简单有道词典客户端C实现
参考链接 :
http chunked : http://blog.csdn.net/yaneng/article/details/4378984
zlib压缩和解压gzip : http://www.oschina.net/code/snippet_65636_22542
请多多支持以上作者,谢谢...
前几天写了这个主题,但是那个时候思路不清晰,写的乱七八糟.写博客为的就是理清思路.并且程序的bug也有很多,实在误人误己,所以删掉之前的那篇,从新写一篇.
遗憾上传的附件没有办法删除.
背景
linux下并没有什么比较牛的翻译软件,之前youdao倒是做了一个,但是有个细节处理的不是很好,正好挡住vim的状态栏最右边的一部分,导致组合命令用起来很不方便,就放弃了.但是最近总是看英文文档,对翻译软件的需求还是有的.所以就萌生了一个自己做一个的想法.用了一个星期,总算初见成效.
设计思路
1. 解析域名连接服务器.
这一步比较简单,调用几个API就可以了.
代码片段 :
// 域名对应IP
struct hostent *ent;
ent = gethostbyname(host);
if (NULL == ent || NULL == *ent->h_addr_list)
{
perror("\n");
return -1;
}
// 非阻塞连接服务器
int ret = 0;
int flag = 0;
int sockfd = 0;
struct sockaddr_in addr;
sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (-1 == sockfd)
{
perror("\n");
return -1;
}
addr.sin_family = AF_INET;
addr.sin_port = htons(80);
addr.sin_addr.s_addr = naddr;
flag = fcntl(sockfd, F_GETFL, 0);
ret = fcntl(sockfd, F_SETFL, flag | O_NONBLOCK);
if (ret < 0)
{
close(sockfd);
return -1;
}
ret = connect(sockfd, (struct sockaddr*)&addr, sizeof(struct sockaddr_in));
if (ret < 0)
{
if (errno != EINPROGRESS)
{
close(sockfd);
perror("\n");
return -1;
}
}
else if (ret == 0)
{
goto DONE;
}
fd_set wset;
fd_set tmpset;
struct timeval tv;
FD_ZERO(&wset);
FD_SET(sockfd, &wset);
tv.tv_sec = 10;
tv.tv_usec = 0;
while (1)
{
tmpset = wset;
ret = select(sockfd + 1, NULL, &tmpset, NULL, &tv);
if (ret < 0)
{
if (EINTR == errno)
{
continue;
}
else
{
close(sockfd);
perror("\n");
return -1;
}
}
else if (0 == ret)
{
close(sockfd);
return -1;
}
break;
}
DONE:
return sockfd;
2. 构造消息发送请求.
我并不知道该给有道发什么消息,所以就在网页上面翻译了一个单词,通过wireshark查看,去掉cookie等信息如下:
POST /translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null HTTP/1.1\r\n\ Host: fanyi.youdao.com\r\n\ Connection: keep-alive\r\n\ Content-Length: %d\r\n\ Accept: application/json, text/javascript, */*; q=0.01\r\n\ Origin: http://fanyi.youdao.com\r\n\ X-Requested-With: XMLHttpRequest\r\n\ User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36\r\n\ Content-Type: application/x-www-form-urlencoded; charset=UTF-8\r\n\ Referer: http://fanyi.youdao.com/\r\n\ Accept-Encoding: gzip, deflate\r\n\ Accept-Language: en-US,en;q=0.8\r\n\ \r\n\ type=AUTO&i=%s&doctype=json&xmlVersion=1.8&keyfrom=fanyi.web&ue=UTF-8&action=FY_BY_CLICKBUTTON&typoResult=true";
分析一下这个请求可以发现
a. 服务器给我们返回的是json的格式.我们得支持gzip压缩.
b. i=%s : 这里就是我们要存放翻译原文的地方.如果是英文,直接原文即可,但是对于汉字,这里的处理有点特别.一个中文的utf-8是三个字节,但是有道的请求里面,一个中文占六个字节,比如快乐 :正常的utf-8编码应该是 %E5%BF%AB%E4%B9%90 , 但是有道里面是这个样子的%C3%A5%C2%BF%C2%AB%C3%A4%C2%B9%C2%90 .网上搜了很久都没有找到问题的原因,后来FQ用谷歌找到了问题的答案,原来是因为js的一个函数EncodeURI,这个函数会把汉字给转成6个字节.对应表在代码的encoding.h里面,
c. 其实这里我被浏览器坑了,Accept-Encoding这个,如果不加,有道会返回一个非gzip压缩的明文格式,结果我刚开始不知道,以为是必须的,然后就有了各种纠结解压缩.不过好处当然也显而易见,对zlib又有了新的理解.d. 另外就是有道也在这里坑了一把,明明我有keep-alive,结果它并没有,每次请求完,它立刻关闭连接.导致我下一次请求直接RST了.这个异常的处理方式是,如果write失败,就退出.
参考unp,写一个关闭的套结字会收到RST,如果不管这个RST继续写入,程序就会崩溃,因为收到了SIGPIPE,如果不想被异常终止,需要捕获SIGPIPE,或者忽略它.
3. 接收应答,解出header和body
这里很明显我的设计存在一个bug的,我只固定读取了给定大小.因为我的场景不会有大篇幅的翻译.
如果说需要大篇幅,那么正确的做法应该是申请一个大buffer,接收数据,根据chunked判断有没有到达消息尾部,如果没有到达而buffer满了,先追加到某个文件里面,继续读...
4. 解chunk消息.得到压缩的应答正文.
关于chunked,文首的连接想必说的很清楚了,明确chunked格式,还是不难解的,比较坑爹的地方是,每一段chunked长度是用ascii码保存的.我开始理解错了,以为是直接转成数字就可用,结果走了一段弯路.参考代码片段 :
int i = 0;
int len = 0;
int power = 0;
int dec = 0;
int seed = 0;
len = strlen(hex);
for (i = len - 1; i >= 0; i--)
{
power = len - i - 1;
switch (hex[i])
{
case '0':
{
seed = 0;
}
break;
case '1':
{
seed = 1;
}
break;
case '2':
{
seed = 2;
}
break;
case '3':
{
seed = 3;
}
break;
case '4':
{
seed = 4;
}
break;
case '5':
{
seed = 5;
}
break;
case '6':
{
seed = 6;
}
break;
case '7':
{
seed = 7;
}
break;
case '8':
{
seed = 8;
}
break;
case '9':
{
seed = 9;
}
break;
case 'a':
{
seed = 10;
}
break;
case 'b':
{
seed = 11;
}
break;
case 'c':
{
seed = 12;
}
break;
case 'd':
{
seed = 13;
}
break;
case 'e':
{
seed = 14;
}
break;
case 'f':
{
seed = 15;
}
break;
default:
break;
}
dec += seed * pow(16, power);
}
return dec;
5. 解压,得到json字符串.
关于解压缩,我就不过多描述了,参考我的另一片文章,借鉴了很多网友的成果,还是有一定参考性的.
http://blog.csdn.net/cp3alai/article/details/51282338
6. 解析json字符串.
网上参考了很多的博文,结果都看不懂,实在是因为我对json也没那么了解,所以就首先对json做了一下入门,参考 : http://www.w3school.com.cn/json/解析工具选择了cJSON, 源码路径 : https://github.com/DaveGamble/cJSON.git .这里面的例子 test.c 很清晰易懂.
我本来想再封装一层,无奈又是object又是数组,需要调用的方法又不一样,失败.只能傻瓜一样,按顺序找到我需要的解释.
需要完善的地方:
1. 接收数据的缓冲区写死了,如果需要翻译的数据足够大,可能就完蛋了.
2. html是chunked的格式,但是我只解了第一个chunk,如果需要翻译的数据足够大,还是会有问题的.
使用如图 :
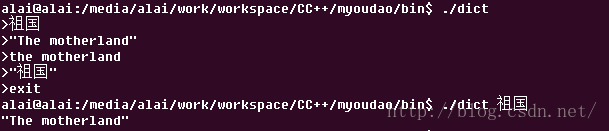
更新了以后,稳定多了,原来上传的那个没有办法删除,只能从新再传一个了...
http://download.csdn.net/detail/cp3alai/9509158