Optimization:Stochastic Gradient Descent
原文地址:http://cs231n.github.io/optimization-1/
########################################################################3
内容列表:
1.介绍
2.可视化损失函数
3.最优化
3.1.策略1:随机搜索
3.2.策略2:随机局部搜索
3.3.策略3:跟随梯度
4.计算梯度
4.1.有限差分(Numerically with finite differences)
4 .2 . 微积分计算(Analytically with calculus)
5.梯度下降
6.总结
############################################################################
Introduction
前一节,我们介绍了图像分类任务中两个关键的部分:
1.一个(参数化的)成绩函数(score function):用于把原始像素值映射为类别成绩(e.g. 线性函数)
2.一个损失函数(loss function):用于衡量一组给定的参数在计算得到的成绩和真正类别结果的一致性上的满意程度。我们看到了很多方法(e.g. Softmax/SVM)
具体的,回忆线性函数的格式为![]() ,同时SVM损失函数格式如下:
,同时SVM损失函数格式如下:
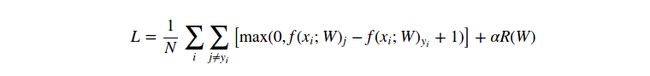
如果参数W设置合理,那么对于样本![]() 的预测结果会与真正结果相一致,并且也会有一个极低的损失值
的预测结果会与真正结果相一致,并且也会有一个极低的损失值![]() 。现在我们将要去介绍第三个也是最后一个关键部分:最优化(optimization)。最优化就是发现能够最小化损失函数值的这组参数W的过程。
。现在我们将要去介绍第三个也是最后一个关键部分:最优化(optimization)。最优化就是发现能够最小化损失函数值的这组参数W的过程。
Foreshadowing(预告):一旦我们理解了这三个核心组件是如何交互的,我们将重温第一个组件(参数化映射函数)然后扩展至比线性函数更加复杂的形式:首先是神经网络,然后是卷积神经网络。而损失函数和最优化处理则相对保持不变。
Visualizing the loss function
本节我们看到的损失函数通常都被定义在高维空间中(e.g. 在CIFAR-10中,一个线性分类器的权重矩阵的大小为![]() ),这很难去可视化。然而,我们可以通过一些方法去获得可视化画面,比如沿着射线(1维)截断高维空间,或者沿着平面(2维)截断高维空间。举个例子,我们可以生成一个随机权重向量(相对于这个空间中的一个点来说),然后沿着一条射线记录一路上的损失函数值。也就是说,我们可以生成一个随机的方向矩阵
),这很难去可视化。然而,我们可以通过一些方法去获得可视化画面,比如沿着射线(1维)截断高维空间,或者沿着平面(2维)截断高维空间。举个例子,我们可以生成一个随机权重向量(相对于这个空间中的一个点来说),然后沿着一条射线记录一路上的损失函数值。也就是说,我们可以生成一个随机的方向矩阵![]() ,然后沿着这个方向计算损失函数值,计算公式为
,然后沿着这个方向计算损失函数值,计算公式为![]() ,以
,以![]() 的值为x轴,以损失函数值为y轴,生成一个点图。我们同样可以用同样的方式来计算两个维度上的损失函数值,计算公式为
的值为x轴,以损失函数值为y轴,生成一个点图。我们同样可以用同样的方式来计算两个维度上的损失函数值,计算公式为![]() ,其中
,其中![]() 为变化参数。在一个图中,
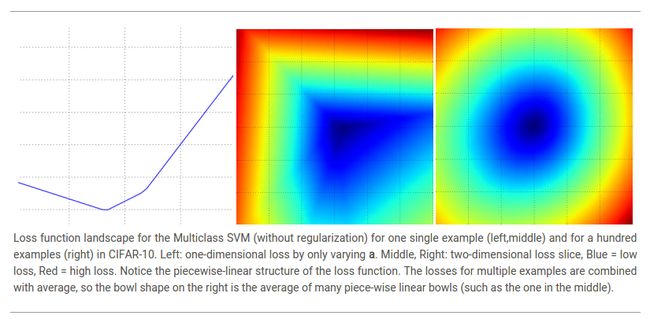
为变化参数。在一个图中,![]() 分别对应于x轴,y轴,然后损失函数值可以通过颜色来可视化:
分别对应于x轴,y轴,然后损失函数值可以通过颜色来可视化:
我们可以通过考察数学式子来解释分段线性结构的损失函数。公式如下:
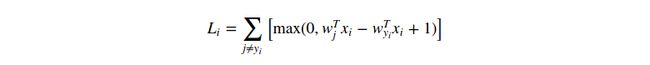
从公式中可以明显看出,每一个样本的数据损失(data loss)就是参数![]() 的线性函数(zero-threshold due to themax(0,-) function)的求和。另外,参数
的线性函数(zero-threshold due to themax(0,-) function)的求和。另外,参数![]() 的每一行
