c专家编程学习
unix系统是在19701月1日诞生, 所以unix系统的系统时间是从19701月1日开始按秒计算的。
发展:
汇编-->B语言--->new B--->C语言(c伴随unix发展起来的)
c语言的很多特性是为方便编译器设计者而开发的, 比如数组从0开始, 基本类型与硬件对应, auot关键字只对创建符号表入口的编译器设计者有意义, 数组有时可以看做指针, 早起c语言float会自动转换为double, 不允许嵌套函数(事实上新版c支持, 看连接http://blog.csdn.net/brucexu1978/article/details/7179709), register关键字。
剑桥的stev编写了bourne shell
c, c++在1985进行了整合, c++开始开发与1967年的simula67,
ada语言在1983年整合到c++。
op=比=op的实现清晰(指复合语句), 不易引起混淆, 不如 b = -3 会分不清是-3还是减3. 而b -=3则不会有这样的担心。
ansi:美国国家标准化组织
1989,12 ansi接纳ansi c。 随后iso也接纳ansi c,(iso删除了rationale(相当于汇总)部分: 见http://www.lysator.liu.se/c/rat/title.html)
c语言的官方标准是:iso/iec 9899:1994
ansi c:
形参的上限至少达到31个
实参的上限至少达到31个
在一条源代码行里至少可以有509个字符
在表达式中至少可以支持32层嵌套的括号
long行至少32位宽
ansi c的运行时库是基于/user/group1984年的标准。去除了一些unix特有的部分。这个组1989年更名为UniForum, 一个非营利组织, 旨在完善unix
相邻的字符串字面值会被自动连接在一起。“ABC”"EFG" = "ABCEFG"
函数的原型中可以省略参数名称, 只需类型, 写上名称的好处是:含义清晰
char * 能赋值给const char *, 因为类型相容(左与右相容 char *), 相反则不行, 原因是(左, 右不相容const char *)
char **和const char **不相容, 原因在于char *和const char *不相容。但现在的c编译器通常允许这样的赋值,原因是直观, 尽管不合标准(报warning)。
const *: 指针指向的变量的内容不能用这个指针改变
* const: 指针不能改变
sizeof()返回unsigned int类型的值
尽量不要使用unsigned类型, 原因在于会产生很大的数, 这在实际项目经验中也会遇到, 比如java jni没有unsigned类型, 如果底层用了, 就有点麻烦了。
较低版本的gcc不支持ansi c的#pragma, 新版支持, 但在#pragma中不支持宏替换。
在不支持虚拟内存的操作系统中是很难检测到内存访问越界的, 内存越界是操作系统的范畴。比如dos就是这样。
ansi c的编译器中至少支持一个switch 有257个case(256个值加一个eof)
现在的较新的编译器似乎并不支持在switch的花括号之后定义局部变量。当然用花括号可以建一个块,然后定义一些局部变量。
允许变量的申明出现在for循环的for语句中,大概是c++和gcc的事情
switch 中允许使用标签, 这带来一个可能连lint都无法检查出来的issue: 把default的小写的l写成了数字1.
case后面跟的是常量, 所以即使像const限制的变量, 也是不能作为case的检查条件的。
千万记住:
break用在循环和switch中, 而不是if中。
ansi c允许数组末尾逗号, 但不允许单行多变量末尾逗号, 也不允许枚举申明末尾逗号, 这是个奇怪的嗜好。
缺省情况下, 函数的名字是全局可见的(extern), 如果想限制就加static,
interpositioning: 取代库函数????
sizeof: 当用类型作为参数时必须加括号, 但如果是变量,则不必加括号, 建议统一加括号, 不然, 遇到指针时, 会含义不明显。
这种情况也请多加上括号 sizeof(int) * p--->(sizeof(int)) * p 或者 sizeof((int) * p).
.优先级高于*(例如*(p.f))
[]高于*(例如int *(ap[]): ap是元素为int指针的数组)
int (*ap)[]: ap是指向int数组的指针
函数()高于*: (例如: int * (fp()): fp是个返回int *的函数)
int (*fp)():fp是个函数指针,所指函数返回int形
==,!=高于位操作符:(比如: cal & (mask != 0))这个一定要注意!
==, != 高于赋值运算符: (比如: c = (getchar() != EOF))
算数运算符高于移位运算符: (比如: msb << (4 + lsb))
逗号运算符在所有运算符中优先级最低: (比如: (i = 1), 2)
关于优先级和结和性, 参见
http://blog.csdn.net/brucexu1978/article/details/7191212
简单记就是:! > 算术运算符 > 关系运算符 > && > || > 赋值运算符
一个例子:
a=b=c=1; ++a||++b&&++c; 问语句执行顺序?
解:
c =1;
b = c;
a = b;
++a;
++b;
++c;
(b&&c)
a||(b&&c)
蠕虫病毒:
利用gets库函数的漏洞, 赋一个超过512字节的串(这个串是在栈上分配的, fingerd进程), 并用特定的字符修改栈的函数返回地址, 使之运行一个与远端的shell回话的进程, 然后拷贝病毒到其他机器上, 现在用fget代替get,有size检查, 来防止这样的问题。
linux shell搜索符号链接的方法:
find -n *|grep link;
而不是ls -l|grep -> 或者 ls -l |grep "->":因为shell会解释不对后面两种形式: 对于第一形式, shell认为是重定向符, 对于二, shell认为是大于号的未知组合
z = y+++x----> z = (y++) + x
z = y+++++x--->引起编译错误, 可能需要空格:z = y++ + ++x
ratio = *x/*y--->可能也会引起编译错误, 需要在/ 和*之间有空格。
一个有趣的关于注释:
a //*
//*/ b
:在c中, 被解释成a/b, 而在c++中, 表示a;
:c用 /* */注释, 而c++除了c风格的,还采用了//
竟然有过宇宙飞船在检查货物质量时,看到软件质量是0的时候, 引起慌乱和争论的事情!!!!!
const int * var; // var指向的内容是常数
int const * var; // var指向的内容是常数
int * const var; // var指针时常数
int const * const var; //指针和内容都是只读的。
函数的返回值不能是函数, foo()()非法
函数的返回值不能是数组, foo()[]非法
数组里面不能有函数, foo[]()非法
函数的返回值可以是函数指针: 比如int (* fun())()
函数返回值允许是一个指向数组的指针; 比如
数组里面允许有函数指针
数组里面允许有数组
例子:
#include <stdio.h>
typedef int (*Test) (int a); //声明一个Test函数指针
int test(int a) //定义和实现一个函数
{
printf("test prog, a = %d\n", a);
return a;
}
int (*func(int b, int c))(int a) //定义和实现一个返回函数指针的函数
{
printf(func prog, b = %d, c = %d\n", b, c);
return test; //返回前述的函数
}
typedef Test (*funcP)(int b, int c); //定义一个指向返回函数指针的函数指针类型
int main()
{
int i = 0;
int j = 0;
int k = 0;
funcP pFunc = func;
Test (*testP1)(int b, int c) = func; //不用typedef定义和初始化返回函数指针的函数的指针
printf("pFunc = 0x%x, testP1 = 0x%x\n", pFunc, testP1);
if (pFunc != NULL) {
Test pfunc = pFunc(100, 200); //定义和初始化函数指针, 打印func proc, b = 100, c = 200
int (*testp) (int a) = func(10, 20); //不使用typedef方式声明和初始化函数指针, 打印func proc, b = 10, c = 20
printf("pfunc = 0x%x, testp = 0x%x\n", pfunc, testp); //这里pfunc和testp应该相等。
i = pfunc(5000); //运行函数, 打印test prog, a = 5000
j = testp(50);//运行函数, 打印test prog, a = 50
printf("i = %d, j = %d\n", i, j); //打印5000, 50
}
if (testP1 != NULL) {
Test pfunc1 = testP1(1000, 2000); //打印func proc, b = 1000, c = 2000
k = pfunc1(50000); //打印test prog, a = 50000
printf("k = %d\n", k);// 打印50000
}
return 0;
}
另可参考这个link:
http://spring-studio.net/?p=5
结构支持位段, 无名字段, 及对齐所需的填充字段, 例如:
struct pid_tag {
unsigned int inactive :1;
unsigned int :1;
unsigned int recount :6;
unsigned int :0;
short pid_t;
struct pid_tag link;
};
结构赋值可以拷贝整个结构, 这里带来一个技巧, 如果期望把整个数组赋值, 可以把数组放在结构中。
枚举相较于define的一个优点是define在编译时名字替换了。
声明的优先级规则:
1. 声明从名字开始读取,
2. 优先级顺序是:
2.1 声明中被括号括起来的部分
2.2 后缀, "()"表示函数, "[]"表示数组
2.3 前缀, 星号表示指向...的指针
3. 如果 const和/或者volatile的后面经跟类型说明符(如int等), 那么它作用于类型说明符(内容是const), 在其他情况下, 作用于左边紧邻的指针星号(指针是const)。
char * const *(*next)();
1. next
2..1 next是个指针
2.2 next是一个函数指针(后缀)
2.3 得出指针所指的内容,(前缀)
3. char * const 解释为指向字符的常量指针
整体,就是: next是一个指针, 指向一个函数, 该函数返回另一个指针, 该指针指向一个类型为char的常量指针。
int array[100]; //定义, 会分配对象
extern int arra[100]; //声明, 不分配对象, 对于多维数组,可不填写最左边一维的长度
数组名是个左值, 但不是可修改的左值,
把指针当成数组来用时, 是先从指针取得数组的地址(不一定是数组的首地址), 然后再加上偏移量
比直接数组的方式多了个取地址的过程
不能定义是指针, 申明却为数组
指针可以指向字符串常量, 通常这个常量位于只读区域, 不能尝试通过指针修改它。但是可以通过字符串常量所在的数组修改字符串(不能称谓常量了吧)。
不能让指针指向浮点型等的常量, 因为没有分配对象空间。
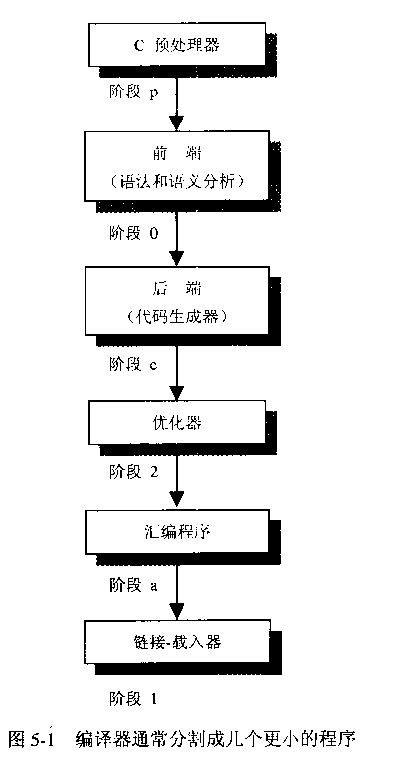
在编译的时通过 -W*来指明后面的其他的编译选项是传递给哪个阶段, 比如-W1 -m, 是把-m传给链接载入器。
所有动态链接到某个特定函数库的可执行文件在运行时共享该函数库的一个单独拷贝(这种共享应该不会引起全局变量使用的竞争问题。)
-G编译选项生成动态共享库(cc编译器, 不确定GCC是不是这样)
-L: 告诉编译器在链接时查找库的路径
-R: 告诉程序在运行时查找的库路径
-l: 链接的库名称
-K pic: 生成位置无关的代码。 位置无关的代码使得链接器可以把这部分代码安排在任何空闲的位置, 而不必映射到固定的位置,
网上关于pic的解释:
“
首先,需要理解加载域与运行域的概念。加载域是代码存放的地址,运行域是代码运行时的地址。为什么会产生这2个概念?这2个概念的实质意义又是什么呢?
在一些场合,一些代码并不在储存这部分代码的地址上执行地址,比如说,放在norflash中的代码可能最终是放在RAM中运行,那么中norflash中的地址就是加载域,而在RAM中的地址就是运行域。
在汇编代码中我们常常会看到一些跳转指令,比如说b、bl等,这些指令后面是一个相对地址而不是绝对地址,比如说b main,这个指令应该怎么理解呢?main这里究竟是一个什么东西呢?这时候就需要涉及到链接地址的概念了,链接地址实际上就是链接器对代码中的变量名、函数名等东西进行一个地址的编排,赋予这些抽象的东西一个地址,然后在程序中访问这些变量名、函数名就是在访问一些地址。一般所说的链接地址都是指链接这些代码的起始地址,代码必须放在这个地址开始的地方才可以正常运行,否则的话当代码去访问、执行某个变量名、函数名对应地址上的代码时就会找不到,接着程序无疑就是跑飞。但是上面说的那个b main的情形有点特殊,b、bl等跳转指令并不是一个绝对跳转指令,而是一个相对跳转指令,什么意思呢?就是说,这个main标签最后得到的只并不是main被链接器编排后的绝对地址,而是main的绝对地址减去当前的这个指令的绝对地址所得到的值,也就是说b、bl访问到的是一个相对地址,不是绝对地址,因此,包括这个语句和main在内的代码段无论是否放在它的运行域这段代码都能正常运行。这就是所谓的位置无关代码。
由上面的论述可以得知,如果你的这段代码需要实现位置无关,那么你就不能使用绝对寻址指令,否则的话就是位置有关了。”
这个没有清楚的解释pic。
| >> 位置无关代码与可重入代码有什么关系吗? 没有关系,位置无关代码是指该代码在任何地址处都能执行,可重入代码指该代码可以并行执行而不会出问题(没有引用全局变量或引用了且用锁做了保护) >>在链接时,只有表示global的符号需要地址解析吗? 应该是UND的吧
|
这个帖子提了一个关于这方面的问题。
http://topic.csdn.net/u/20080901/18/db7e16f3-ebda-405e-b3b8-03a23489eb10.html
我的评论是, 如果你在linux下, 想通过这样的方式直接跑这段代码是不行的, 因为linux下的代码的执行需要加载器安排地址。而直接copy意味着有些地址之间的关联没有重新安排, 会找不到的(部分可运行, 部分不行)。 另外, 我是这么想的如果能这样随便运行程序,那算不算linux的问题?
