Maya DG插件
一 概述
不要把DG(Dependency Graph)和DAG混淆,依赖图中的节点是用来负责控制动画和维护网格构建历史的,而DAG中的节点则用于定义外形节点以及它的空间位置。
DG插件的开发实质上是创建一些新的节点,将这些节点添加到依赖图中即可形成新的操作。Maya提供了十二种基本的类,派生自它们可以实现各种所需的功能。DG插件开发就是创建派生自这些基本类的新类,这些类都是以”MPx”开头,从文档Maya插件开发基础中可以知道这些类属于代理类,用于依赖图中构建各种节点。
基本的父类是”MPxNode”,派生自该类可以创建新的依赖节点(Dependency Node),它是Maya中最基础的DG节点。其他的十一个类均是派生自”MPxNode”。
二 基本示例
创建sine节点,向该节点输入一个值x,该节点就输出sin(x),为Maya/devkit/plug-ins/sineNode这个项目。
1 该类定义
#include <string.h>
#include <maya/MIOStream.h>
#include <math.h>
#include <maya/MPxNode.h>
#include <maya/MFnNumericAttribute.h>
#include <maya/MFnPlugin.h>
#include <maya/MString.h>
#include <maya/MTypeId.h>
#include <maya/MPlug.h>
#include <maya/MVector.h>
#include <maya/MDataBlock.h>
#include <maya/MDataHandle.h>
classsine : public MPxNode
{
public:
sine();
virtual~sine();
virtual MStatus compute(const MPlug& plug, MDataBlock& data );
static void*creator();
static MStatus initialize();
public:
static MObject input; // The input value.
static MObject output; // The output value.
staticMTypeIdid;
};
2 函数解析
<1> 构造造函数
在节点被创建的时候被调用,或者调用createNode命令、MFnDependencyNode::create方法的时候也会触发该节点的构造函数。
<2> 析构函数
被定义成虚析构函数(参见虚析构函数的作用,讲的是使用基类指针删除派生类的对象的时候,这个时候可以触发派生类的析构函数)。该析构函数只有在节点真正被删除的时候才被调用。由于Maya中使用撤销操作队列,删除一个节点并不会真正导致该节点的析构函数被调用,所以假如删除操作被撤销,这个节点又可以被找回来而不是重新创建。一般来说,一个删除节点的析构函数只有撤销队列被flush的时候才会被调用。
<3> compute函数
virtual MStatus compute(const MPlug& plug, MDataBlock& data );
compute函数是DG节点的大脑,它进行由输入生成输出这个过程的真正运算工作
<4> creator函数
static void*creator();
和命令插件中的creator函数功能一致。它用于让Maya实例化该节点的实例。在每次调用creatNode命令或者MFnDependencyNode::create函数的时候该函数会被调用
<5> 节点属性
public:
static MObject input; // The input value.
static MObject output; // The output value.
