hadoop2.x集群的安装
一、说明
1. 本文档以四台机器为例搭建hadoop集群,各台机器的职责如下:
此集群主要包括Namenode HA和RresourceManager HA,这是本文重点所在。
|
|
hadoop1 |
hadoop2 |
hadoop3 |
hadoop4 |
| NameNode |
Y |
Y |
N |
N |
| DataNode |
N |
N |
Y |
Y |
| JournalNode |
Y |
Y |
Y |
N |
| Zookeeper |
Y |
Y |
Y |
N |
| zkfc |
Y |
Y |
N |
N |
| ResourceManager |
Y |
Y |
N |
N |
| NodeManager |
N |
N |
Y |
Y |
| HistoryServer |
N |
Y |
N |
N |
2. 系统准备
Linux版本Cent OS 6.5
由于系统默认单个进程打开的句柄数过低,所以首先要修改以下参数
/etc/security/limits.conf
hadoop soft nofile 131072
hadoop hard nofile 131072
/etc/security/limits.d/90-nproc.conf
hadoop soft nproc unlimited
root soft nproc unlimited
hadoop hard nproc unlimited
注:
soft nproc: 可打开的文件描述符的最大数(软限制)
hard nproc: 可打开的文件描述符的最大数(硬限制)
soft nofile:单个用户可用的最大进程数量(软限制)
hard nofile:单个用户可用的最大进程数量(硬限制)
3. hadoop及zookeeper版本
hadoop版本:hadoop-2.3.0-cdh5.0.0.tar.gz
zookeeper版本:zookeeper-3.4.5-cdh5.0.0.tar.gz
4. 要提前配好ssh的无密码连接(用hadoop用户),在/etc/hosts中做好整个集群的hostname和ip的映射,以及安装JDK7,本文档不再详述。
cat /etc/hosts
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
132.35.227.72 DSSBACKUP06 hadoop1
132.35.227.74 JCYW-BACKUP02 hadoop2
132.35.224.248 dssbackup2 hadoop3
132.35.224.249 dssbackup1 hadoop4
二、部署步骤
1. Zookeeper的配置
1.1 新建目录 /opt/beh-2.0.0, 以后整个hadoop生态的其他组件都将安装到此目录下。
mkdir -p /opt/ beh-2.0.0
新建名字为hadoop的用户
useradd hadoop
将/opt/beh-2.0.0赋予hadoop用户
chown -R hadoop:hadoop /opt/beh-2.0.0
1.2 将zookeeper-3.4.5-cdh5.0.0.tar.gz解压缩到/opt/beh-2.0.0下,并重命名为zookeeper。
1.3 修改zookeeper配置文件
/opt/beh-2.0.0/zookeeper/conf/zoo_sample.cfg 重名为zoo.cfg
进入到conf目录下,执行:
mv zoo_sample.cfg zoo.cfg
修改zoo.cfg
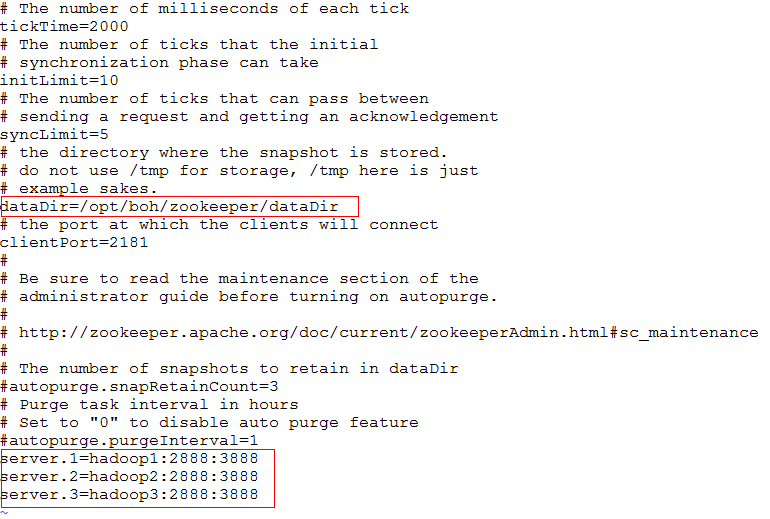
1.4 将整个zookeeper目录分别复制hadoop1,hadoop2,hadoop3上。分别在hadoop1,hadoop2,hadoop3创建dataDir属性指定的目录,并在此目录下创建myid文件。
cd /opt/beh-2.0.0/zookeeper/dataDir
vi myid
hadoop1上的myid里面写入值1
hadoop2上的myid里面写入值2
hadoop3上的myid里面写入值3
1.5 修改环境变量
vi /etc/profile
添加
$ZOOKEEPER_HOME=/opt/beh-2.0.0/zookeeper
PATH=$ZOOKEEPER_HOME/bin:$PATH
source /etc/profile
1.6 在hadoop1,hadoop2,hadoop3上执行
chown -R hadoop /opt/beh-2.0.0/zookeeper
1.7 验证是否成功
分别在hadoop1,hadoop2,hadoop3上执行zkServer.sh start
用jps命令查看进程QuorumPeerMain是否启动
2. Namenode HA的配置
2.1 将hadoop-2.3.0-cdh5.0.0.tar.gz解压到/opt/beh-2.0.0/下,并重命名为hadoop,
tar -zxvf hadoop-2.3.0-cdh5.0.0.tar.gz ./
mv hadoop-2.3.0-cdh5.0.0 hadoop
修改etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://beh</value>
</property>
【beh是个逻辑名称,可以随意制定,它来自于hdfs-site.xml中的配置】
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/beh-2.0.0/hadoop/tmp</value>
</property>
【这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录。用户也可以自己单独指定这三类节点的目录。】