的每一行![]() 有时会是正的(如果这一行相对应于错误的类别),有时会是负的(如果这一行相对应于正确的类别)。让这一过程更加明晰,考虑一个简单的数据集,拥有三个1维点和3个类别。完整的SVM损失(没有规则化)如下:
有时会是正的(如果这一行相对应于错误的类别),有时会是负的(如果这一行相对应于正确的类别)。让这一过程更加明晰,考虑一个简单的数据集,拥有三个1维点和3个类别。完整的SVM损失(没有规则化)如下:
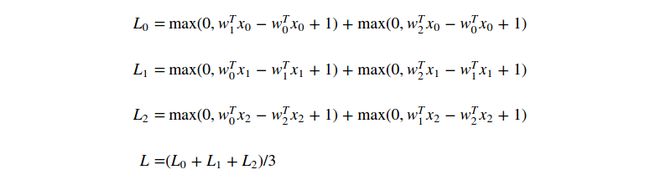
因为这些样本都是一维的,所以数据![]() 和权重
和权重![]() 都是数字。比如,Looking at
都是数字。比如,Looking at ![]() ,some terms above are linear function of
,some terms above are linear function of ![]() and each is clamped at zero. 可视化结果如下:
and each is clamped at zero. 可视化结果如下:
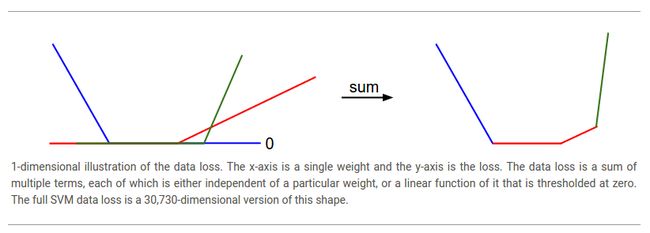
说句题外话,你可能已经从它的碗的形状中看出SVM损失函数是凸函数(convex function)的一个特例。有很多的文献致力于如何最有效的最小化这些函数的类型,你也可以参加Stanford的关于这个主题的课程(convex optimization)。一旦我们把成绩函数![]() 扩展为神经网络,那么我们的损失函数将不再是凸函数,它的可视化图像也不在是碗状而是复杂,崎岖不平的形状。
扩展为神经网络,那么我们的损失函数将不再是凸函数,它的可视化图像也不在是碗状而是复杂,崎岖不平的形状。
Non-differentiable loss functions. 作为一个技术说明,损失函数中的kinks(由于the max operation)使得损失函数不可微,因为在这些kinks上没有梯度。然而,thesubgradient仍然存在并且经常被使用。本节中,我们假定术语subgradient和gradient可以相互替换。
Optimization
重申一遍,损失函数量化了一组特定权重![]() 的质量。最优化的目标是去发现能够最小化损失函数值的那一组权重。我们现在将motivate以及慢慢开发一个方法来优化损失函数。对于之前有过学习的人来说,这一节可能看起来很奇怪,因为我们将使用的工作样本(the SVM loss)是一个凸问题,但是请注意,我们的目标是最终优化神经网络,而神经网络使不能轻易地使用任何凸优化理论开发的工具来优化的。
的质量。最优化的目标是去发现能够最小化损失函数值的那一组权重。我们现在将motivate以及慢慢开发一个方法来优化损失函数。对于之前有过学习的人来说,这一节可能看起来很奇怪,因为我们将使用的工作样本(the SVM loss)是一个凸问题,但是请注意,我们的目标是最终优化神经网络,而神经网络使不能轻易地使用任何凸优化理论开发的工具来优化的。
Strategy #1:A first very bad idea solution:Random search
第一个想到的方法是尝试使用各种不同的权重,然后比较出最好的那一组。流程如下:
# assume X_train is the data where each column is an example (e.g. 3073 x 50,000)
# assume Y_train are the labels (e.g. 1D array of 50,000)
# assume the function L evaluates the loss function
bestloss = float("inf") # Python assigns the highest possible float value
for num in xrange(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)
