Hadoop的ChainMapper/ChainReducer
Hadoop的ChainMapper/ChainReducer
ChainMapper/ChainReducer主要为了解决线性链式Mapper而提出的。
ChainMapper:
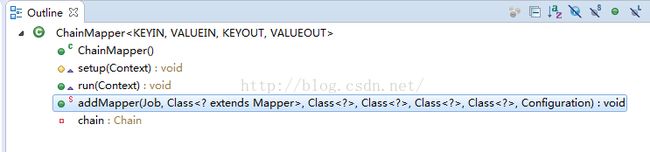
/**The ChainMapper class allows to use multiple Mapper classes within a single
* Map task.
*/
public class ChainMapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> extends
Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/**
* @param job
* The job.
* @param klass
* the Mapper class to add.
* @param inputKeyClass
* mapper input key class.
* @param inputValueClass
* mapper input value class.
* @param outputKeyClass
* mapper output key class.
* @param outputValueClass
* mapper output value class.
* @param mapperConf
*/
public static void addMapper(Job job, Class<? extends Mapper> klass,
Class<?> inputKeyClass, Class<?> inputValueClass,
Class<?> outputKeyClass, Class<?> outputValueClass,
Configuration mapperConf) throws IOException {
job.setMapperClass(ChainMapper.class);
job.setMapOutputKeyClass(outputKeyClass);
job.setMapOutputValueClass(outputValueClass);
Chain.addMapper(true, job, klass, inputKeyClass, inputValueClass,
outputKeyClass, outputValueClass, mapperConf);
}
}
ChainReducer:
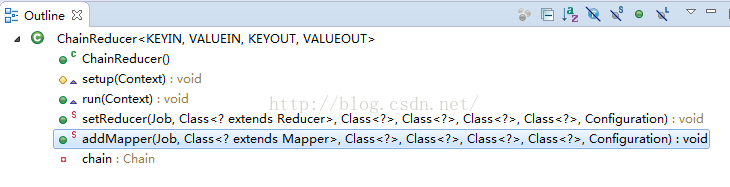
public class ChainReducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> extends
Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
/**
* @param job
* the job
* @param klass
* the Reducer class to add.
* @param inputKeyClass
* reducer input key class.
* @param inputValueClass
* reducer input value class.
* @param outputKeyClass
* reducer output key class.
* @param outputValueClass
* reducer output value class.
* @param reducerConf
*/
public static void setReducer(Job job, Class<? extends Reducer> klass,
Class<?> inputKeyClass, Class<?> inputValueClass,
Class<?> outputKeyClass, Class<?> outputValueClass,
Configuration reducerConf) {
job.setReducerClass(ChainReducer.class);
job.setOutputKeyClass(outputKeyClass);
job.setOutputValueClass(outputValueClass);
Chain.setReducer(job, klass, inputKeyClass, inputValueClass,
outputKeyClass, outputValueClass, reducerConf);
}
public static void addMapper(Job job, Class<? extends Mapper> klass,
Class<?> inputKeyClass, Class<?> inputValueClass,
Class<?> outputKeyClass, Class<?> outputValueClass,
Configuration mapperConf) throws IOException {
job.setOutputKeyClass(outputKeyClass);
job.setOutputValueClass(outputValueClass);
Chain.addMapper(false, job, klass, inputKeyClass, inputValueClass,
outputKeyClass, outputValueClass, mapperConf);
}
}
也就是说,在Map或者Reduce阶段存在多个Mapper,这些Mapper像Linux管道一样,前一个Mapper的输出结果直接重定向到下一个Mapper的输入,形成一个流水线,形式类似于[MAP+ REDUCE MAP*]。
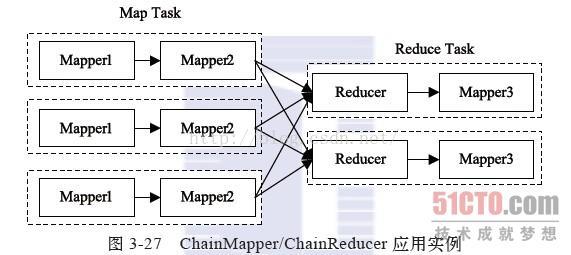
图展示了一个典型的ChainMapper/ChainReducer的应用场景:
在Map阶段,数据依次经过Mapper1和Mapper2处理;在Reduce阶段,数据经过shuffle和sort后;交由对应的Reducer处理,
但Reducer处理之后并没有直接写到HDFS上,而是交给另外一个Mapper处理,它产生的结果写到最终的HDFS输出目录中。
对于任意一个MapReduce作业,Map和Reduce阶段可以有无限个Mapper,但Reducer只能有一个
用户通过addMapper在Map/Reduce阶段添加多个Mapper。
该函数带有8个输入参数,分别是作业的配置、Mapper类、Mapper的输入key类型、输入value类型、输出key类型、输出value类型、key/value是否按值传递和Mapper的配置。