这两个MObject是这个sine节点的属性,这两个成员变量被设为静态变量。成员名称可以任意名称,在初始化节点的时候会为这些属性设定好类型和标签名。
<6> initialize函数
该函数被依赖节点的注册机制调用,当包含有用户定义节点的插件(文件)被加载的时候,该函数就会立即被调用。它用于定义节点的输入和输出(也就是节点的属性,为节点的实例定义,即后面创建节点的时候就创建对应的属性)。这从节点的属性被定义成静态变量就知道,这些属性不可能在实例化的时候被初始化,而是应该在实例化之前,那么插件被加载的时刻是个比较合适的时机。
MStatus sine::initialize()
{
MFnNumericAttribute nAttr;
MStatus stat;
input = nAttr.create("input","in", MFnNumericData::kFloat,0.0 );
nAttr.setStorable(true);
output = nAttr.create( "output","out", MFnNumericData::kFloat,0.0 );
nAttr.setWritable(false);
nAttr.setStorable(false);
stat = addAttribute( input );
if (!stat) { stat.perror("addAttribute");return stat;}
stat = addAttribute( output );
if (!stat) { stat.perror("addAttribute");return stat;}
stat = attributeAffects( input, output );
if (!stat) { stat.perror("attributeAffects");return stat;}
return MS::kSuccess;
}
定义一个属性的时候,必须指定一个长名称,一个对应的短名称(不超过三个字符)。这些名称可以在MEL脚本或者UI编辑器中使用用于指定特定的属性。虽然不是必须的,但是一般来说将属性的长名称设成与该属性在对应节点类中的变量名一致是个比较好的做法。
在上面的代码中,将输出属性的可写特性设为假,就表明该属性不能被其他节点写值,也就是说不可以将另一个节点的输出属性连接到该节点的输出属性上。同时将存储特性设为假,这是因为输出属性的值是通过输入属性计算而来的,没有必要在存文件的时候将该值存下来。
当实例化一个新的节点的时候,Maya将如下的特性默认设为真:
-
可读
-
可写
-
可连接(即是否允许其他的节点连接过来)
-
可存储(是否可以存成文件)
-
可设值
将如下的特性设为假:
-
multi(an array)
-
可设关键帧
-
indeterminant(属性也许不会使用这个特性,渲染相关)
-
隐藏(不在属性编辑器中显示)
这些特性指的是属性上的特性,因为一个DG节点最基本的数据都存放在属性上面。
属性创建好之后,就使用addAttribute函数将属性添加到节点中。然后使用attributeAffects函数建立两个属性之间的联系。在节点中可以创建多个输入和输出属性,但是总是输入属性影响输出属性。
<7> 节点ID
静态类型,用于和其他的不同类型的节点区分开来,与命令型插件中的一致。
<8> 插头(Plug)
插头可以看做是被重新计算的属性,参见compute函数里面的代码。
MStatus sine::compute(const MPlug& plug, MDataBlock& data )
{
MStatus returnStatus;
if( plug == output )
{
MDataHandle inputData = data.inputValue( input, &returnStatus );
if( returnStatus != MS::kSuccess )
cerr <<"ERROR getting data" << endl;
else
{
float result = sinf( inputData.asFloat() ) * 10.0f;
MDataHandle outputHandle = data.outputValue( sine::output );
outputHandle.set( result );
data.setClean(plug);
}
}
else
{
return MS::kUnknownParameter;
}
return MS::kSuccess;
}