# prints:
# in attempt 0 the loss was 9.401632, best 9.401632
# in attempt 1 the loss was 8.959668, best 8.959668
# in attempt 2 the loss was 9.044034, best 8.959668
# in attempt 3 the loss was 9.278948, best 8.959668
# in attempt 4 the loss was 8.857370, best 8.857370
# in attempt 5 the loss was 8.943151, best 8.857370
# in attempt 6 the loss was 8.605604, best 8.605604
# ... (trunctated: continues for 1000 lines)在上面的代码中,我们尝试了1000中不同的权重向量
# Assume X_test is [3073 x 10000], Y_test [10000 x 1] scores = Wbest.dot(Xte_cols) # 10 x 10000, the class scores for all test examples # find the index with max score in each column (the predicted class) Yte_predict = np.argmax(scores, axis = 0) # and calculate accuracy (fraction of predictions that are correct) np.mean(Yte_predict == Yte) # returns 0.1555从代码中得知,最好的权重得到的检测精度大约为
Core idea:iterative refinement(迭代求精). 事实证明我们可以得到更好的结果。上面操作的核心思想如下:发现最好的那一组权重是一件很困难或者说是不可能完成的任务(尤其当![]() 包含整个复杂的神经网络的权重的时候),但是如果是去发现一组可以比目前权重所得结果更加好的权重则明显没那么困难。换句话说,我们的方法是以一组随机权重开始,然后不断迭代求精,使得每一次能比前一此好一点即可。
包含整个复杂的神经网络的权重的时候),但是如果是去发现一组可以比目前权重所得结果更加好的权重则明显没那么困难。换句话说,我们的方法是以一组随机权重开始,然后不断迭代求精,使得每一次能比前一此好一点即可。

Blindfolded hiker analogy. 有一个很好的类比,想象你是一个在一个丘陵地形上的旅行者,但你是蒙着眼睛的,这是你想要达到底部。在CIFAR-10中,因为![]() 的维度是30730x10,所以这座山高30730个维度。在山上的每一个维度,你都可以收获一个特定的损失(the height of the terrain)。
的维度是30730x10,所以这座山高30730个维度。在山上的每一个维度,你都可以收获一个特定的损失(the height of the terrain)。
Strategy #2:Random Local Search
你能想到的第一个策略是在任意方向上都尝试迈出一步,只有这个方向能够往下才继续下一步。第二个策略具体如下:我们将以一个随机![]() 开始,生成一个随机的改变值
开始,生成一个随机的改变值![]() ,如果权重
,如果权重![]() 计算得到的损失值更小,那么我们将进行一次权重更新。代码如下:
计算得到的损失值更小,那么我们将进行一次权重更新。代码如下:
W = np.random.randn(10, 3073) * 0.001 # generate random starting W
bestloss = float("inf")
for i in xrange(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)上述步骤同样进行了1000次,而此次在测试图像集上得到的精度为
Strategy #3:Following the Gradient
在前一节我们试图在权重空间中找到一个能够优化权重向量的方向(同时得到一个更小的损失)。事实证明,并不需要去随机搜索这个好的方向:我们可以计算得出这个最好的方向,在数学上可以证明这是一个最速下降的方向(其步长大小接近与0)。这个方向也和损失损失函数的梯度相关。 In our hiking analogy, this approach roughly corresponds to feeling the slope of the hill below our feet and stepping down the direction that feels steepest.
