yale_OS(7)——xv6中的文件系统(File System)
一、概述
文件系统的作用:组织和存储数据。
文件系统的特性:
1)支持在用户和应用中间共享数据;
2)数据持久存在,当系统重启后,数据仍然可用。
xv6文件系统提供类Unix的文件(files)、目录(directory)、路径(pathnames),持久保存数据在IDE磁盘上。
那么文件系统主要解决如下几个难题:
1)文件系统需要磁盘上的数据结构来表示命名的目录和文件的树结构,来记录保存各个文件内容的块身份,同时记录磁盘上哪些块是空闲的。
2)文件系统必须支持故障修复功能(crash recovery),就是说,如果有故障产生(如掉电),那么重启后,文件系统必须仍能正确的工作。存在的风险就是故障可以中断一些列的更新和让磁盘上的数据结构不一致(例如,块(block)同时被一个文件使用和标志为空闲)。
3)不同的进程可能会在同一时间操作文件系统,因此必须协调好来维持不变。
4)访问磁盘比访问内存慢几个数量级,因此文件系统必须维持一个常用块(block)的内存中cache。
xv6文件系统的实现按6层来组织,如下图所示:

图1 xv6文件系统的的层结构
Buffer cache层的作用是:通过Buffer cache来对IDE磁盘上的块(blocks)进行读写,当同时访问一磁盘块时,必须确保每一次只有一个内核进程可以编辑存储在仍能块上的文件系统数据。
Logging层允许较高层在事务处理时打包一些块的更新,以确保这些块能原子地被更新。(例如,他们都被更新或都不更新)。
Inodes和Block Allocator层:提供未命名的文件,各个用一个inode和保存文件数据的一系列块来表示。
Directory inodes层:实现目录作为一些特殊类型的inode,其内容是一系列的目录进入点,各个包含一个名字和命名的文件inode 的引用。
Recursive lookup提供多层次的路径名,像/usr/rtm/xv6/fs.c,使用循环查询
File Descriptors层:使用文件系统接口来抽象很多的Unix资源(像,Pipe,Devices,Files等等),来简化应用程序员的工作。
文件系统必须安排好在磁盘上哪里存储inodes和内容块。为此,xv6把磁盘分为几个分区(sections)。如下图2所示,文件系统不适用block 0(其中保存的是boot sector),block 1被称为superblock,它包含文件系统的元数据(metadata)(块中文件系统大小,数据块数目,inodes数目,在log中块数据)。块(blocks)从2开始保存inodes,伴随每一个block有多有inodes。随后是bitmap块用来跟踪哪些块在使用。剩下来的大多部分块是数据块,其中保存的是文件和目录内容。磁盘的末尾块保存一log,其是transaction层的一部分。
![]()
图2 xv6文件系统结构。
在 头文件fs.h中包含了描述文件系统具体鞥的常量和数据结构。如下:
// On-disk file system format.
// Both the kernel and user programs use this header file.
// Block 0 is unused.
// Block 1 is super block.
// Blocks 2 through sb.ninodes/IPB hold inodes.
// Then free bitmap blocks holding sb.size bits.
// Then sb.nblocks data blocks.
// Then sb.nlog log blocks.
#define ROOTINO 1 // root i-number
#define BSIZE 512 // block size
// File system super block
struct superblock {
uint size; // Size of file system image (blocks)
uint nblocks; // Number of data blocks
uint ninodes; // Number of inodes.
uint nlog; // Number of log blocks
};
#define NDIRECT 12
#define NINDIRECT (BSIZE / sizeof(uint))
#define MAXFILE (NDIRECT + NINDIRECT)
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEV only)
short minor; // Minor device number (T_DEV only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
// Inodes per block.
#define IPB (BSIZE / sizeof(struct dinode))
// Block containing inode i
#define IBLOCK(i) ((i) / IPB + 2)
// Bitmap bits per block
#define BPB (BSIZE*8)
// Block containing bit for block b
#define BBLOCK(b, ninodes) (b/BPB + (ninodes)/IPB + 3)
// Directory is a file containing a sequence of dirent structures.
#define DIRSIZ 14
struct dirent {
ushort inum;
char name[DIRSIZ];
};
接下来,详细学习各层的实现原理,
二、文件系统中各层原理以及代码实现
1、Buffer Cache层
buffer cach原理
buffer cache有两个功能:1)同步访问磁盘块,确保只有一个块的copy在内存中,同时一次也就一个内核线程使用该copy。
2)cache常用块,这样他们就不需要从比较慢的磁盘中重新读取,代码在bio.c中
buffer cache的主要接口有bread和bwrite组成。
bread获得包含块copye的buffer。该buffer可以读,也可以在内存中修改。
bwrite写修改后的buffer 到内存中的适合的块中。
当任务完成后,内核线程必须通过调用brelse来释放buffer。
当buffer cache同步访问各个块,顶多允许一个内核线程引用块的buffer。如果一个内核线程已经获得引用buffer的权限,但是还没有释放,那么其他的线程调用bread来读取相同的块时需要等待。较高层的文件系统依赖buffer cache的块同步来帮助他们维持不变。
buffer cache有固定的buffer号来保存磁盘块,意味着如果一个文件系统请求的块已经不在cache中,那么buffer cache必须重新循环当前的buffer来保存一些其他的块。buffer cache重循环最近最少使用的buffer用于保存新的块。该假设是最近最少使用的buffer,再次使用的可能性最小。
buffer cache代码实现
buffer cache是一个buffer的双链表。内核中main函数通过调用binit函数来对NBUF(=10)个buffer的静态数组buf进行初始化链表。所有其他访问buffer cache通过bcache.head来应用链表,而不是buf数组。
buffer有三个状态bits与其关联,如下:
1)B_VALID:表示buffer包含有效的块copy。
2)B_DIRTY:表示buffer内容已经被修改,需要被写入磁盘。
3)B_BUSY:表示一些内核线程引用该buffer,还没有释放。
binit函数的实现代码如下:
void
binit(void)
{
struct buf *b;
initlock(&bcache.lock, "bcache");
//PAGEBREAK!
// Create linked list of buffers
bcache.head.prev = &bcache.head;
bcache.head.next = &bcache.head;
for(b = bcache.buf; b < bcache.buf+NBUF; b++){
b->next = bcache.head.next;
b->prev = &bcache.head;
b->dev = -1;
bcache.head.next->prev = b;
bcache.head.next = b;
}
}
其中buf结构体和bcache的定义如下:
struct {
struct spinlock lock;
struct buf buf[NBUF];
// Linked list of all buffers, through prev/next.
// head.next is most recently used.
struct buf head;
} bcache;
// the definition of struct buf
struct buf {
int flags;
uint dev;
uint sector;
struct buf *prev; // LRU cache list
struct buf *next;
struct buf *qnext; // disk queue
uchar data[512];
};
#define B_BUSY 0x1 // buffer is locked by some process
#define B_VALID 0x2 // buffer has been read from disk
#define B_DIRTY 0x4 // buffer needs to be written to disk
bread函数调用bget函数获得给定sectors的buffer。如果该buffer需要从磁盘上读取,则在返回buffer之前,bread函数调用iderw函数来读取。
struct buf*
bread(uint dev, uint sector)
{
struct buf *b;
b = bget(dev, sector);
if(!(b->flags & B_VALID))
iderw(b);
return b;
}
bget函数根据给定的设备和扇区号来扫描buffer链表,如果有一个buffer空闲,bget设置其B_BUSY标志位然后返回,如果buffer已经处于使用中,bget函数sleep等待其释放。当sleep返回后,bget函数不能假定该buffer已经可用,实际上,从sleep释放,然后重新获取buf_table_lock,不能确保b仍然是正确的buffer:可能已经被重新用为不同的磁盘扇区。bget函数没有选择,必须重新开始。以希望这次的结果不同。
bget函数的代码实现如下:
// Look through buffer cache for sector on device dev.
// If not found, allocate fresh block.
// In either case, return B_BUSY buffer.
static struct buf*
bget(uint dev, uint sector)
{
struct buf *b;
acquire(&bcache.lock);
loop:
// Is the sector already cached?
for(b = bcache.head.next; b != &bcache.head; b = b->next){
if(b->dev == dev && b->sector == sector){
if(!(b->flags & B_BUSY)){
b->flags |= B_BUSY;
release(&bcache.lock);
return b;
}
sleep(b, &bcache.lock);
goto loop;
}
}
// Not cached; recycle some non-busy and clean buffer.
for(b = bcache.head.prev; b != &bcache.head; b = b->prev){
if((b->flags & B_BUSY) == 0 && (b->flags & B_DIRTY) == 0){
b->dev = dev;
b->sector = sector;
b->flags = B_BUSY;
release(&bcache.lock);
return b;
}
}
panic("bget: no buffers");
}
如果bget函数没有goto操作,那么就会发生图3所示的竞争。
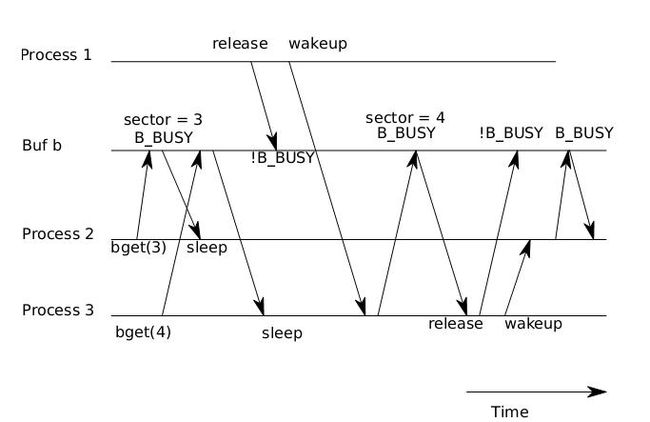
图3 竞争导致进程3收到包含块4的buffer,尽管其请求的是块3
第一个进程有一buffer,然后加载扇区3到其中,现在有其他两个进程到来,这两个进程中,一个要获得buffer 3,在循环中sleeps等待cached blocks,另一个要获得buffer 4,同时sleep