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
【这里是ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点】
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
缓冲区大小:io.file.buffer.size默认是4KB,作为hadoop缓冲区,用于hadoop读hdfs的文件和写hdfs的文件,还有map的输出都用到了这个缓冲区容量,对于现在的硬件很保守,可以设置为128k(131072),甚至是1M(太大了map和reduce任务可能会内存溢出)。
2.2 修改hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>beh</value>
</property>
【这是此hdfs集群的逻辑名称】
<property>
<name>dfs.ha.namenodes.beh</name>
<value>nn1,nn2</value>
</property>
【这是两个namenode的逻辑名称,随意起名,相互不重复即可】
<property>
<name>dfs.namenode.rpc-address.beh.nn1</name>
<value>hadoop1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.beh.nn1</name>
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.beh.nn2</name>
<value>hadoop2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.beh.nn2</name>
<value>hadoop2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/beh</value>
</property>
dfs.namenode.shared.edits.dir共享存储目录的位置
这是配置备份节点需要随时保持同步活动节点所作更改的远程共享目录,你只能配置一个目录,这个目录挂载到两个namenode上都必须是可读写的,且必须是绝对路径。
<property>
<name>dfs.ha.automatic-failover.enabled.beh</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.beh</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/beh-2.0.0/hadoop/journal</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hadoop_data/datafile/data</value>
</property>
<property>
<name>dfs.block.size</name>
<value> 134217728</value>
</property>
【block大小可根据实际情况进行设置,此处为128M】
<property>
<name>dfs.datanode.handler.count</name>
<value>3</value>
</property>
dfs.datanode.handler.count
datanode上用于处理RPC的线程数。默认为3,较大集群,可适当调大些,比如8。需要注意的是,每添加一个线程,需要的内存增加。
<property>
<name>dfs.namenode.handler.count</name>
<value>20</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>131072</value>
</property>
<property>
<name>dfs.datanode.socket.write.timeout</name>
<value>0</value>
</property>
<property>
<name>dfs.socket.timeout</name>
<value>180000</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2.3 编辑 /etc/hadoop/slaves
添加 hadoop3
hadoop4
2.4 编辑/etc/profile
添加 HADOOP_HOME=/opt/beh-2.0.0/hadoop
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
将以上配置复制到所有节点
参考语句:
scp -r /opt/beh-2.0.0/hadoop/ hadoop@132.35.227.74:/opt/beh-2.0.0/
scp -r /opt/beh-2.0.0/hadoop/ hadoop@132.35.224.248:/opt/beh-2.0.0/
scp -r /opt/beh-2.0.0/hadoop/ hadoop@132.35.224.249:/opt/beh-2.0.0/
2.5 启动各项服务
2.5.1 启动journalnode
在hadoop1、hadoop2、hadoop3上执行hadoop-daemon.sh start journalnode
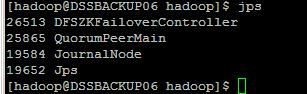
2.5.2 格式化zookeeper
在hadoop1上执行hdfs zkfc -formatZK
2.5.3 对hadoop1节点进行格式化和启动
hdfs namenode -format
hadoop-daemon.sh start namenode