相对于一维函数,这个斜率就是任何一个点的函数瞬时速率的改变。梯度是斜率的泛化表示,不再仅使用单个数字而是用一组向量表示。另外,梯度也就是一组输入空间中每一个维度斜率(通常被称为导数(derivative))的向量。一维函数的导数表达式如下:

当函数的输入为一组向量而不是单个数字时,我们称这些导数为偏导数(partial derivatives),导数就是每一个维度的偏导数的集合。
Computing the gradient
有两种计算梯度的方式:一种缓慢的,近似的但很简单的方式(数值梯度,numerical gradient);另一种快速,精确但容易出错的方式(解析梯度,analytic gradient),它要求微积分。
Computing the gradient numerically with finite differences
上面给出的公式允许我们计算数值梯度。有一个通用的公式,使用一个函数![]() ,在某一个向量
,在某一个向量![]() 上计算梯度。公式如下:
上计算梯度。公式如下:
def eval_numerical_gradient(f, x):
"""
a naive implementation of numerical gradient of f at x
- f should be a function that takes a single argument
- x is the point (numpy array) to evaluate the gradient at
"""
fx = f(x) # evaluate function value at original point
grad = np.zeros(x.shape)
h = 0.00001
# iterate over all indexes in x
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# evaluate function at x+h
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # increment by h
fxh = f(x) # evalute f(x + h)
x[ix] = old_value # restore to previous value (very important!)
# compute the partial derivative
grad[ix] = (fxh - fx) / h # the slope
it.iternext() # step to next dimension
return grad
上面的梯度公式计算了输入向量x的梯度:通过迭代每一维,然后计算损失函数沿着该维的偏导数。到最后,变量![]() 拥有整个梯度值。
拥有整个梯度值。
Practical considerations. 在数学公式中,梯度指的是在变量增长![]() 趋向于0的情况下,函数的改变量,但在实际生活中,只需设置
趋向于0的情况下,函数的改变量,但在实际生活中,只需设置![]() 为一个很小的值即可(比如
为一个很小的值即可(比如![]() 即可)。而在理想情况下,你想要去使用一个最小的步长(不会导致数值问题)。另外,实际生活中使用中心差分公式(the centered difference formula)来计算数值梯度效果更好:
即可)。而在理想情况下,你想要去使用一个最小的步长(不会导致数值问题)。另外,实际生活中使用中心差分公式(the centered difference formula)来计算数值梯度效果更好:![]() 。具体细节请看wiki。
。具体细节请看wiki。
我们可使用上面的公式来计算任何公式的任何一个具体点的梯度。下面在CIFAR-10上计算某几个随机点的损失函数的梯度:
# to use the generic code above we want a function that takes a single argument # (the weights in our case) so we close over X_train and Y_train def CIFAR10_loss_fun(W): return L(X_train, Y_train, W) W = np.random.rand(10, 3073) * 0.001 # random weight vector df = eval_numerical_gradient(CIFAR10_loss_fun, W) # get the gradient梯度告诉我们损失函数在每个维度上的斜率,所以我们可以使用梯度进行权重更新:
loss_original = CIFAR10_loss_fun(W) # the original loss print 'original loss: %f' % (loss_original, ) # lets see the effect of multiple step sizes for step_size_log in [-10, -9, -8, -7, -6, -5,-4,-3,-2,-1]: step_size = 10 ** step_size_log W_new = W - step_size * df # new position in the weight space loss_new = CIFAR10_loss_fun(W_new) print 