如何使用免费PDF第三方插件从PDF文档中提取文本和图片
现在手头的项目有一个需求是从PDF文档中提取文本和图片,我以前也使用过像iTextSharp, PDFBox 这些免费的PDF插件,可是这次都测试了一下,或多或少有一些地方不是很满意。最后同事推荐我使用免费的Spire.PDF,最后发现结果简直是让我惊喜。最重要的是,作为一家中国企业,他们还能提供完全没有时差的中文免费技术支持。所以迫不及待的想和大家分享一下我的使用经验。
开发环境需求:
首先,从Codeplex官网下载免费的Spire.PDF : http://freepdf.codeplex.com/安装好程序后,添加Spire.License.dll,Spire.Pdf.dll 这两个引用到我们的工程程序。免费Spire.PDF支持.NET 2.0--.NET4.5版本。根据自己的项目需求添加相应文件夹里的dlls就可以。

操作步骤:
前面提到过,我的需求是从PDF文档里将文本和图片单独获取出来。使用Spire.PDF,只需要几行代码就能完成这个需求。下面是详细的操作步骤。
1.生成一个PDF,画文本和图片到PDF里面。
2.从PDF文档中提取所有图片。
3.从PDF文档中提取所有文本。
下面的代码示例是讲如何创建一个空的PDF文档,将文本和图片加进PDF.
PdfDocument doc = new PdfDocument();
PdfPageBase page = doc.Pages.Add();
//Add Text
page.Canvas.DrawString("Demo of extract text and imgae from PDF!";
new PdfFont(PdfFontFamily.Helvetica, 20f);
new PdfSolidBrush(Color.Black), 10, 10);
//Add Picture
PdfImage image = PdfImage.FromFile("pdf.png");
float width = image.Width * 0.75f;
float height = image.Height * 0.75f;
float x = (page.Canvas.ClientSize.Width - width) / 2;
page.Canvas.DrawImage(image, x, 60, width, height);
PdfImage image2 = PdfImage.FromFile("image.jpg");
width = image2.Width * 0.75f;
height = image2.Height * 0.75f;
page.Canvas.DrawImage(image2, x-100, 220, width, height);
doc.SaveToFile("sample.pdf");
生成的PDF文件
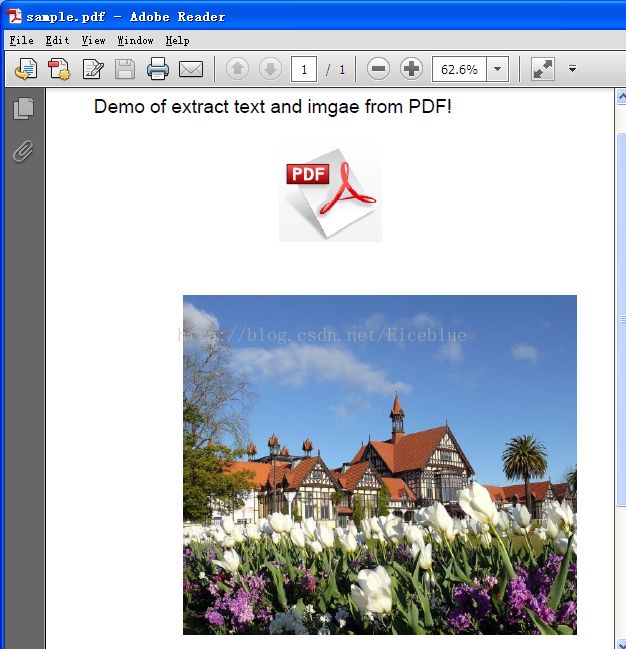
下面的代码将显示如何从PDF文档中获取图片。同样,也只需要几行代码。
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("sample.pdf");
IList<Image> images = new List<Image>();
foreach (PdfPageBase page in doc.Pages)
{
if (page.ExtractImages() != null)
{
foreach (Image image in page.ExtractImages())
{
images.Add(image);
}
}
}
doc.Close();
int index = 0;
foreach (Image image in images)
{
String imageFileName = String.Format("Image-{0}.png", index++);
image.Save(imageFileName, ImageFormat.Png);
}
运行后,所有的图片被保存为了.png格式。在debug文件夹里可以看到我们获取的PDF文档中的两幅图像。

下面的代码将显示如何从PDF文档中提取文本。同样,也只需要几行代码。
PdfDocument doc = new PdfDocument();
doc.LoadFromFile("sample.pdf");
StringBuilder buffer = new StringBuilder();
foreach (PdfPageBase page in doc.Pages)
{
buffer.Append(page.ExtractText());
}
doc.Close();
String fileName = "TextInPdf.txt";
File.WriteAllText(fileName, buffer.ToString());
buffer = null;
提取的文本被保存为了.txt文档。详情见截图:
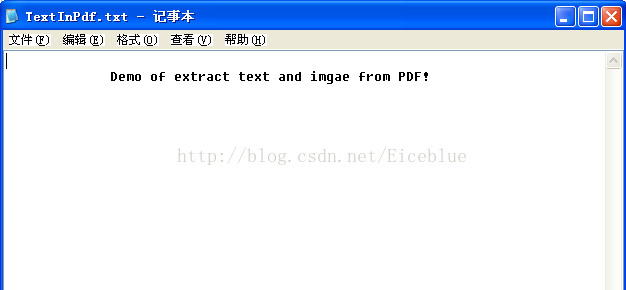
总结:
总的来说,网上有很多第三方PDF插件来操作PDF文档。Free Spire.PDF的优点在于免费,易用,大大节省了开发者的时间。但是免费版本在加载和写出时,PDF页面被限制在了十页以内。不过这已经足够我的项目需要了。如果你的项目超出限制,也有收费版Spire.PDF可以使用。官方提供30天免费试用。