Cluster中3个Nodes挂掉2个,恢复Recovery Pending的DB的方案探索(续)
在Cluster中3个Nodes挂掉2个,恢复Recovery Pending的DB的方案探索中,做过各种尝试,均不能直接在原有Server上恢复DB。后面把问题反馈给了MS,经过几次的尝试,目前已实现直接在原有Server上恢复的目的。下面将整个后续的过程写出来。
MS回复:
問題代號 : 113110810930310
問題說明 : AlwaysOn主要伺服器出問題,次要伺服器資料庫無法還原
原因說明 : 主要伺服器已關閉。
解決方式 :
[請您參考以下的說明]
請您先確認次要伺服器上的AlwaysOn的資料庫狀態。
建議您使用ALTER AVAILABILITY GROUP group_nameFORCE_FAILOVER_ALLOW_DATA_LOSS來強制移轉AlwaysOn的容錯移轉。
請您執行以下步驟來還原AlwaysOn資料庫:
1) 若要強制容錯移轉 (可能會遺失資料)
必要條件
• WSFC叢集具有仲裁。如果叢集缺少仲裁,請參閱<透過強制仲裁執行WSFC 災害復原 (SQL Server)>。
• 您必須能夠連接到裝載其角色為 SECONDARY 或 RESOLVING 狀態之複本的伺服器執行個體。
執行步驟:
1. 連接到裝載需要容錯移轉之可用性群組中,其角色為 SECONDARY或 RESOLVING 狀態之複本的伺服器執行個體。
2. 使用 ALTERAVAILABILITY GROUP 陳述式,如下所示:
ALTER AVAILABILITY GROUP group_nameFORCE_FAILOVER_ALLOW_DATA_LOSS
其中 group_name 是可用性群組的名稱。
下列範例會將 AccountsAG可用性群組強制容錯移轉到本機次要複本。
ALTER AVAILABILITY GROUP AccountsAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
3. 強制可用性群組容錯移轉之後,完成必要的後續追蹤步驟。
2) 若要繼續次要資料庫
限制事項
一旦裝載目標資料庫的複本接受 RESUME命令之後,就會將其傳回,但繼續資料庫實際上是以非同步方式進行。
必要條件
• 您必須連接到裝載要繼續之資料庫的伺服器執行個體。
• 可用性群組必須在線上。
• 主要資料庫必須在線上而且可用。
執行步驟:
若要繼續在本機上暫停的次要資料庫
1. 連接至裝載您要繼續其資料庫之次要複本的伺服器執行個體。
2. 使用下列 ALTER DATABASE陳述式,繼續次要資料庫:
ALTER DATABASE database_name SET HADR RESUME
附註
若要繼續此複本位置的其他資料庫,請針對每個資料庫重複以上步驟。
參考知識文件:
How It Works: Always On–When Is My Secondary Failover Ready?
http://blogs.msdn.com/b/psssql/archive/2013/04/22/how-it-works-always-on-when-is-my-secondary-failover-ready.aspx
執行可用性群組的強制手動容錯移轉 (SQL Server)
http://technet.microsoft.com/zh-tw/library/ff877957.aspx
ALTER AVAILABILITYGROUP (Transact-SQL)
http://technet.microsoft.com/zh-tw/library/ff878601.aspx
繼續可用性資料庫 (SQL Server)
http://technet.microsoft.com/zh-tw/library/ff877956.aspx
ALTER DATABASE SETHADR (Transact-SQL)
http://technet.microsoft.com/zh-tw/library/ff877974.aspx
尝试:
根据<透過強制仲裁執行WSFC 災害復原 (SQL Server)里面的介绍,无法通过Failover Cluster Manager在无仲裁情况下强制启动群集:
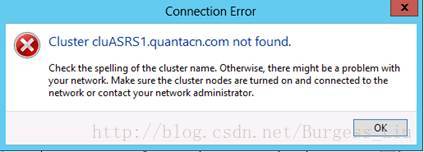
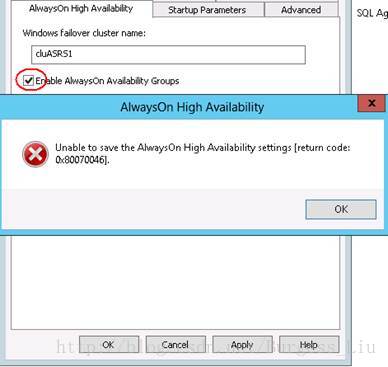
因之前尝试DisableAlwaysOn Availability Groups,当时有报和今天Enable它同样的错误信息,无法Enable起来:
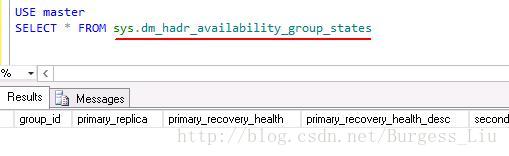
查询无结果:
执行下面的命令,收到同样的错误讯息,虽提示要Enable AlwaysOn Availability Groups,但如上面所讲,无法Enable:
ALTER AVAILABILITYGROUP agASRS FORCE_FAILOVER_ALLOW_DATA_LOSS
Msg 35221, Level 16, State 1, Line1
Could not process the operation.AlwaysOn Availability Groups replica manager is disabled on this instance ofSQL Server. Enable AlwaysOn Availability Groups, by using the SQL ServerConfiguration Manager. Then, restart the SQL Server service, and retry thecurrently operation. For information about how to enable and disable AlwaysOnAvailability Groups, see SQL Server Books Online.