'for step size %f new loss: %f' % (step_size, loss_new) # prints: # original loss: 2.200718 # for step size 1.000000e-10 new loss: 2.200652 # for step size 1.000000e-09 new loss: 2.200057 # for step size 1.000000e-08 new loss: 2.194116 # for step size 1.000000e-07 new loss: 2.135493 # for step size 1.000000e-06 new loss: 1.647802 # for step size 1.000000e-05 new loss: 2.844355 # for step size 1.000000e-04 new loss: 25.558142 # for step size 1.000000e-03 new loss: 254.086573 # for step size 1.000000e-02 new loss: 2539.370888 # for step size 1.000000e-01 new loss: 25392.214036Update in negative gradient direction. 在上面的代码中,我们利用梯度值更新权重
Effect of step size. 梯度告诉我们函数可以增长最快的方向,但并没有告诉我们沿着这个方向应该走多远。在本门课程之后会讲到,步长的选择是训练一个神经网络最重要的超参数设定问题之一。在之前蒙眼下山的类比中,我们能感觉到山坡有一个倾斜的方向,但我们应该跨出的步长并不确定。如果我们小心翼翼地挪动脚步,为了有一个正确但很小的进步(这相对应于有一个小的步长)。相反,我们可以大步向下降最快的方向前进,但这样的效果可能不一定好。从上面的代码例子中可以看出,在某一些点上如果步长太大,会产生一个更高的损失就好像我们“overstep”。
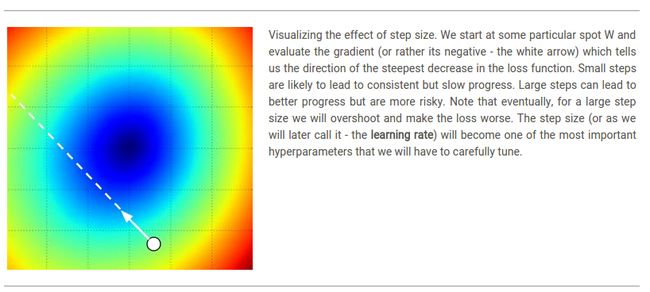
A problem of efficiency. 你可能已经注意到,计算数值梯度的复杂性和参数个数之间呈线性关系。在我们的例子中,我们共有30730个参数,因此我们必须执行30731次损失函数计算后才能计算得出梯度值,也才能进行一次参数更新。这个问题会变得更加糟糕,因为现在的神经网络的参数轻易就可以达到上百万个。确切的说,这种方法是不可延续的,所以我们必须找到其他更好的办法。
Computing the gradient analytically with Calculus
数值梯度通过有限差分逼近方式易于计算,但缺点是它是近似的(因为我们会选择一个小的h值,而在梯度公式中,h的值被定义为趋近于0),并且计算量非常大。计算梯度的第二种方式是微积分,它允许我们直接推导出梯度(不是近似的),并且可以快速的进行计算。然而,它在应用过程中更容易出错,所以实际使用时,常用做法是计算解析梯度,然后和数值梯度进行比较来判断是否正确。这个步骤称为梯度检查(gradient check)。
单个数据点的SVM损失函数公式如下:
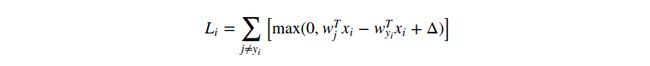
我们可以微分这个函数。举个例子,计算![]() 的梯度,公式如下:
的梯度,公式如下:
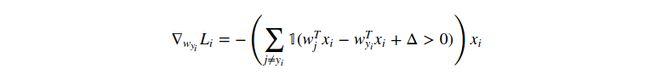
其中![]() 是一个指示函数,如果条件表达式为true,则输出条件表达式的值;否则,输出为0。上面表达式看起来很难记,但只要你代码实现它,你就会发现很容易去统计不符合预期的类别的数目(and hence contributed to the loss function),并且数据向量
是一个指示函数,如果条件表达式为true,则输出条件表达式的值;否则,输出为0。上面表达式看起来很难记,但只要你代码实现它,你就会发现很容易去统计不符合预期的类别的数目(and hence contributed to the loss function),并且数据向量![]() 被缩放的值就是梯度。注意,这个梯度值仅仅相对应于权重
被缩放的值就是梯度。注意,这个梯度值仅仅相对应于权重![]() 的某一行(相对应于正确类别的)。For the other rows where
的某一行(相对应于正确类别的)。For the other rows where ![]() the gradient is:
the gradient is:
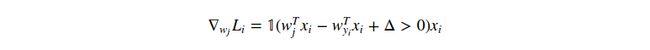
如果你理解了上面的梯度公式,那么就可以直接应用这个表达式去执行梯度更新。
Gradient Descent
现在我们能够计算损失函数的梯度。反复计算梯度,然后进行梯度更新的过程称为梯度下降(Gradient Descent)。Its vanilla version 如下:
