mysql sql查询过程分析之explain关键字
Mysql EXPLAIN只能解释SELECT语句,并不会对存储程序和INSERT,UPDATE,DELETE或其他语句做解释. 但5.5版本之后支持了Update等语句.
explain分析结果每个表在输出中只有一行,如果是2个表的联接,那么输出有2行.
我们先创建一个表,本文所有的实验都将基于该表来做分析.
创建表 learn_explain,DDL如下:
-- ----------------------------
-- Table structure for learn_explain
-- ----------------------------
DROP TABLE IF EXISTS `learn_explain`;
CREATE TABLE `learn_explain` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`act_id` int(11) DEFAULT NULL,
`publish_date` datetime DEFAULT NULL,
`value` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `act_id-publish_date` (`act_id`,`publish_date`) USING BTREE,
KEY `second_index` (`value`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=latin1;
-- ----------------------------
-- Records of learn_explain
-- ----------------------------
INSERT INTO `learn_explain` VALUES ('1', '1', '2015-08-09 17:03:36', '100');
INSERT INTO `learn_explain` VALUES ('2', '2', '2015-08-09 17:03:52', '101');
INSERT INTO `learn_explain` VALUES ('3', '3', '2015-08-09 17:04:02', '103');
INSERT INTO `learn_explain` VALUES ('4', '4', '2015-08-09 17:04:13', '104');
INSERT INTO `learn_explain` VALUES ('5', '5', '2015-08-09 17:04:23', '105');
INSERT INTO `learn_explain` VALUES ('6', '6', '2015-08-09 17:04:35', '106');
数据库的存储引擎采用InnoDB,learn_explain表创建了如下索引:
主键索引: id
唯一索引: <act_id,publish_date>
普通二级索引: value
先看看explain分析的结果:
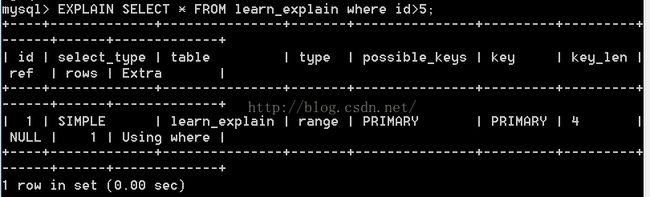
1, id 列: 编号, 标识SELECT所属的行。
2, select_type: 分为简单(SIMPLE)和复杂类型.
复杂类型又分为:
2.1 简单子查询(SUBQUERY).
2.2 所谓的派生表(DERIVED)(在FROM子句中的子查询).
2.3 UNION查询(UNION).
2.4 UNION RESULT 用来从UNION的匿名临时表检索结果的SELECT标识为UNION RESULT.
3, type列. 访问类型,换言之就是MYSQL决定如何查找表中的行.
3.1 ALL 所谓的全表扫描. 按行查找(不是按索引查找).
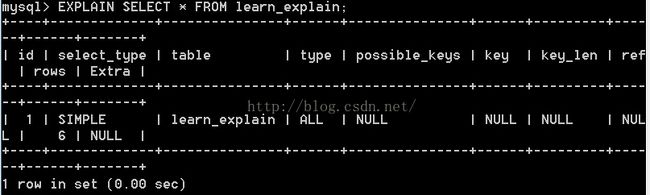
上面的操作就是type=ALL,全表扫描.
3.2 INDEX 全表扫描,只是MYSQL扫描表时按索引次序而不是行.优点是避免了排序,缺点是要承担按索引顺序读取整个表的开销.
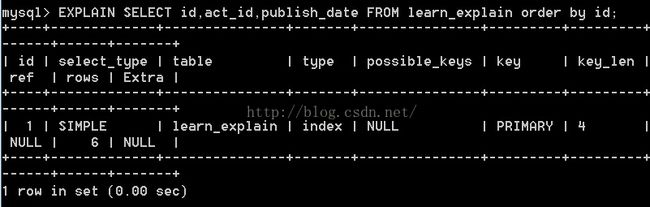
扫描时根据索引id的顺序扫描表,避免排序.
如果extra中出现了"Using Index",说明Mysql使用了覆盖索引,它只扫描索引而不用回表,比按行扫描开销小很多,如下面的例子:
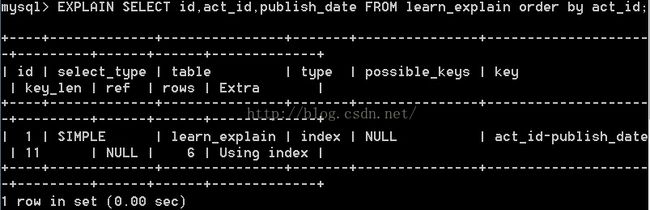
什么是覆盖索引? 就是说select的字段被索引完全覆盖,索引不需要回表去查其它的字段.如上面的例子: id,act_id,publish_date这三个字段均被索引 "act_id-publish_date"覆盖,存储引擎不需要去查找聚簇索引来补充额外的其它查询字段.覆盖索引扫描是非常快的.
3.3 range
range 范围扫描是一个有限制的索引扫描,开始于索引的某一行.比全索引扫描好一些. 一般带有Between或者where 中有>的查询.另外 in() 和 or列表也显示范围扫描.
