一种快速自适应的图像二值化方法介绍 (Wellner 1993)
在手机模式识别的时候, 我们首先viewfinder里面拿到的frame通常是RGB的或者YUV的, 如果我们需要用来做模式识别的话, 通常需要首先把彩色图首先转化成灰度图. 对于RGB图像而言, 网上有充足的公式, 比如Y = 0.299R + 0.587G + 0.114B 等等. 如果是YUV的话, 直接用Y就是灰度图了. 顺带说一句, 这种灰度图通常我们用.raw文件来表示, 用photoshop或者irfanview是可以直接打开看效果的. 比如说这里就有一个灰度图的例子

这个图就是现在很流行的所谓Data Matrix的sample, 我们用手机的照相机拿到的灰度图. 现在我们要把它变化成为黑白图(二值图). 在网上广为流传着很多办法. 什么双峰法, P参数法等等. 今天的办法和这些都不相同. 这个方法就是被称之为Quick Adaptive Thresholding algorithm, 提出这个观点的人名字叫做Pierre D. Wellner. 这里的网页上就有这个算法的说明:
http://www.xrce.xerox.com/Publications/Attachments/1993-110/EPC-1993-110.pdf
这个算法的基本思想要确定一个像素的黑或者白, 用他周围, 或者扫描顺序上的其他点的一些平均值来评估阀值就可以了.用阀值和像素值比较即可. 我们现在定义出这样的模型, 比方说我们用P(n)来表示第n个点的灰度值. T(n)来表示二值化后的值
用fs (n) 来表示第n个点之前s个点的灰度值的和, 就是

用这个s和另一个变量t就可以简单的说明P(n)应该是0还是1了, 这个公式就是
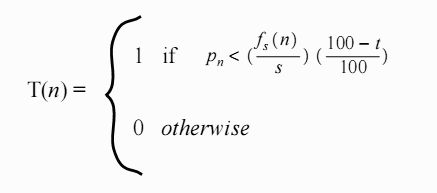
而且根据经验值来看, 这里的s和t最佳的取值范围是s= image.width/8, 而t=15的时候效果最好.
好的, 到这里为止, 我们的理解就是一个点t(n), 他是0还是1取决于什么呢? 就是前面s个点的和除以s (就是前s个点的平均值)*0.85 如果这个点的灰度值<前面的值, 那么就是1黑色, 如果大于就是0白色. 是不是非常简单? 至少到现在为止确实是的.但是这个算法有个问题, 我们忽略了一个问题, 就是我们现在定义T(n)的时候, 用的是平均值, 也就是说之前扫描过的若干点对于当前点的影响或者说权重是一样的, 也就是说当前点1个像素距离的像素和s-1个像素点的距离的像素的灰度值对当前点的影响是一样的. 显然根据我们直观的理解来看, 应该是离当前点越近的像素对当前点的影响越大, 越远则越小. 所以算法的作者发明了这个个更合适更高效的替代值gs (n). 这个值的意义就是:
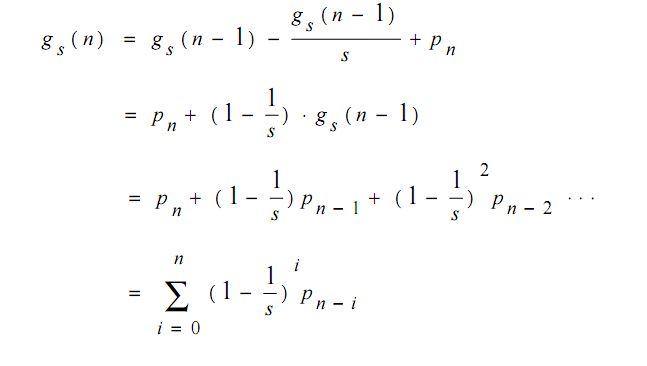
可以看到, 这里的gs (n) 和fs (n) 的区别在于fs (n) 直接是不做任何修正的s个灰度值的和, 而gs (n)则是一定比例的灰度值的和, 可以看到, 离这个n越近的像素的比重越高, 越远越低. 显然这样描述对把握像素的颜色更为准确. 而且这里的 gs (n)和 gs (n-1)通过加法和乘法就可以递归得到, 计算效率是比较高的.
即使到了这一步了, 还有一个问题存在, 就是我现在的颜色计算其实依赖于我的扫描顺序, 也就是说P(n)的这个序列的定义就是我的扫描顺序(一般都是水平扫描的). 这样的话, 我的像素值实际上取决于我水平位置上的邻接点的灰度值, 可是竖直方向的像素如何关联起来呢? 这里也有一个说明, 我们可以维护前面依次水平扫描产生的g_prev(n)序列, 在某个g(n)被使用之前, 我们可以让他和前一个g_prev(n)取一个平均值, 这样的话, 这个最终的值就更有说服力了.

