机器学习---分类和测度
课上老师还提到了:GMM和GGM~~本文没有讲哈
以下使用到的图片来自上海交大杨旸老师的课件,网址如下:http://bcmi.sjtu.edu.cn/~yangyang/ml/
分类比较简单,就简单写写了。
分类就是我们拿到一堆数据,怎么把它们分到不同的类别中呢?训练过程可以是监督或者非监督的。
主要思想就是:距离近的就是一类,距离远的就分为别的类了。
那么什么是距离?距离需要满足以下特性:

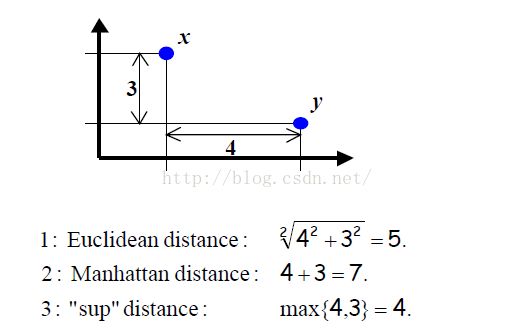
下边举了几个我们常见的距离:

来个例子形象生动地解释一下不同的距离咯:
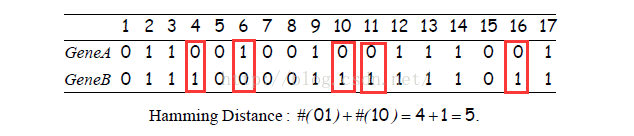
下边是基因中常用的距离(Hamming distance)
这些相关系数其实也是距离的表示方法:

编辑距离:和上边基因比较像

分类的方法总的分为两种:
划分式:从一个随机初始的划分开始,然后使用K-means clustering 或者Mixture-Model based clustering训练修改模型。
分层式:自底向上或者自顶向下,可以建立一个树。你需要几个类,就可以从树的某一层砍掉,下边的各个小分支就是了。
两类数据之间的距离有以下四种度量方式:
1、single-link: 类别之间最近的两个点的距离
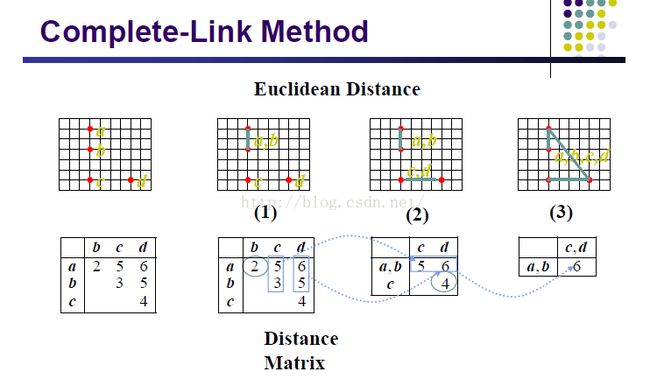
2、complete-link:类别之间距离最远的两个点的距离
3、centroid:Clusters whose centroids (centers of gravity) are the most cosine-similar
4、average:两个类别中两两算距离求平均。
来两个例子:

Partition algorithms;
要求:把数据分为K类
输入:一组数据,分类数K
找到分类规则:1、全局最优:枚举所有可能的分类规则选个最好的
2、启发式方法:K-means and K-medoids algorithms
K-means:
随机初始化K个点
对于每个样本点在初始化的K个点中找到与他最近的那个,分类一次,计算中心作为下一次的K个点。
不断循环。直到我们满意为止。
这个方法会收敛的。
结果与你初始化的那个点也有关系,如果初始化比较好,那么分类效果也会好一些,所以可以多试几个不同的初始点或者用其他方法初始化点或者用启发式方法(具体看你自己选择咯)选好的点。
具体分为几类,这个得根据经验来吧。
怎么判断我们训练得到的分类器好还是不好呢?

纯度:解释一下~
看下图,我们用训练数据训练好了分类器,就把测试数据(有标签,先不用)带到这个分类器中,然后得到了测试标签,和之前的标签对比,哪个类别的数量多,就用这个数字作为分子,测试得到的分类结果中该类总数为分母,就是了。一般来说,纯度越高,分类器越好。


下面来说一下半监督学习测度学习:

左边那个数据不太容易分开的, 但是他们是怎么转化成右边呢?就是用了测度
其实就是乘了个矩阵把坐标变了一下,和svm的核的概念差不多。但是没有改变维度
如果 xi 和 xj 比较近,那么(xi ,xj)就在S里边 ——(这里的 x 是点,也就是一个样本,不是特征哈,和上边要区分一下)
如果 xi 和 xj 比较远,那么(xi ,xj)就在D里边
S 和 D 只是为了下边算的时候方便理解,最终分类的数据还是点 x 。(xi ,xj)这个距离就是测度。

下边是选取A的方法:

就是数据都用A(A >= 0)处理之后在D中的测度大于1的情况下,在S中的测度们最小。我们要求的就是满足这个条件的A。
下边列举一些例子:
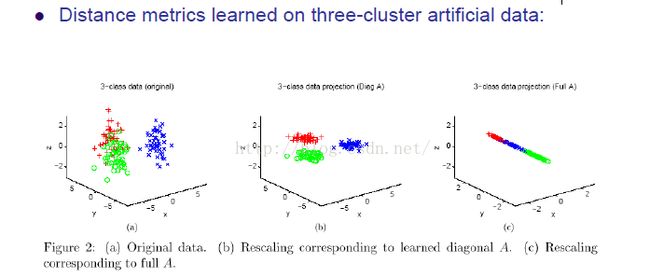
上图:a是原本的数据集,b是只用了A的对角线乘了数据,c是用整个A乘了数据
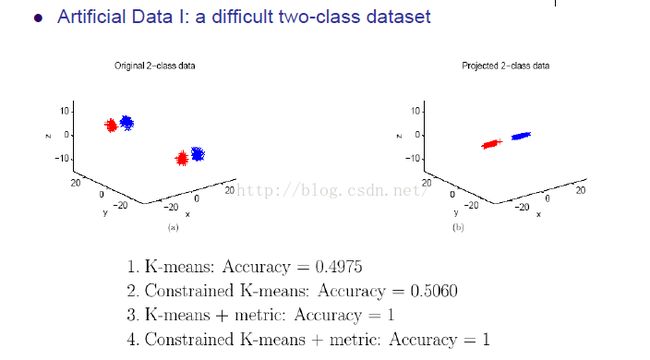

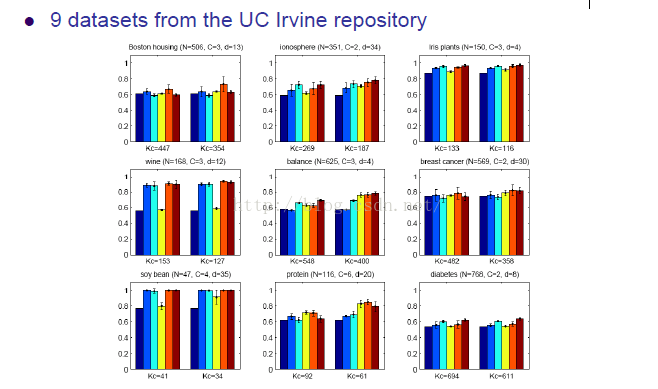
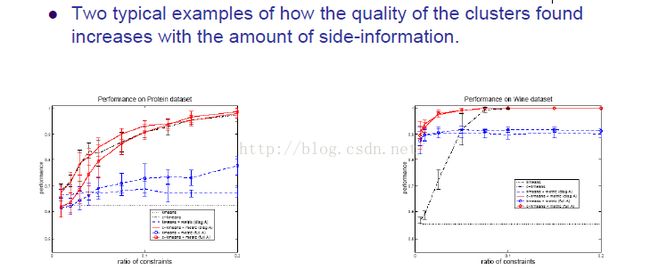
上图就是当边缘信息增加的时候,分类器的性能提升速度。字略小,随意感受下,嗯。。。

1、距离测度很重要
2、好的距离测度可以从比较小数量的边缘信息(属于S还是D)中获得
3、距离测度在特征空间找到更好的距离,有效地进行特征选择(特征选择见上一篇文章)
4、距离测度用于提升分类效果
Wish you a good weekend !