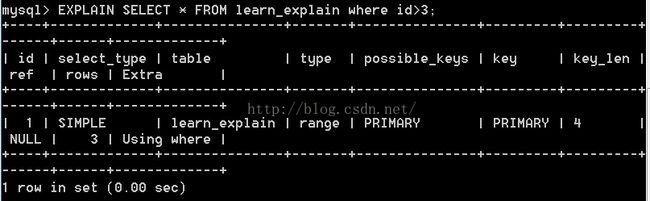
但是把上面的select * from xx where id>3 换成 "where act_id>3""就变成全表扫描了.
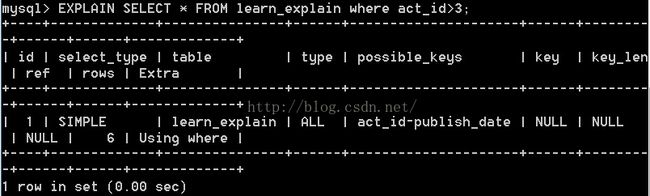
再看看in的例子,也显示范围扫描.
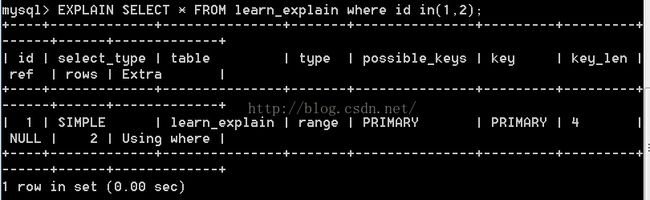
3.4 ref
这是一种索引访问,它返回的是所有匹配某个单个值的行. 结果可能有多条数据,是"扫描和查找的混合体" 一般出现在非唯一索引或者唯一索引的某个前缀索引时才会发生.
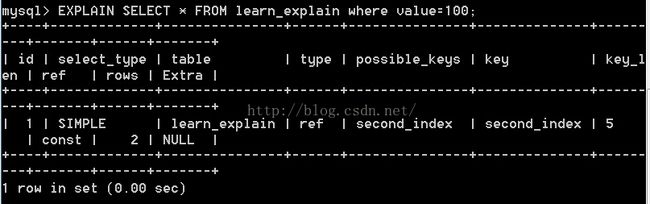
上面是非唯一索引(learn_explain表中的second_index索引)的例子,如果是唯一索引的前缀索引呢?看下面的例子:
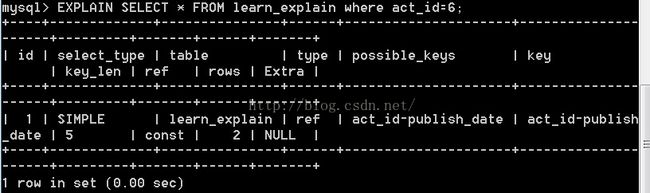
但如果我们用唯一索引来查找呢?如下所示:
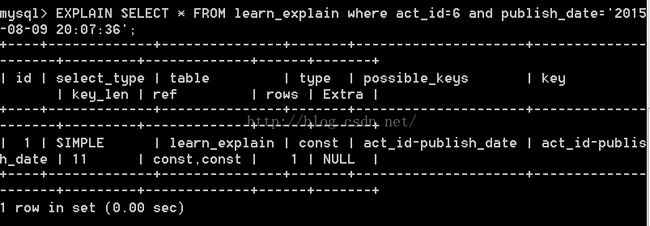
type变成了 const .这是我们下面要说的type类型
3.5, const,system
查询分析器知道返回的只有一条数据.唯一索引和主键索引时会出现该类型.
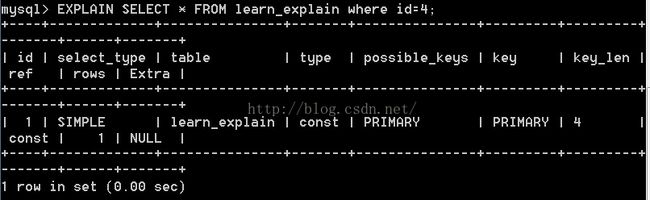
3.6, NULL
在执行阶段不用再去访问表或者索引.
4, Possible_keys
这一列显示查询可以使用哪些索引,但罗列出来的索引可能对后续优化过程没有用.
5, key
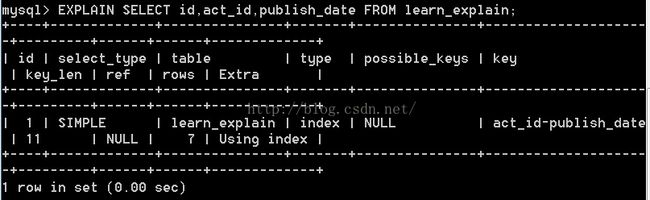
6, key_len 列
该列显示了Mysql在索引里使用的字节数.
7, ref列
这一列显示之前在表的key列记录的索引中查找值所用的列或常量
8, rows列
这一列是mysql估计为了找到所需要的行而需要读取的行数.
9, extra列
9.1 using index
9.2 using where
这意味着mysql服务器将在存储引擎检索后再进行过滤.
9.3 using temporary
9.4 using filesort
这意味着mysql会对结果使用一个外部索引排序,而不是按索引次序从表里读取行.