好了, 到现在为止, 我们描述了整个算法的全过程, 在加上我们定义的初始g(n)值127*s(127表示0-255之间的中间值)就可以开始实现算法了
- void quickAdaptiveThreshold(unsigned char* grayscale, unsigned char*& thres, int width, int height )
- {
- /** /
- * | FOREGROUND, if pn < ((gs(n) + gs(n-w)) / (2*s)) *
- * color(n) = | ((100-t)/100)
- * | BACKGROUND_QR, otherwise
- * /
- * where pn = gray value of current pixel,
- * s = width of moving average, and
- * t = threshold percentage of brightness range
- * gs(n) = gs(n-1) * (1-1/s) + pn
- * gs(n-w) = gs-value of pixel above current pixel
- *
- */
- int t = 15;
- int s = width >> 3; // s: number of pixels in the moving average (w = image width)
- const int S = 9; // integer shift, needed to avoid floating point operations
- const int power2S = 1 << S;
- // for speedup: multiply all values by 2^s, and use integers instead of floats
- int factor = power2S * (100-t) / (100*s); // multiplicand for threshold
- int gn = 127 * s; // initial value of the moving average (127 = average gray value)
- int q = power2S - power2S / s; // constant needed for average computation
- int pn, hn;
- unsigned char *scanline = NULL;
- int *prev_gn = NULL;
- prev_gn = new int[width];
- for (int i = 0; i < width; i++) {
- prev_gn[i] = gn;
- }
- thres = new unsigned char[width*height];
- for (int y = 0; y < height; y ++ )
- {
- int yh = y * width;
- scanline = grayscale + y * width;
- for ( int x = 0; x <width; x ++ )
- {
- pn = scanline[x] ;
- gn = ((gn * q) >> S) + pn;
- hn = (gn + prev_gn[x]) >> 1;
- prev_gn[x] = gn;
- pn < (hn*factor) >> S ? thres[yh+x] = 0 : thres[yh+x] = 0xff;
- }
- y ++ ;
- if ( y == height)
- break;
- yh = y * width;
- scanline = grayscale + y * width;
- for ( int x = width-1; x >= 0; x --)
- {
- pn = scanline[x] ;
- gn = ((gn * q) >> S) + pn;
- hn = (gn + prev_gn[x]) >> 1;
- prev_gn[x] = gn;
- pn < (hn*factor) >> S ? thres[yh+x] = 0 : thres[yh+x] = 0xff;
- }
- }
- delete prev_gn;
- }
这个算法也不是我发明创造的, 这个算法从http://mikie.iki.fi/lxr/source/VisualCodeSystem/src/RecognitionAlgorithm.cpp?v=v3 这个网址上看过来. 不过是去除了一些Symbian的痕迹, 还有有的细节上做了一些改进, 让代码更加合理了些. 经过这个算法, 我们可以来看看效果了
原图1: 二值图1:

原图2: 二值图2:


我对这个效果还是比较满意的. 哈哈. 一直要写这个文章, 今天终于写完了, 心里真是痛快了.
Wellner 1993快速自适应的图像二值化方法的提高 (Derek Bradley and Gerhard Roth 2007)
前面一种方案实际上还是存在一定的问题的, 就是这个避重就轻的初始g(n)值127*s(127表示0-255之间的中间值), 这个东西带来的最直接的问题就是边缘的效果在这个算法下是不咋地的。 其实从这个所谓的"Wellner 1993", 后人又做了很多的改进, 使之效率更高, 效果更好。比方说这个Derek Bradley和Gerhard Roth搞的这个所谓 Adaptive Thresholding Using the Integral Image 在这个网页
http://www.scs.carleton.ca/~roth/iit-publications-iti/docs/gerh-50002.pdf 可以看到一些他的踪迹。
这个算法的基本思想是这样的,为了打破原来算法的初始值问题以及扫描顺序的问题, 这里的像素二值化的时候, 直接使用周围矩形像素的颜色作比较,这样来判断像素值更科学。我们对算法的介绍从求和面积表(Summed-Area Table)开始. 这个求和面积表简单点说就是维护一张表, 表中的元素值就是它左上位置的所有像素的像素值和。(数学公式在这里编辑简直是噩梦!只能放图了无图无真相:))
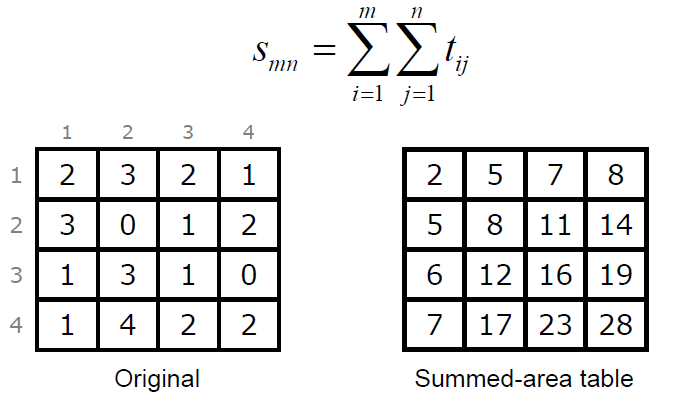
左边就是原始像素值, 右边的就是累加得到的表, 比方说这个表里面的(2,2)位置的8就是通过2+3+3+0得到的, 而这个最大值28就是所有像素的累加和。得到这个和和我们的二值化有什么关联呢?前面我们提到了在新的这个算法里面像素的值以来于周围像素的颜色, 那周围像素的颜色如何表示呢? 我们可以通过这个表轻松获得, 且看下面一张图:

这里的UL, LL, UR, LR表示的就是前面这个求和表里面的值, 如果我们要判断绿色区域中这个+号位置的值, 我们就要计算整个绿色区域的平均像素值, 如何计算呢? 有了新的表就方便了,右边其实给出了这个公式,这里的LR-UR-LL+UL就是整个绿色区域的像素值和。这个什么道理其实已经自己可以推断出来了, 如果还嫌这里不清楚的话,我们就给个更清楚的图:
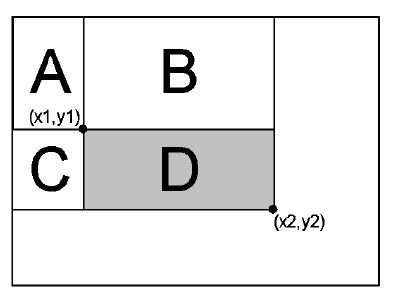
这个图和前面一样,但是如果还是用LR-UR-LL+UL来表示的话,这里就可以写成:
LR-UR-LL+UL = (A+B+C+D)-(A+B)-(A+C)+A = D, 这样就清楚很多了吧。 得到的这个值D就是D这个区域的像素值和, 那D中最中心的像素的颜色就可以用D/(widith*height)来做比较了。 所以算法的流程就是首先得到这个求和面积表, 其次遍历所有的像素, 然后以这些像素为中心点, 计算S*S大小的矩形的平均颜色, 用来和当前像素比较即可。这个流程可以说是相当精炼啊!这里依然用到了原来的S, T, 还保持了一致S是宽度的八分之一, 而T则是15,下面有一段我改过的实现代码:
- void adaptiveThreshold(unsigned char* input, unsigned char*& bin, int width, int height)
- {
- int S = width >> 3;
- int T = 15;
- unsigned long* integralImg = 0;
- int i, j;
- long sum=0;
- int count=0;
- int index;
- int x1, y1, x2, y2;
- int s2 = S/2;
- bin = new unsigned char[width*height];
- // create the integral image
- integralImg = (unsigned long*)malloc(width*height*sizeof(unsigned long*));
- for (i=0; i<width; i++)
- {
- // reset this column sum
- sum = 0;
- for (j=0; j<height; j++)
- {
- index = j*width+i;
- sum += input[index];
- if (i==0)
- integralImg[index] = sum;
- else
- integralImg[index] = integralImg[index-1] + sum;
- }
- }
- // perform thresholding
- for (i=0; i<width; i++)
- {
- for (j=0; j<height; j++)
- {
- index = j*width+i;
- // set the SxS region
- x1=i-s2; x2=i+s2;
- y1=j-s2; y2=j+s2;
- // check the border
- if (x1 < 0) x1 = 0;
- if (x2 >= width) x2 = width-1;
- if (y1 < 0) y1 = 0;
- if (y2 >= height) y2 = height-1;
- count = (x2-x1)*(y2-y1);
- // I(x,y)=s(x2,y2)-s(x1,y2)-s(x2,y1)+s(x1,x1)
- sum = integralImg[y2*width+x2] -
- integralImg[y1*width+x2] -
- integralImg[y2*width+x1] +
- integralImg[y1*width+x1];
- if ((long)(input[index]*count) < (long)(sum*(100-T)/100))
- bin[index] = 0;
- else
- bin[index] = 255;
- }
- }
- free (integralImg);
- }
这里也有一点效果图可以看看, 同时有和前面一个算法的比较:
原始1 wellnar算法 最新



还有一组:

wellnar:

最新算法:

这些个贴图其实还不是特别的具体, 其实这个算法特别适用于光照强度变化很大的像素, 这里有些网页也给出了鲜明的对比:http://www.derekbradley.ca/AdaptiveThresholding/index.html 效果的差距还是很明显的。 总的来说这个算法实现简单, 效率很高,确实是不错的选择。 而且还很新!在07年的杂志上发表的,现在记录下来与君共勉之!