Kafka安装测试
1、简介

![]()
![]()
![]()



Kafka是一个分布式消息队列,是一个能把消息存在不同节点上的企图实现高吞吐量的MQ(message queue)。粗略的讲,对于我们实验室的项目,Kafka是作为一个消息缓存机制存在,而看网上博客和官网一些描述其实也差不多是这个用处。对于我们“Flume+Kafka+storm”的平台,因为Flume模拟流数据源的发送速度是不稳定的,时快时慢,而且如果Flume的发送速度过快(这种情况十分常见),往往storm来不及处理,这样有些消息可能就会被丢弃。Kafka的角色就是处于两者之间的一个缓存,而且数据是写入磁盘,保证消息在系统正常关闭启动的情况下不会丢失,很好的适用于实时和离线的数据处理。
下面是官网的一张描述Kafka集群的简单架构图:
整个Kafka集群有几个重要组成部分,包括生产者producer,Kafka集群的broker,消费者consumer。Kafka的官方文档内容丰富而详细,包括对这些概念的介绍以及对每一个组件或者系统的配置参数都很具体,详情可戳 http://kafka.apache.org/082/documentation.html (1)
topic :topic是一个消息的基本单位,而具体的data存放位置由配置文件定义,可能存放在不同的分区partition
broker :这是Kafka cluster的基本单位,集群中可能有一个或者多个broker服务,用来负责生产者和消费者的消息处理和交互
producer :即生产者,用来发布topic的进程。后面会介绍producer作为接口实现为上游数据源Flume的sink,具体实现在整合Flume和Kafka的时候会解释
consumer :即消费者,用来订阅(消费)topic的进程,同时还可以有消费组,这样生产者发布topic的时候可以1)只对某些id或者组id的消费者发布消息2)广播发布给所有消费者
Kafka需要zookeeper的协调,zookeeper与producer,consumer,broker之间是通过TCP协议通讯的。
2、部署安装
目前最新的稳定版本是0.8.0.1,最新的发布版本是0.8.2的,地址 http://kafka.apache.org/downloads.html (2)
,下载并解压到你自选的目录路径下,在这之前机器上已经先安装了单机版zookeeper和scala。
修改配置文件。在文档(1)中有详细的说明,对于我自己的情况,producer.properties和consumer.properties文件都保留默认配置,只修改了broker的server.properties和zookeeper.properties的设置。
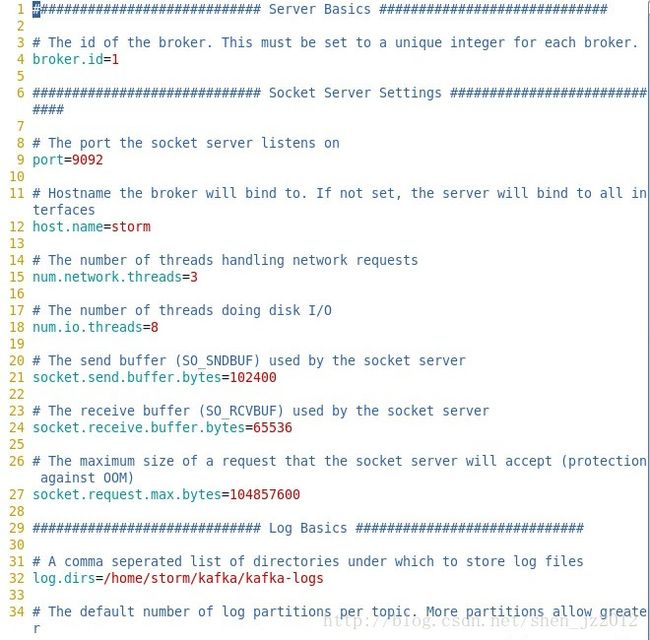
第4行的broker.id是一个唯一的全局正数
第9行写上端口号,官方文档默认值为9092