# Vanilla Gradient Descent while True: weights_grad = evaluate_gradient(loss_fun, data, weights) weights += - step_size * weights_grad # perform parameter update这个简单的循环是所有神经网络库的核心。还有其他的方式可以执行最优化操作(e.g. LBFGS),但是梯度下降是目前优化神经网络的损失函数的最常用的方式。本节课中,我们会在这个循环中添加一些额外的功能(put some bells and whistles on the details of this loop)(e.g. 更新等式的确切细节),但是核心思想并没有改变。
Mini-batch gradient descent. 在大规模的应用中(比如ILSVRC挑战),训练数据可能以百万计。因此,为了执行一次参数更新而计算整个训练集的损失函数显得有点浪费。解决这一问题的常用方法是批量处理训练数据的梯度。举个例子,in current state of the art ConvNets,整个训练集共120万个样本,典型的批量处理的数量为256。下面为批量处理参数更新的代码:
# Vanilla Minibatch Gradient Descent while True: data_batch = sample_training_data(data, 256) # sample 256 examples weights_grad = evaluate_gradient(loss_fun, data_batch, weights) weights += - step_size * weights_grad # perform parameter update这种方式能够得到好的结果的原因是因为训练数据都是相关的。要了解这一点,考虑一个极端的情况,就是ILSVRC上的120万个图像事实上是由1000张不同的图片复制而得到的(一张图片对应一个类,或者每张图片有1200张相同的复制)。很明显,我们计算的1200个相同副本的梯度都是一样的,and when we average the data loss over all 1.2 million images we would get the exact same loss as if we only evaluated on a small subset of 1000。实际上,数据集并不会拥有重复的图片,小批量的梯度是对所有损失函数的梯度的一个很好的近似。因此,通过计算小批量梯度来执行更频繁的参数更新,可以更快的收敛。
批量更新的最极端的例子是批量处理的数目仅为一个样本。这个过程称为随机梯度下降(Stochastic Gradient Descent,SGD)(有时也称为在线梯度下降(on-line gradient descent))。不过在实际使用中并不多见,因为矢量代码优化,一次计算100个样本的梯度比计算100次单个样本的梯度更有效率。尽管技术上来说,SGD表示一次仅计算一个样本的梯度,但是实际上人们使用SGD表示小批量梯度更新(i.e. MGD指“小批量梯度更新”,BGD表示“批量梯度更新”,这些不太使用)。小批量的大小是一个超参数,但是通常不需要交叉验证来得到。它通常是基于内存约束(if any),或者设定一些值,比如32,64或者128。We use powers of 2 in practice because many vectorized operation implementations work faster when their inputs are sized in powers of 2.
Summary
本节中
1)我们开发一个高维优化山坡(high-dimensional optimization landscpe)去可视化损失函数,我们的目标是尽量去到达底部。我们开发的类比是一个蒙着眼睛的徒步旅行者想要达到山底。特别的,我们看到SVM损失函数是分段线性的,而且是碗状的。
2)我们说明了通过迭代求解(iterative refinement)的方式来优化损失函数的想法,即我们以一组随机权重开始,逐步求解,直到损失值是最小的。
3)我们知道了函数的梯度(gradient)是最快上升的方向,我们讨论了用有限差分逼近的方式来数值计算梯度,这种方式简单却效率不高(the finite difference being the value of h used in computing the numerical gradient)。
4)参数更新过程中,步长(step size,或者称为学习速率,the learning rate)是一个略带技巧性的设置:如果太低,那么进展很慢;如果太高,进展可以更快,但是风险更大。我们在后面还会更加详细的讨论这个事情。
5)我们讨论了数值梯度(numerical)计算和解析梯度(analytic)计算之间的权衡。数值梯度很简单,但是它是近似计算,而且计算量很大。解析梯度计算准确,速度快,但是需要梯度推导,反而更容易出错。实际上,我们经常使用解析梯度,然后进行梯度检查(gradient check),就是和数值梯度比较效果。
6)介绍了梯度下降算法:在一个循环中不断迭代计算梯度,然后进行梯度更新。
Coming up:本节的核心思想就是计算损失函数的梯度,自变量为权重。下一节我们将使用链式法则提高解析梯度计算的效率,或者称为反向传播(backpropagation)。This will allow us to efficiently optimize relatively arbitrary loss functions that express all kinds of Neural Networks, including Convolutional Neural Networks.