ALTER DATABASEASRS_F1 SET HADR RESUME
Msg 35221, Level 16, State 1, Line1
Could not process the operation.AlwaysOn Availability Groups replica manager is disabled on this instance ofSQL Server. Enable AlwaysOn Availability Groups, by using the SQL ServerConfiguration Manager. Then, restart the SQL Server service, and retry thecurrently operation. For information about how to enable and disable AlwaysOnAvailability Groups, see SQL Server Books Online.
MS回复:
參考以下方法來強制重啟叢集服務:
- 手動停止叢集服務 "net.exe stop Cluster_Name" (Cluster_Name 您可以從[系統管理工具]\[服務]的ClusterService取得您的clustername)
- 執行 ”net.exestart Cluster_Name/forcequorum”
- 執行完畢後,就可以連至本機的叢集服務。
- 檢查AG狀態,如果未啟動,請將AG的將 網路名稱及 IP “上線”。
若上述步驟無法解決您的問題,請問是否可遠端連線到您的電腦進行troubleshooting?
參考資料:
在無仲裁情況下強制啟動 WSFC 叢集
http://technet.microsoft.com/zh-tw/library/hh270275.aspx
尝试:
强制重启群集服务成功:
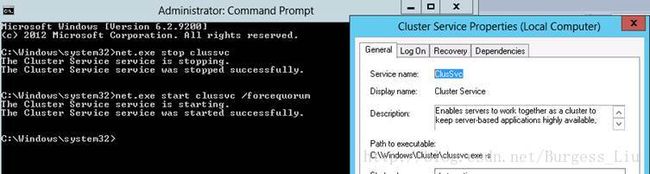
连接本地群集成功,但Role agASRS无法Start:
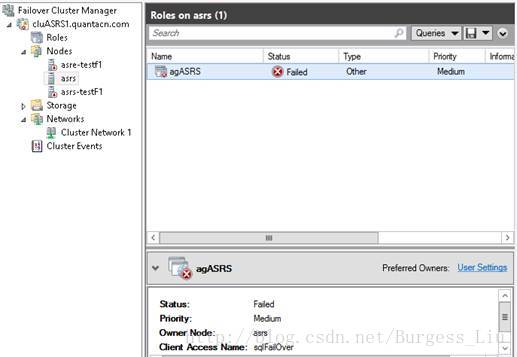
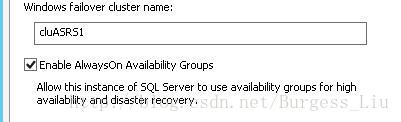
Enable AlwaysOn AvailabilityGroups成功:
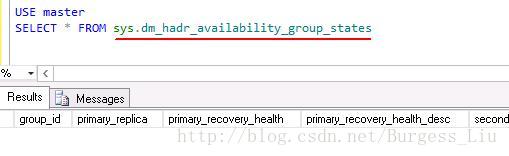
查询无结果:
执行下面的命令,依旧收到同样的错误讯息:
ALTER AVAILABILITYGROUP agASRS FORCE_FAILOVER_ALLOW_DATA_LOSS
Msg 35221, Level 16, State 1, Line1
Could not process the operation.AlwaysOn Availability Groups replica manager is disabled on this instance ofSQL Server. Enable AlwaysOn Availability Groups, by using the SQL Server ConfigurationManager. Then, restart the SQL Server service, and retry the currentlyoperation. For information about how to enable and disable AlwaysOnAvailability Groups, see SQL Server Books Online.
ALTER DATABASEASRS_F1 SET HADR RESUME
Msg 35221, Level 16, State 1, Line1
Could not process the operation.AlwaysOn Availability Groups replica manager is disabled on this instance ofSQL Server. Enable AlwaysOn Availability Groups, by using the SQL ServerConfiguration Manager. Then, restart the SQL Server service, and retry thecurrently operation. For information about how to enable and disable AlwaysOnAvailability Groups, see SQL Server Books Online.
今天,通过Live Meeting远程连接到我的桌面,尝试了下面的命令,均告失败:
ALTER DATABASEASRS_F1 SET OFFLINE WITH ROLLBACKIMMEDIATE
ALTER AVAILABILITYGROUP agASRS REMOVE DATABASE ASRS_F1;
ALTER AVAILABILITYGROUP agASRS FORCE_FAILOVER_ALLOW_DATA_LOSS
ALTER DATABASEASRS_F1 SET EMERGENCY
ALTER DATABASEASRS_F1 SET MULTI_USER
ALTER DATABASEASRS_F1 SET PARTNER OFF FORCE_SERVICE_ALLOW_DATA_LOSS
最后,关键的地方来了:
首先,Disable后restart,然后再Enable后restart:

接着,强制Failover,这次成功:
ALTER AVAILABILITYGROUP agASRS FORCE_FAILOVER_ALLOW_DATA_LOSS
最后,刷新后就是我们熟悉的:
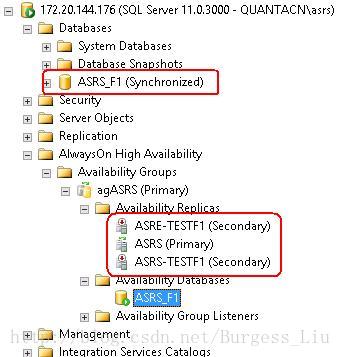
总结一下有效的步骤:
1、 通过如下命令强制重启Cluster:
net.exe stop clussvc net.exe start clussvc /forcequorum
2、Disable&Enable AlwaysOn Availability Groups
3、通过如下命令强制Failover:
ALTER AVAILABILITY GROUP agASRS FORCE_FAILOVER_ALLOW_DATA_LOSS
4、 刷新后,就是我们所熟悉的,能够正常访问数据库(状态变成已同步),此时你可以将DB移除AlwaysOn Group,此时DB的状态就恢复了单独运行的正常状态。