在compute函数里,都是用来计算输出属性的值。但是由于节点可能有多个输出属性,所以必须要对当前传入的要计算的属性做一个校验,校验当前请求需要重新计算的属性是哪一个。上面代码中if( plug == output )将MPlug对象和MObject进行比较,可以比较是因为MPlug重载了与MObject比较的==操作符(参见MPlug定义)。
<9> 数据块
数据块包含了节点实例的所有数据。为了保证效率,这些数据被存储在一个单一的块中,使用特定的数据句柄来引用块中的某个数据。在上面的例子中,compute函数中
compute(const MPlug& plug, MDataBlock& data )的参数data就是整个节点的数据块,然后获取到输入属性的数据句柄:MDataHandle inputData = data.inputValue( input, &returnStatus );最后再使用该句柄来获取输入属性的值:float result = sinf( inputData.asFloat() ) * 10.0f;
完成计算和赋值操作后,需要将数据块中的插头标记为clean,表示它已经完成了重新运算,那么它后面的节点就可以使用该节点传出的数据了。
三 依赖图节点
依赖图(Dependency Graph)是一系列连接到一起的实体。和DAG不一样的是,DG中的这些连接可以循环的,并且它们也并不代表父级关系。相反,这些DG中的连接允许数据从一个实体流动到图中的另一个实体。图中接收和输出数据的实体被称为DG节点(即可以参与到图中的所有实体都可以成为DG节点)。
依赖图节点是依赖图的一部分,它们执行运算功能。一个节点接收一系列的输入数据(由连接到它的其他节点提供,或者被直接供给数据),然后使用它们输出数据。依赖图节点几乎被用于Maya中的任何地方,比如模型创建、变形,动画,模拟以及音频处理。
Maya中大多数对象都是DG节点,或者是网络节点(几个节点连接到一起)。例如,DAG节点就是DG节点,shaders都是网络节点。
当DG节点被连接到一起的时候它们可以影响DAG节点,随着也就影响那些被绘制。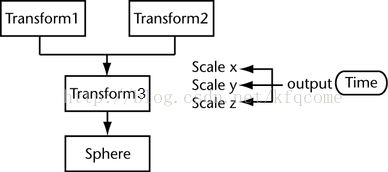
上图中将一个DAG结构和一个DG结合到一起,Time是一个DG节点,而其他的则是DAG节点,这里DG节点可以影响到DAG结构。
在图中流动的数据可以是简单的数字,也可是复杂的如曲面,还可以是用户定义的对象。依赖图包含一个非常复杂的结构,要解释清楚需要另外一个完整的篇幅,这里仅仅做一个大概的解释。
就像前面提到的,依赖图是一个方向图,图中的线将不同节点上的插头连接起来。数据沿着这些线发送,这些数据可以有基本的数据类型如数字、向量、矩阵,也可以有复杂如曲线、表面和用户自定义的类型。
作为Maya节点定义的一部分,必须指明哪些输入属性影响哪些输出属性(API中通过MPxNode::attributeAffects函数实现)。
如果一个节点的属性改变了,依赖图会检查这个属性是否会影响某个输出属性,假如会,所有被影响的输出属性都被标记为脏属性,意味着它缓存的数据是旧数据并且需要重新计算。接着对于这些重新计算后的输出属性,依赖图会检查它们是否是一些连接的数据源。如果是,那么就跟着这个连接继续处理,目的地的属性也被标记为脏属性需要进行重新处理。这个过程持续进行,直到图中最后一个受影响的节点对应的属性被标记为脏属性。需要注意的是在这个时候没有属性被重新计算,而是仅仅更改了状态表示其当前值不可用。那些不可用属性的状态评估和重新计算发生在不同的时期。
某些事件会促使DG重新评估它的状态,例如屏幕刷新、动画播放。在屏幕刷新的过程中,系统会深入DAG然后检查每个DAG节点看其是否需要被重新评估(通过检查该节点上的插口是否是脏的),如果是,影响插口的节点的计算函数会被重新调用,这个过程会上溯到需要重新计算的最顶层的节点。
一个优化的处理是DG如非需要的话不会重新估算。例如,一个环绕出来的曲面有三个节点,一个曲线DAG节点作为初始节点,然后一个节点用来环绕该曲线并生成曲面,该曲面就是输出到第三个节点的数据,第三个节点是一个DAG节点,它将曲面放置进DAG中。如果输入的曲线被更改了,曲面并不会立即被更改,即不会在下一次屏幕刷新前发生。在这个过程中,曲线被修改后,首先是导致下面的环绕节点和曲面节点的相关插口被标记为脏属性,然后在重新计算事件发生后进行重新计算,最后使得曲面也发生改变。
重新计算过程停止在第一个没有脏输入的节点(层级关系中的顶层节点)。就拿上面的例子来讲,改变环绕曲线的度数而曲线本身没有改变,那么重建环绕的曲面仅仅会导致环绕节点发生重新计算,而曲线节点不受影响。