2.5.4 对hadoop2节点进行格式化和启动
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
2.5.5 在hadoop1和hadoop2上启动zkfc服务
hadoop-daemon.sh start zkfc
此时hadoop1和hadoop2就会有一个节点变为active状态。
2.5.6 启动datanode
在hadoop1上执行命令hadoop-daemons.sh start datanode
2.5.7 验证是否成功
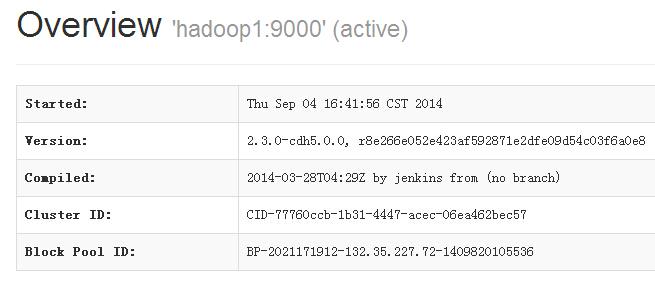
打开浏览器,访问 hadoop1:50070 以及 hadoop2:50070,你将会看到两个namenode一个是active而另一个是standby。
(参考网址http://132.35.227.72:50070)
然后kill掉其中active的namenode进程,另一个standby的naemnode将会自动转换为active状态。
kill -9 19856

测试过,上面的步骤完全正确。
3. ResourceManager HA的配置
3.1 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- configure historyserver -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop2:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop2:19888</value>
</property>
<!-- configure staging directory -->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<!--optimize-->
<property>
<name>mapred.child.java.opts</name>
<value>-Xmx2g</value>
</property>
<property>
<name>io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>io.sort.factor</name>
<value>20</value>
</property>
<property>
<name>mapred.job.reuse.jvm.num.tasks</name>
<value>-1</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>20</value>
</property>
</configuration>
3.2 修改yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/beh-2.0.0/hadoop/nmdir</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/beh-2.0.0/hadoop/logs</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>hdfs://beh/var/log/hadoop-yarn/apps</value>
</property>
<!-- Resource Manager Configs -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>beh</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!-- RM1 configs -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>hadoop1:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>hadoop1:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>hadoop1:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop1:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>hadoop1:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>hadoop1:23141</value>
</property>
<!-- RM2 configs -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop2:23140</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop2:23130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>hadoop2:23189</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop2:23188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop2:23125</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>hadoop2:23141</value>
</property>
<!-- Node Manager Configs -->
<property>
<description>Address where the localizer IPC is.</description>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:23344</value>
</property>
<property>
<description>NM Webapp address.</description>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:23999</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/beh-2.0.0/hadoop/nodemanager/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/beh-2.0.0/hadoop/nodemanager/yarn/log</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
</configuration>
3.3 将配置文件分发至各节点。
参考语句:
scp -r /opt/beh-2.0.0/hadoop/etc/hadoop/mapred-site.xml hadoop@132.35.227.74:/opt/beh-2.0.0/hadoop/etc/hadoop/
scp -r /opt/beh-2.0.0/hadoop/etc/hadoop/mapred-site.xml hadoop@132.35.224.248:/opt/beh-2.0.0/hadoop/etc/hadoop/
scp -r /opt/beh-2.0.0/hadoop/etc/hadoop/mapred-site.xml hadoop@132.35.224.249:/opt/beh-2.0.0/hadoop/etc/hadoop/
scp -r /opt/beh-2.0.0/hadoop/etc/hadoop/yarn-site.xml hadoop@132.35.227.74:/opt/beh-2.0.0/hadoop/etc/hadoop/
scp -r /opt/beh-2.0.0/hadoop/etc/hadoop/yarn-site.xml hadoop@132.35.224.248:/opt/beh-2.0.0/hadoop/etc/hadoop/
scp -r /opt/beh-2.0.0/hadoop/etc/hadoop/yarn-site.xml hadoop@132.35.224.249:/opt/beh-2.0.0/hadoop/etc/hadoop/
3.4 修改hadoop2上的yarn-site.xml
修改为下面的值:
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm2</value>
</property>
3.5 创建目录并赋予权限
3.5.1在所有的nodemanager上创建本地目录(hadoop3,hadoop4)
mkdir -p /opt/beh-2.0.0/hadoop/nmdir
mkdir -p /opt/beh-2.0.0/hadoop/logs
chown -R hadoop:hadoop /opt/beh-2.0.0/hadoop/nmdir
chown -R hadoop:hadoop /opt/beh-2.0.0/hadoop/logs
3.5.2 启动hdfs后,执行下列命令
hadoop fs -mkdir -p /user/history
hadoop fs -chmod -R 777 /user/history
hadoop fs -chown hadoop:hadoop /user/history
创建log目录
hadoop fs -mkdir -p /var/log/hadoop-yarn
hadoop fs -chown hadoop:hadoop /var/log/hadoop-yarn
创建hdfs下的/tmp
如果不创建/tmp按照指定的权限,那么CDH的其他组件将会有问题。尤其是,如果不创建的话,其他进程会以严格的权限自动创建这个目录,这样就会影响到其他程序适用。
hadoop fs -mkdir /tmp
hadoop fs -chmod -R 777 /tmp
3.6 启动yarn 和 jobhistory server
3.6.1 在hadoop1上启动:
sbin/start-yarn.sh
此脚本将会启动hadoop1上的resourcemanager及所有的nodemanager。
3.6.2 在hadoop2上启动resourcemanager:
yarn-daemon.sh start resourcemanager
3.6.3 在hadoop2上启动jobhistory server
sbin/mr-jobhistory-daemon.sh start historyserver
3.7 验证是否配置成功。
打开浏览器,访问hadoop1:23188或者hadoop2:23188,应该能看到类似如下界面。只有active的会打开如下界面,standby的那个不会看到页面。
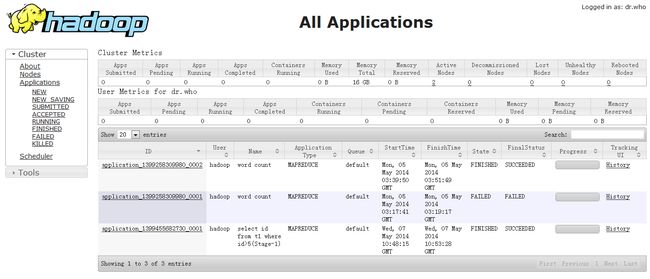
然后kill掉active的resourcemanager另一个将会变为active的,说明resourcemanager HA是成功的。
4. 关于重新格式化namenode
如果要重新格式化namenode,那么首先要停掉所有相关的服务
1)删掉$HADOOP_HOME/tmp 下的之前的格式化的信息
2)删掉datanode上$HADOOP_HOME/current文件夹,如果有的话。
3)在hdfs-site.xml找着dfs.data.dir属性,此属性的value中配置的目录都要清空,这是datanode存放数据的地方。
4)执行格式化