还有, 即使你拷贝过去了, 又怎样跳到哪里呢?
pic对于共享库来讲, 有点在于连接它的程序, 不需要通过更新页表的方式, 把它映射到固定的地址。
可用nm命令查找库所包含的函数名, 前提是没有strip过
始终将-l的库选项放在编译选项的最右边
interposition: 可用用户自己编写的函数替换库函数。此时其他库函数对此函数的调用也可能使用用户定义的函数。
链接器的-m选项产生内存映射表, 可通过这张表查看是否发生了interposition
链接器的-D选项允许用户显示链接编译编辑过程和所包含的输入文件
ldd命令用于查看库的依赖关系
size命令可以查看.out/elf等文件的text, dat, bss段的信息
BSS段保存没有初始值的变量, bss段不包含在目标文件中, 它在运行时分配这个段
上图右边是运行时分布, 最后部分未映射区域不能对其引用, 用于存放空指针引用, 小整型的值的引用
另外共享库会在运行时被安排在本out文件的bss之后的空洞之后, 放在链接器之前的空洞之前, 堆栈始终放在最后面, 所谓空洞是指未映射区域。
allca函数在堆栈中分配空间
垂悬指针(dangling pointer):
auto关键字其实没什么大用。
每个线程的堆栈之间有个red zone page
setjmp(j): 设置跳转点, 用j记录当前调用setjmp时的位置, 返回0
longjmp(j , i): 跳到j所指的setjmp处, 从setjmp返回, 返回值是i, 这里也用j, 意味着可以同时设几个jmp点
这对函数可以跨函数, 跨文件, 必须setjmp在前
下表列了一些工具, 很少用了, cscope/ctags到是常用, lint是编译器内建的?!!
所有磁盘厂商使用十进制表示硬盘大小
__near: 16位指针
__far: 32位指针, 但在一个段中
__huge: 无限制
cache存储器位于cpu和存储器之间, 有的使用虚拟地址, 有的使用物理地址, 当从内存读的时候, cache按行读取(16/32字节),
write through: 每次写cache总同时更新到内存
write back: 写cache直到cache需要写到内存,(比如本cache中的数据还没写到内存, 又写cache了, 还有进程切换也需要)
考虑到cache的影响, 应该尽量用库函数, 因为有可能源地址和目标地址不同时在cache中,
malloc的内存一般是2的幂
可用alloca在栈上分配内存, 退出调用函数时释放
对于一个未定义的指针, 如果它的地址正好是未对齐的, 会报总线错误, 而不是段错误, 这是因为cpu先知道地址
页面换出到磁盘是在进程被切换出去的时候。
系统不支持在信号处理函数里面调用库函数?!!
不管函数的参数是 定义成指针形式还是还是数组形式, 也不管它是一维还是两维, 这个参数都被弱化成指针, 用sizeof都会得到4(32bit系统)或者8(64位系统)
函数的形参可以用数组的方式定义, 但是必须指明除最左边一维之外的所有维的size。这样使用就很有限制了。 通常还是用额外的参数表明个数的方式处理数组的传递。
只有字符串常量才可直接初始化指针数组, 否则必须先定义数组维的变量, 再用这些变量初始化指针数组(总之指针维必须有地址)。
定义返回数组的函数:
形如:
int (*func())[20]: func函数返回指向长度为20的数组的指针。
ansi c中只能用静态数组, gcc/c++等倒是可以。
ansi c可用指针指向动态生成的数组。