LEX & FLEX 实现C语言词法分析器
最近在学习《编译原理》,学完词法分析之后,做了一个C语言的词法分析器。
词法分析简述:
词法分析是编译过程的第一步,主要实现高级语言程序中词法规范的检查。词法分析程序的主要任务是按语言的词法规则从源程序中逐个识别单词,把字符串形式的源程序转行成单词串的形式,并把每个单词转换成他们的内部表示,即所谓的“TOKEN”,并对词法进行检查。
词法分析模型:

图一:词法分析模型图
对于一个完整的词法分析模块,主要包含三个部分:输入,处理,输出。
输入:高级语言源程序。
输出:TOKEN List,TOKEN为单词的一种内部表示,一般由两部分组成:单词类别和语义信息。但此类别用来区分不同的单词种类,通常可以使用整数进行编码,语义信息也取决于今后处理的方便(一般为单词内容)。

图二:TOLEN结构
词法分析器:对于某一具体语言(本文采用C语言为例)的所有类词汇,使用正则表达式描述其组成,然后将每条正则表达式转换成有限自动机进而确定化和化简,再把所有的状态机合并成一个总的状态机,然后根据该状态机构造词法分析程序。 图二:TOKEN结构图
为了实现方便,采用词法分析器自动生成器FLEX。
FLEX工作原理介绍:
FLEX的功能是根据FLEX源文件构造一个词法分析器,由FLEX生成的词法分析器由两部分组成,一个状态转换矩阵和一个控制执行程序。
它的工作过程是:
1,扫描每一条正则式规则Ri,为之构造一个非确定的有限自动机NFA Mi;
2,将各条正则式对应的NFA Mi合并成一个新的NFA M.
3,将NFA M等价变换成DFA D,并生成该DFA的状态转换矩阵和控制执行程序。

图三:FLEX工作模型图
FLEX源文件:
格式:.l
内容:定义部分和辅助函数部分可选,识别规则部分必须。
定义部分
%%
识别规则部分
%%
辅助函数部分
定义部分:对规则部分要引用的文件和变量进行说明,通常包含头文件,常量定义,全局变量定义以及宏定义等。
识别规则部分:有一组识别规则组成,书写格式如下:
R1 A1
R2 A2
```
Rn An
其中Ri是单词的正则表示,Ai表示当时别出该串时所要执行的动作。
辅助函数部分:这部分包含了识别规则动作代码段中所调用的各局部函数,这些函数由用户编写,由FLEX直接复制输出到lex.yy.c中。
由FLEX生成的词法分析器,作为语法分析的子程序,每调用一次返回一个TOKEN.
以下是C语言的单词正则表达式描述:
表一:语言单词正则表示
| (auto) |
(break) |
(case) |
(char) |
(const) |
| (continue) |
(default) |
(do) |
(double) |
(else) |
| (enum) |
(extern) |
(float) |
(for) |
(goto) |
| (if) |
(inline) |
(int) |
(long) |
(register) |
| (return) |
(short) |
(signed) |
(sizeof) |
(static) |
| (struct) |
(switch) |
(typedef) |
(union) |
(unsigned) |
| ([a-z]|[A-Z]|_)([a-z]|[A-Z]|[0-9]|_)* |
(void) |
(while) |
(volatile) |
|
| (\() |
(\)) |
(\]) |
(\-\>) |
(\.) |
| (\[) |
(!) |
(\-) |
(\-\-) |
(\+\+) |
| (~) |
(\+) |
(%) |
(\/) |
(&) |
| (\*) |
(\<=) |
(\<) |
(\>\>) |
(\>) |
| (\<\<) |
(\|) |
(\^) |
(!=) |
(==) |
| (\>=) |
(&&) |
(\|\|) |
(\?:) |
(=) |
| (\+=) |
(\-=) |
(\*=) |
(\/=) |
(%=) |
| (\>\>=) |
(\<\<=) |
(&=) |
(\|=) |
(,) |
| (\^=) |
(\\a) |
(\\b) |
(\\f) |
(\\n) |
| (\\r) |
(\\t) |
(\\v) |
(;) |
(:) |
| (\+|\-)?([1-9][0-9]*|0)(\.[0-9]+) |
(\+|\-)?([1-9][0-9]*|0) |
|||
| (")([\s\S]*)(") |
(')([a-z]|[A-Z])(') |
(\/\/) |
(\/\*)([\s\S]*)(\*\/) |
|
|
|
|
|
|
|
下载,安装Flex(因为Lex是Unix系统下的),软件资源链接http://download.csdn.net/detail/u014594922/9499863
下载之后安装,安装完之后配置环境变量,右键点击“计算机”,“属性”、“高级系统设置”、“环境变量”,在下面系统变量里面找到PATH,修改,在后面加上:;E:\FlexInstall\GnuWin32\bin flex的安装路径,注意最前面的";"
配置完之后:
使用上图的C语言单词正则描述构建Flex源文件C.l
%%
(auto)
(break)
(case)
(char)
(const)
(continue)
(default)
(do)
(double)
(else)
(enum)
(extern)
(float)
(for)
(goto)
(if)
(inline)
(int)
(long)
(register)
(return)
(short)
(signed)
(sizeof)
(static)
(struct)
(switch)
(typedef)
(union)
(unsigned)
(void)
(volatile)
(while)
([a-z]|[A-Z]|_)([a-z]|[A-Z]|[0-9]|_)*
(\()
(\))
(\[)
(\])
(\-\>)
(\.)
(!)
(~)
(\+\+)
(\-\-)
(\-)
(\*)
(&)
(\/)
(%)
(\+)
(\<\<)
(\>\>)
(\<)
(\<=)
(\>)
(\>=)
(==)
(!=)
(\^)
(\|)
(&&)
(\|\|)
(\?:)
(=)
(\+=)
(\-=)
(\*=)
(\/=)
(%=)
(\>\>=)
(\<\<=)
(&=)
(\^=)
(\|=)
(,)
(\\a)
(\\b)
(\\f)
(\\n)
(\\r)
(\\t)
(\\v)
(;)
(:)
(\+|\-)?([1-9][0-9]*|0)
(\+|\-)?([1-9][0-9]*|0)(\.[0-9]+)
(')([a-z]|[A-Z])(')
(")([\s\S]*)(")
(\/\/)
(\/\*)([\s\S]*)(\*\/)
文件目录在:E:\课件\编译原理\词法分析\C语言词法分析
接下来使用Flex生成词法分析状态转换矩阵和处理程序
进入Dos执行相应命令:
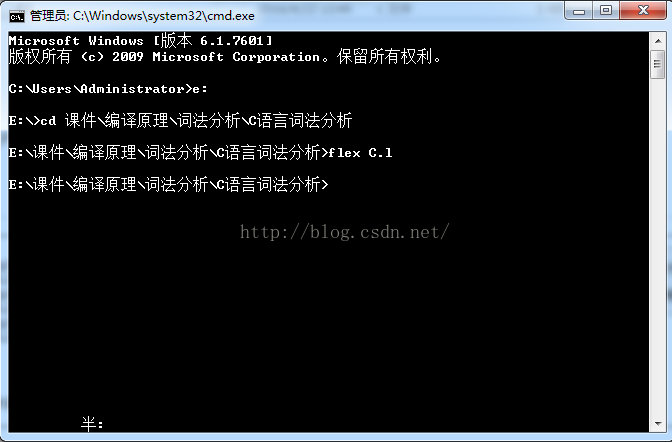
源目录下生成了词法分析器程序:lex.yy.c

这里是单独使用Flex,实际上是和Bison词法分析器自动生成器一起连用的。