第11行写上机器的主机名
第32行写上保存数据的地方,不仅是日志文件数据,每个topic都会有相应文件夹,里面有topic的消息数据,这些都在log.dirs定义的这个目录下。因此不能用默认的/tmp/kafka-logs,原因是每次机器重启,/tmp目录下的很多数据都会被当做临时文件删掉,部署任何分布式系统都要记得修改以/tmp目录作为数据存放位置的配置。
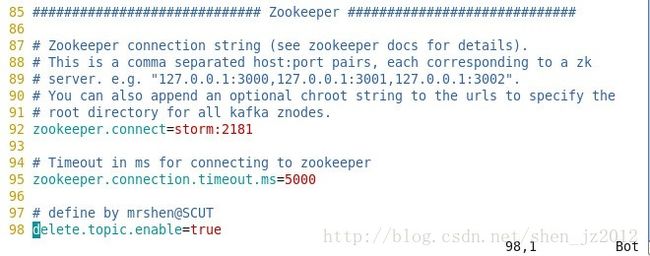
第98行是我自己添加上去了,如果不写上这一行,系统默认delete.topic.enable值为false。这样你在删除topic的时候无法删除,但是会打上一个你将删除该topic的标记,等到你修改这一属性的值为true后重新启动Kafka集群的时候,集群自动将那些标记删除的topic删除掉,对应的log.dirs目录下的topic目录和数据也会被删除。而将这一属性设置为true之后,你就能成功删除你想要删除的topic了。
zookeeper.properties文件的配置跟部署zookeeper的配置差不多,就不贴出来了,主要是修改里面的dataDir和dataLogData的目录路径。
3、测试
1)开启zookeeper服务,这一步可能要用到超级用户权限
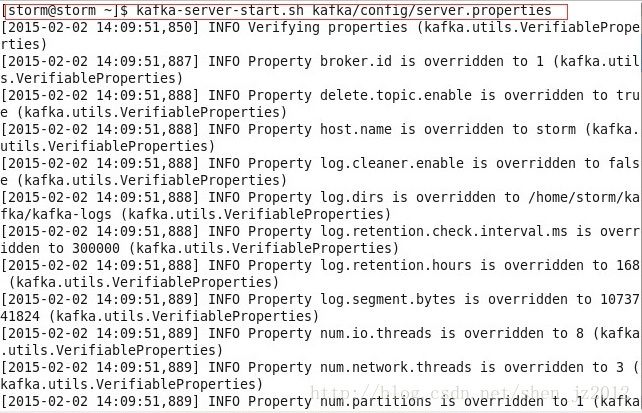
2)开启kafka broker服务,需要指定具体的配置文件,如下图:
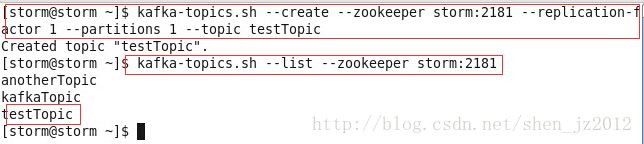
3)创建一个名叫testTopic的topic并查看
创建的时候--replication-factor参数有多少个broker数目就为几;--partitions为分区数;--topic后面写topic的名字。
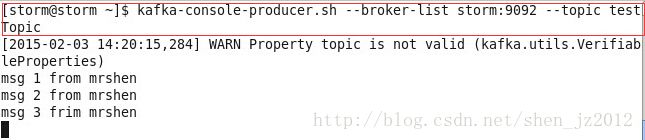
4)在终端开启一个producer进程,并在其启动完成之后开始写入数据(本例中写了3条数据)。
5)在另一个终端开启一个consumer进程,订阅topic “testTopic”
可以看到成功接收到topic的消息数据。其中,--from-beginning参数指定该消费者把该topic所有的消息都读取出来。如果此时我们关掉生产者和消费者,重新开启生产者对这个topic写入数据,则开启订阅该topic的消费者时,会将该topic刚写入的和之前的所有消息数据一定输出。
开启另一个消费者而不指定从beginning处读取消息,则消费者只实时接收生产者的消息。
Kafka的简单测试基本就是这样。复杂点的是实现producer API和simpleconsumer API,wiki地址 https://cwiki.apache.org/confluence/display/KAFKA/Index%3bjsessionid=F5082C8EEB352CC69A1C721AA18CD1EB