ChainMapper.addMapper(job, AMap.class,LongWritable.class, Text.class, Text.class, Text.class, true, mapAConf);
这主要是因为函数Mapper.map()调用完OutputCollector.collect(key,value)之后,可能会再次使用key和value值,
如果被改变,可能会造成潜在的错误。为了防止OutputCollector直接对key/value修改,ChainMapper允许用户指定key/value传递方式。
如果用户确定key/value不会被修改,则可选用按引用传递,否则按值传递。需要注意的是,引用传递可避免对象拷贝,提高处理效率,但需要确保key/value不会被修改。
实现原理分析
ChainMapper/ChainReducer实现的关键技术点是修改Mapper和Reducer的输出流,将本来要写入文件的输出结果重定向到另外一个Mapper中。结果的输出由OutputCollector管理,因而,ChainMapper/ChainReducer需要重新实现一个OutputCollector完成数据重定向功能。
尽管链式作业在Map和Reduce阶段添加了多个Mapper,但仍然只是一个MapReduce作业,因而只能有一个与之对应的JobConf对象。
然而,当用户调用addMapper添加Mapper时,可能会为新添加的每个Mapper指定一个特有的JobConf,为此,ChainMapper/ChainReducer将这些JobConf对象序列化后,统一保存到作业的JobConf中。
当链式作业开始执行的时候,首先将各个Mapper的JobConf对象反序列化,并构造对应的Mapper和Reducer对象,添加到数据结构mappers(List<Mapper>类型)和reducer(Reducer类型)中。
测试数据:
hadoop|9 spark|2 storm|4 spark|1 kafka|2 tachyon|2 flume|2 flume|2 redis|4 spark|4 hive|3 hbase|4 hbase|2 zookeeper|2 oozie|3 mongodb|3
设置为下图的结果:

结果:
flume 4 hadoop 9 hbase 6 hive 3 kafka 2 mongodb 3 oozie 3 redis 4 spark 7 storm 4 tachyon 2 zookeeper 2
设置为下图的结果:

结果:
hadoop 9
可以看到hadoop、hbase、spark本应都满足条件,但是只输出了hadoop,这也是原始输入数据唯一一个满足条件的,Key/Value并为改变。
代码:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
import org.apache.hadoop.mapreduce.lib.chain.ChainReducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class ChainMapperChainReducer {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage <Input> <Output>");
}
Job job = Job.getInstance(conf, ChainMapperChainReducer.class.getSimpleName());
job.setJarByClass(ChainMapperChainReducer.class);
ChainMapper.addMapper(job, MyMapper1.class, LongWritable.class, Text.class, Text.class, IntWritable.class,new Configuration(false));
ChainReducer.setReducer(job, MyReducer1.class, Text.class, IntWritable.class, Text.class, IntWritable.class,new Configuration(false));
ChainMapper.addMapper(job, MyMapper2.class, Text.class, IntWritable.class, Text.class, IntWritable.class,new Configuration(false));
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
job.waitForCompletion(true);
}
public static class MyMapper1 extends Mapper<LongWritable, Text, Text, IntWritable> {
IntWritable in=new IntWritable();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] spl = value.toString().split("\\|");
if (spl.length == 2) {
in.set(Integer.parseInt(spl[1].trim()));
context.write(new Text(spl[0].trim()),in);
}
}
}
public static class MyReducer1 extends Reducer<Text, IntWritable, Text, IntWritable> {
IntWritable in=new IntWritable();
@Override
protected void reduce(Text k2, Iterable<IntWritable> v2s, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
Integer uv = 0;
for (IntWritable v2 : v2s) {
uv += Integer.parseInt(v2.toString().trim());
}
in.set(uv);
context.write(k2, in);
}
}
public static class MyMapper2 extends Mapper<Text, IntWritable, Text, IntWritable> {
@Override
protected void map(Text key, IntWritable value, Mapper<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
if (Long.parseLong(value.toString().trim()) >= 5) {
context.write(new Text(key.toString().trim()), value);
}
}
}
}