流经依赖图的数据类似于在管道中流动的水一样。这些管道本身仅仅起个连接的作用,在没有数据的时候它们实质上不做任何事情。
延伸一下这个类比,那么图中的节点就像水龙头,浴室,喷泉,洗手间,它们都按各自独特的方式来处理水,但是首先它们必须有水来处理。
使用DG的一个有趣的副作用是不能直接的影响一个对象。
在上面图中的例子中,球的scale由时间节点控制,这个时候假如通过API或者UI来手动设定球的scale,在重新计算事件发生后,球的scale会设置为来自时间的值,原先手动设置的值就会被覆盖掉。
一个更复杂点的例子是前面的环绕曲面。如果试图去移动生成的曲面上的控制节点,会发生什么呢?这个控制节点会移动到新的位置,但是当DG被重新计算后,被移动的控制节点又会被移动回由环绕节点计算得到的位置。
但是为了制作更加复杂的模型,调整模型是一个很必要的操作。因而Maya设计了一个用于操作这些调整的机制。网格形状有一个属性,pnts,用于存放对于网格定点的局部位移。连接到该网格形状的上游节点生成一系列新的网格定点,但是并不会打算pnts属性。然后pnts属性内的值被添加到生成的网格上。对于NURBS曲面和其他基于控制点的节点,控制点属性存放了调整属性。Maya也提供了用于为一个基于控制点的节点存放调整信息的节点(tweak node)。调整节点被置于基于控制点的节点和生成控制点的节点之间,调整节点将调整信息和前面节点生成的控制点信息整合,生成最后的控制点然后将其传到形状节点。
四 节点
节点是驱动DG的引擎。数据进入到节点,然后节点执行一个操作,使新的数据变得可用。数据通过输入插口(也就是节点属性的实例化对象),然后通过输出节点传出。在任何时候一个节点不能请求插口之外的数据。
五 属性和插口
假如一个节点不能修改自身的数据那么它就是无用的。节点的修改通过属性和插口完成。
节点的属性定义了节点相对于图中其他节点的数据接口。节点在计算过程中互相传递的唯一数据就是通过这个接口进行。它们指明了什么类型的数据可以被接受,数据的名称(长名或短名)是什么,这个数据是否可以变成一个列表,以及数据是否允许传入传出节点。数据的类型包括简单数据类型例如整形、浮点型,以及复杂的例如点、多边形网格和NURBS曲面。
插口是用来存放对应属性数据的构建。所有对某个属性的数据访问都是通过插口。属性本身仅仅定义了数据的类型以及属性的名称。插口同时也是节点之间联系的端口。
属性可能被赋予默认值。假如属性的值没有被设定那么通过该属性上插口获取到的值就是默认值。例如,数值型的属性总是以0为默认值。
默认地,Maya会自动的将一个节点的属性在属性编辑器中排列显示。如果想要为节点属性设定一个特定的显示方式,可以为该节点写一个编辑器模板。这是一个在MAYA_SCRIPT_PATH目录下的MEL文件,文件名为AE{节点名}Template.mel,包含一个名为AE{节点名}Template的过程。该过程包含了一些编辑器模板命令,用于告知属性编辑器如何更改节点属性的默认布局。
六 复杂属性
默认情况下,一个属性只有一个对应的插口。这些属性被称为简单属性。一个属性也可以被定义包含一个特定长度的插口列表,这种类型的属性被称为数组属性,同时这个数组内的插口就被称为元素。每个元素插口可以包含自己的值,并且可以有其自己连接,同时这个数组可以稀疏的。每个元素的数据类型由属性确定,数组中的每个元素通过数组中的稀疏下标来确定。
Maya的Hypergraph和Connection Editor就会在属性的名称后面的方框[]中显示元素插口的下标。
多插口数组(array of plugs)通过另一个叫做数组插口(array plug)的来访问。这个插口在请求访问一个属性对应的插口的时候被返回。任意属性可以被定义为一个数组属性。这种设定通过使用MFnAttribute::setArray方法来完成,同时必须调用create方法创建属性之后调用。
注意:不推荐将一个数组插口连接到另一个数组插口
在用于包含数组数据的数组插口和简单插口之间必须指定一个显著的差别。它们两者都可以包含多个值,同时可以被称为“数组”。
在简单数组的情形下,数据类型为一个数组,例如pointArray或者intArray,这个数组被插口当做一个单独的数据项。当请求该插口的值的时候,整改数组都被返回。如果插口被连接到场景中的其他插口,整个数组都被沿着连接传递。
对于一个数组属性,属性的数据类型就是当个值的数据类型,例如是int或者double。这个数组来源于插口元素列表,每个包含一个单独的值。每个元素都是独立的连接着。数据项通过访问数组中的插口,从存储值的插口中获取单独的值。