Spark流编程指引(五)-----------------------------DStreams上的转换操作
与RDDs类似,转换操作允许对来自输入DStreams的数据进行修改。DStreams支持许多在通常Spark RDD上的转换操作。下面是一些常见的:
| 转换 | 含义 |
|---|---|
| map(func) | Return a new DStream by passing each element of the source DStream through a functionfunc. |
| flatMap(func) | Similar to map, but each input item can be mapped to 0 or more output items. |
| filter(func) | Return a new DStream by selecting only the records of the source DStream on whichfunc returns true. |
| repartition(numPartitions) | Changes the level of parallelism in this DStream by creating more or fewer partitions. |
| union(otherStream) | Return a new DStream that contains the union of the elements in the source DStream andotherDStream. |
| count() | Return a new DStream of single-element RDDs by counting the number of elements in each RDD of the source DStream. |
| reduce(func) | Return a new DStream of single-element RDDs by aggregating the elements in each RDD of the source DStream using a functionfunc (which takes two arguments and returns one). The function should be associative so that it can be computed in parallel. |
| countByValue() | When called on a DStream of elements of type K, return a new DStream of (K, Long) pairs where the value of each key is its frequency in each RDD of the source DStream. |
| reduceByKey(func, [numTasks]) | When called on a DStream of (K, V) pairs, return a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce function.Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config propertyspark.default.parallelism) to do the grouping. You can pass an optionalnumTasks argument to set a different number of tasks. |
| join(otherStream, [numTasks]) | When called on two DStreams of (K, V) and (K, W) pairs, return a new DStream of (K, (V, W)) pairs with all pairs of elements for each key. |
| cogroup(otherStream, [numTasks]) | When called on DStream of (K, V) and (K, W) pairs, return a new DStream of (K, Seq[V], Seq[W]) tuples. |
| transform(func) | Return a new DStream by applying a RDD-to-RDD function to every RDD of the source DStream. This can be used to do arbitrary RDD operations on the DStream. |
| updateStateByKey(func) | Return a new "state" DStream where the state for each key is updated by applying the given function on the previous state of the key and the new values for the key. This can be used to maintain arbitrary state data for each key. |
我们现在看一些值得讨论的转换操作:
UpdateStateByKey操作
UpdateStateByKey操作允许你保持任意的状态,同时用持续不断地新信息更新它。为了使用它,你需要做2步:
1.定义状态--状态可以是任意数据类型。
2.定义状态更新函数--定义一个函数,如何用先前的状态和输入流中的新值来更新状态。
我们现在用一个例子来说明。你想要保持一个来自文本数据流的每个单词的运行计数。这里,运行计数就是状态,它是一个整型。我这样定义更新函数:
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}val runningCounts = pairs.updateStateByKey[Int](updateFunction _)这个函数将在每个单词上调用,其中newValues参数是一个包含1的序列(来自(word,1)键值对),runningCount是前一次的计数。关于这个例子的Scala全部代码,可以查看StatefulNetworkWordCount.scala.
注意:使用updateStateByKey需要配置一个checkpoint目录。
Transform操作
Transform操作允许任意RDD-to-RDD类型的函数被应用在一个DStream上。通过它可以在DStream上使用任何没有在DStream API中暴露的任意RDD操作。比如,将DStream的每批数据加入另一个数据集的功能在DStream API中没有直接暴躁。但是,我们可以很容易地通过transform做到这一点。Transform使很多强大的功能变为可能。再比如,你想实时地清理加入到输入DStream中的垃圾邮件信息,并过滤它们。val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform(rdd => {
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
})事实上,你还可以在transform方法中应用机器学习和图计算算法。
Window操作
Spark流还提供了窗口计算操作,它允许你在一个滑动窗口的数据应用转换操作。如下图所示:
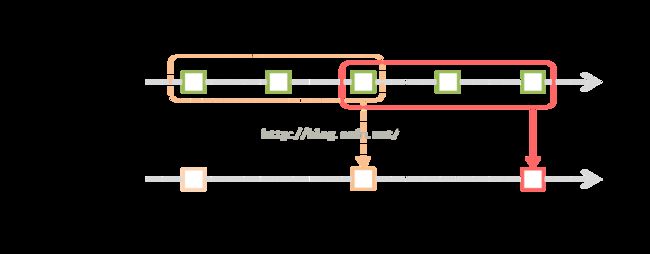
如上图所示 ,窗口在源DStream上滑动的每个时间点,在窗口中的RDDs被组合和计算用来产生出基于Window Dstream的RDDs.在这个例子中,操作被应用在最近三个时间单元中的数据,被划分成了2个时间段。每个窗口操作需要指定两个参数:
1.窗口长度:窗口的持续时间(图中是3个时间单元)
2.滑动区间:窗口操作应用的区间(图中是2个区间)
这两个参数必须是源DStream批次间隔的倍数(图中的批次间隔为1)
下面用一个例子来描述。我们仍拿前面章节中计算单词数的例子举例。我们现在要统计过去30s内每个单词的个数,每10s统计一次。我们需要在过去30s的(word,1)的DStream变量pairs上使用reduceByKey操作.要做到这些,需要使用操作reduceByKeyAndWindow
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))下面是一些常用的Window操作,所有操作都用到了上面所说的两个参数:
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | Return a new DStream which is computed based on windowed batches of the source DStream. |
| countByWindow(windowLength, slideInterval) | Return a sliding window count of elements in the stream. |
| reduceByWindow(func, windowLength, slideInterval) | Return a new single-element stream, created by aggregating elements in the stream over a sliding interval usingfunc. The function should be associative so that it can be computed correctly in parallel. |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, V) pairs where the values for each key are aggregated using the given reduce functionfunc over batches in a sliding window. Note: By default, this uses Spark's default number of parallel tasks (2 for local mode, and in cluster mode the number is determined by the config propertyspark.default.parallelism) to do the grouping. You can pass an optionalnumTasks argument to set a different number of tasks. |
| reduceByKeyAndWindow(func, invFunc, windowLength,slideInterval, [numTasks]) | A more efficient version of the above reduceByKeyAndWindow() where the reduce value of each window is calculated incrementally using the reduce values of the previous window. This is done by reducing the new data that enter the sliding window, and "inverse reducing" the old data that leave the window. An example would be that of "adding" and "subtracting" counts of keys as the window slides. However, it is applicable to only "invertible reduce functions", that is, those reduce functions which have a corresponding "inverse reduce" function (taken as parameter invFunc. Like inreduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. Note that [checkpointing](#checkpointing) must be enabled for using this operation. |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | When called on a DStream of (K, V) pairs, returns a new DStream of (K, Long) pairs where the value of each key is its frequency within a sliding window. Like inreduceByKeyAndWindow, the number of reduce tasks is configurable through an optional argument. |
Join操作
最后,我们关注一下怎样容易地执行不同类型的Join操作。
Stream-stream joins
Stream可以很容易地加入到其它Stream中:
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)leftOuterJoin,
rightOuterJoin,
fullOuterJoin。
更进一步,将流的每个窗口联合通常更加有用。这也很简单:
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)Stream-dataset joins
在前面DStream.transform中已经介绍过。这里是另外一个例子:
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }