初学字典树
字典树又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符; 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串; 每个节点的所有子节点包含的字符都不相同。
实现方法:
搜索字典项目的方法为:
(1) 从根结点开始一次搜索;
(2) 取得要查找关键词的第一个字母,并根据该字母选择对应的子树并转到该子树继续进行检索;
(3) 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索。
(4) 迭代过程……
(5) 在某个结点处,关键词的所有字母已被取出,则读取附在该结点上的信息,即完成查找。
其他操作类似处理
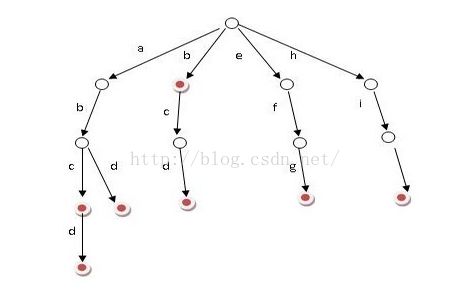
上面的树就是一颗典型的字典树了,字典树中存储的单词包括:abc、abcd、abd、b、bcd、efg、hig,即:所有标记为红心的是单词的结尾字母。对比上面的trie树的特点仔细看一下,理解一下到底什么是字典树。实字典树包括常见的两种操作是:查找和插入操作,删除不经常用。
动态空间基本代码:
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
typedef struct TrieNode{ //定义树的节点存储结构
int data; //可以表示一个字典树到此有多少相同前缀的数目
struct TrieNode *next[26];
TrieNode(){
data=0;
memset(next,0,sizeof(next));
}
};/*next是表示每层有多少种类的数,如果只是小写字母,26即可,若大小写字母,则是52,若再加上数字,则是62了,这里根
据题意来确定。*/
TrieNode *root=NULL;//根节点要初始化
//建树
void Build(char *c){
TrieNode *p=root; //定义指针,指向根结点
TrieNode *q=NULL;
int i,l=strlen(c);
for(i=0;i<l;i++){
if(p->next[c[i]-'a']==NULL){
q=new TrieNode; //构造新节点
p->next[c[i]-'a']=q;
}
p=p->next[c[i]-'a'];
p->data++;
}
}
//查找
void Find(char *c){
TrieNode *p=root;
int i,l=strlen(c);
for(i=0;i<l;i++){
if(p->next[c[i]-'a']==NULL){
printf("0\n");
return;
}
p=p->next[c[i]-'a'];
}
printf("%d\n",p->data);
}
int main(){
root=new TrieNode;
.
.
.
.
return 0;
}
注意:
1.根节点要初始化:
TrieNode *root=NULL;
2.有些题目,数据比较大,需要查询完之后删除、释放内存;
删除操作:
void Delate(TrieNode *root)
{
for(int i=0;i<N;i++)
if(root->next[i])
Delate(root->next[i]);
delete(root);
}例如: NYOJ的 http://http://acm.nyist.net/JudgeOnline/problem.php?pid=685查找字符串
题解: http://blog.csdn.net/xwxcy/article/details/50116117
静态空间基本代码:
这个代码段数存放数字的,根据题意修个next[];
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
int data_TrieNode;
struct TrieNode{
int data;
TrieNode *next[10];
void init(){
data=0;
memset(next,0,sizeof(next));
}
}Tree[100001];
inline TrieNode *new_TrieNode(){
Tree[data_TrieNode].init();
return &Tree[data_TrieNode++];
}
TrieNode *root=NULL;
void Build(char *c){
TrieNode *p=root;
TrieNode *q=NULL;
int i,v,l=strlen(c);
for(i=0;i<l;i++)
{
v=c[i]-'0';
if(p->next[v]==NULL){
q=new_TrieNode();
p->next[v]=q;
}
p=p->next[v];
p->data++;
}
}
int Find(char *c){
int i,v,l=strlen(c);
TrieNode *p=root;
for(i=0;i<l;i++)
{
v=c[i]-'0';
if(p->next[v]==NULL){
return 0;break;
}
else p=p->next[v];
}
return p->data;
}
int main()
{
data_TrieNode=0;
root=new_TrieNode();
.
.
.
.
return 0;
}