可以轮询地往各个topic平均写,当然也可以按消息的字段做hash写,都是可以的。说到这里,如果你希望用kafka做保序的处理,那么只能在一个分区内保序,跨多个分区的是没办法有序的。这是业界难题,因为不同分区可能在不同机器上,你要做到多个分区的数据连续,那么你需要做分布式的协调,或者类似分布式事务,提高了分区一致性,那么必然可用性和分区扩展能力就会下降。
一般来说,消息系统其实有2种语义模型,一种是queuing的语义,另一种是发布订阅模型。什么叫queuing?
就是消息系统中的一个topic有多个queue,那么,每一个queue的一条消息只能发给一个消费者。这种相当于消息的负载均衡,即被瓜分,如果你把一个topic看成完整的一篇文章,那么每个消费者只读到片段,他们的数据合起来才是一个完整的文章我们更熟悉发布订阅模型,一个topic可以同时由多个消费者同时订阅,就好像一个文件,可以有多个reader同时读一样,只要读者自己记住自己读的位置就行了,读者之间互不干扰,这种模型有人说叫做广播,其实不太合理,因为消费者一般是拉的模型。
kafka 提供了一个消费者抽象模型叫做消费组,即consumer group。同时支持上述两种语义,这是啥意思?
几个消费者有一个共同的消费组的名字,比如a、b、c三个消费者,起个消费组名group3,这三个消费者可以不在同一个进程中,不在同一台机器上,那么这三个消费者可以订阅同一个topic,这个topic里面的一条消息,会发送给三个消费者的其中一个,也就是说这个topic的数据被三个瓜分了,而不是复制了三份,每个消费者都消费了完整的topic数据。
即group3里面的消费者,可以按照某种算法,瓜分一个完整的topic。比如我的请求消息都发到这个topic,消费组的消费者是web服务器,那么kafka的这种功能,相当于变成了负载均衡设备。
也就说所谓的同时支持queue和发布订阅模型,是指正常情况下是发布订阅模型,加入consumer group,相当于能支持queue模型了。
tt的日志有多个queue,即partition,订阅的时候,通过sdk可以指定消费哪几个partition的数据,即单个consumer可以消费单个或者多个partition的数据,但是不能多个消费者消费同一个partition的数据(使用同一个subid)因为这样,系统没办法记录点位。那么kafka是怎么做的呢,因为consumer也不记点位,那么kafka是不是不允许多个consumer消费同一个partition的数据呢,不是,它利用的是消费组的概念,这个消费组里的消费者,可以分别消费这个topic的某一个partition。比如一个topic有16个partition,那么这个消费组里最多有16个consumer,每个consumer分别消费1个partition。也就是说这个consumer group id相当于tt里的subid,但是tt里其实分别消费1个partition的consumer可以不在1个进程里,不在1台机器上。
文档也提到这种分区方式更方便保证有序,如果数据没有分区,那么当你replay的时候,虽然数据还是按照相同的数据读出来的,但是数据一般都是并发处理的,那么读出来的数据怎么保证跟上次分发给处理线程的一模一样?还是这种指定分区的方式更方便实现,即让数据源更加细粒度,更方便控制。
kafka保证:第一,数据单分区写进来什么顺序,就顺序追加到存储介质中,并且点位也能体现消息的写入先后顺序,第二,分区副本balance存放,你的一个分区有N个副本,那么挂N-1台broker,你的副本数据不会丢。第二点也意味着,副本数据的放置策略是尽可能地打散。