有关Cassandra的数据划分
当启动一个Cassandra集群的时候,必须选择如何在集群中的不同节点之间划分数据。这是由Cassandra的partitioner来完成的。
在Cassandra中,Cassandra所管理的数据构成了一个环。这个环根据节点的数量划分成相等的区间,这样一个节点就可以负责存储一个区间或者几个区间中的数据。在一个节点能够加入到环中之前,它必须被分配一个token(中文翻译为令牌)。token决定了节点在环中的位置,从而也决定了节点负责管理的数据范围。
数据根据行键(row key)被划分到不同的节点上。为了确定第一个复本所在的节点,需要在环上顺时针的查找,直到找到一个token的值大于等于行键。每一个节点负责管理前面找到的token和它之前的一个token之间的数据,一个左开右闭的区间。所有的节点都是按照token的顺序来的,最后一个节点是第一个节点的前趋节点,所以,就构成了一个环。
举例,考虑一个简单的集群,有四个节点,管理的数据的key从0-100。每一个节点都会分配一个token,这个token就是这个范围中的一个点。在这个简单的例子中,token分别是0,25,50,75。的第一个节点,也就是token为0的节点,负责管理(75,0]范围内的数据。这个范围包括了最小的token和最大的token。

关于多数据中心的数据划分
在多数据中心部署的情况下,数据放置策略采用的是NewworkTopologyStrategy。在每一个数据中心中,第一个复本所存储的节点是由分配给节点的token决定的。而剩下的复本,沿着环顺时针查找不同的机架上的节点进行存储。
通过下图,我们可以看出合理计算token对数据均匀分布的重要行:
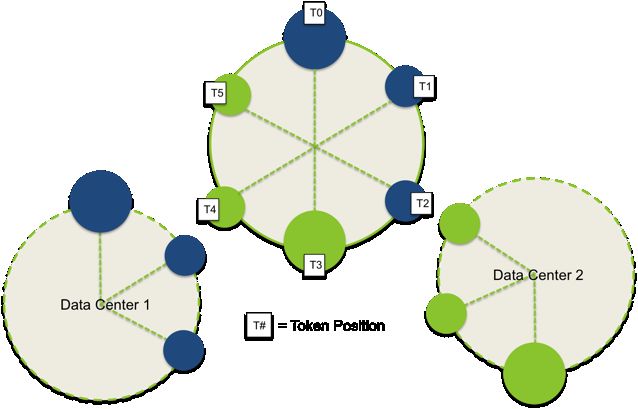
目标就是确保每一个数据中心的token的分配均匀的划分了整个数据。否则就会出现数据中心的某些节点数据的数量不合适。每一个数据中心,都应该当作一个独立的环来处理。具体可以参照前一篇博客来计算token。

理解不同的划分类型
非常不幸,与其他的Cassandra的配置不同,Cassandra的partitioner一旦设定,就不能够修改,除非数据要全部加载,这是非常耗时的。所以在初始化集群的时候,选择正确的划分方法,是至关重要的。
有关随机划分方法(Radom Partitioner)
RandomPartitioner是默认的划分策略,并且在大多数情况下,也是正确的选择。
RandomPartitioner使用一致性hash算法来决定由哪个节点存储数据。与按节点数量取模的方法不同,一致性hash保证了当有新的节点加入到集群中的时候。影响到的数据是最少的。
为了使数据能够在众多节点之间分布均匀,会使用一个hash算法对每个key计算得到一个md5 hash值——这个值的范围是0-2^127之间。然后,每个节点会分配一个token值,具有小于这个token的hash值的那些行就存储在这个节点上。针对单个数据中心的情况,根据节点的数量平均划分0-2^127即可。如果是多个数据中心,每个数据中心独立计算。
这个方法主要的好处是,只要合理的设置了token,那么所有column family的数据就会均匀的分布在各个节点上,而不需要额外的工作。举例说明,尽管有的column family使用的是user name为key,有的是使用时间戳为key,但是这个并不妨碍每个column family在各个节点上均匀分布,从而所有的column family完成均匀分布。
这个划分方法带来的另一个好处是更加简单的实现负载均衡。环中的每一部分几乎得到相同数量的数据,那么新加入一个节点,也会很容易的处理。
有关有序的划分方法
有序的划分方法保证了key是全局有序的。如果不是又明确的需求要求有序,我们强烈推荐使用随机的划分方法。
使用有序的的划分方法,可以让你按行进行扫描数据,就好像有一个索引一样,你可以按序扫描数据。例如,使用有序的划分方法可以提供范围查询,你可以查找用户名字在Jake和Joe之间的用户。随机划分方法就不可以了,随进方法对原始的key进行了md5,顺序已经不是原来字符串的顺序了。
尽管使用有序的划分可以进行范围查询,但是通过其他的手段,比如对column family创建索引,可以达到同样的目标。大多数的应用可以设计数据模型支持列之间的范围查找,而不是去扫描多行数据。
下面的情况,不适宜使用有序的划分方法。
- 有序写会导致热点集中:如果应用程序往往会写入或者更新某一些有序的数据,这样会因为有序的划分方法,使得写入或者更新集中在某几个节点上,使得集群负载不均衡。这个问题在以时间戳作为key的时候,更加频繁。
- 带来更多的使集群负载均衡的管理成本:使用有序的划分方法,需要管理员手工的估计key的范围,而且往往是不准确的。而且,在实际过程中,需要不断的调整以达到集群负载均衡。
- 当有多个column family的时候,全部达到负载均衡比较苦难。因为一种排序方式,往往满足了一个column family的key,却不能满足另外一个。
内置的有三种有序的划分策略。Cassandra0.7以后,OrderPreservingPartitioner和CollatingOrderPreservingPartitioner已经不推荐使用,不过推荐ByteOrderedPartitioner。
- ByteOrderedPartitioner:数据是按照原始字节排序的,而不是把字节转化为字符串之后再排序。Token的计算是根据每个key的实际值和使用16进制表示之后的前几个字符。如果想要按照字母序进行划分,就用A的十六进制表示41代表A Token。
- OrderPreservingPartitioner:使用UTF-8进行编码,存储也是采用UTF-8的顺序
- CollatingOrderPreservingPartitioner:采用EN_US顺序存储,UTF-8方式编码