kmeans聚类练习
聚类算法,不是分类算法。
分类算法是给一个数据,然后判断这个数据属于已分好的类中的具体哪一类。
聚类算法是给一大堆原始数据,然后通过算法将其中具有相似特征的数据聚为一类。
这里的k-means聚类,是事先给出原始数据所含的类数,然后将含有相似特征的数据聚为一个类中。
所有资料中还是Andrew Ng介绍的明白。
首先给出原始数据{x1,x2,...,xn},这些数据没有被标记的。
初始化k个随机数据u1,u2,...,uk。这些xn和uk都是向量。
根据下面两个公式迭代就能求出最终所有的u,这些u就是最终所有类的中心位置。
公式一:
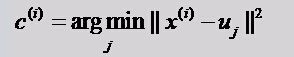
意思就是求出所有数据和初始化的随机数据的距离,然后找出距离每个初始数据最近的数据。
公式二:
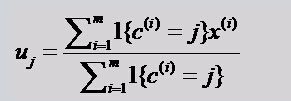
意思就是求出所有和这个初始数据最近原始数据的距离的均值。
然后不断迭代两个公式,直到所有的u都不怎么变化了,就算完成了。
kmeans实例一:
%随机获取150个点
X = [randn(50,2)+ones(50,2);randn(50,2)-ones(50,2);randn(50,2)+[ones(50,1),-ones(50,1)]];
opts = statset('Display','final');
%调用Kmeans函数
%X N*P的数据矩阵
%Idx N*1的向量,存储的是每个点的聚类标号
%Ctrs K*P的矩阵,存储的是K个聚类质心位置
%SumD 1*K的和向量,存储的是类间所有点与该类质心点距离之和
%D N*K的矩阵,存储的是每个点与所有质心的距离;
[Idx,Ctrs,SumD,D] = kmeans(X,3,'Replicates',3,'Options',opts);
%画出聚类为1的点。X(Idx==1,1),为第一类的样本的第一个坐标;X(Idx==1,2)为第二类的样本的第二个坐标
plot(X(Idx==1,1),X(Idx==1,2),'r.','MarkerSize',14)
hold on
plot(X(Idx==2,1),X(Idx==2,2),'b.','MarkerSize',14)
hold on
plot(X(Idx==3,1),X(Idx==3,2),'g.','MarkerSize',14)
%绘出聚类中心点,kx表示是圆形
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',14,'LineWidth',4)
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',14,'LineWidth',4)
plot(Ctrs(:,1),Ctrs(:,2),'kx','MarkerSize',14,'LineWidth',4)
legend('Cluster 1','Cluster 2','Cluster 3','Centroids','Location','NW')
Ctrs
SumD

实例二:
main.m
%第一类数据
mu1=[0 0 0]; %均值
S1=[0.3 0 0;0 0.35 0;0 0 0.3]; %协方差
data1=mvnrnd(mu1,S1,100); %产生高斯分布数据
%%第二类数据
mu2=[1.25 1.25 1.25];
S2=[0.3 0 0;0 0.35 0;0 0 0.3];
data2=mvnrnd(mu2,S2,100);
%第三个类数据
mu3=[-1.25 1.25 -1.25];
S3=[0.3 0 0;0 0.35 0;0 0 0.3];
data3=mvnrnd(mu3,S3,100);
%显示数据
plot3(data1(:,1),data1(:,2),data1(:,3),'+');
hold on;
plot3(data2(:,1),data2(:,2),data2(:,3),'r+');
plot3(data3(:,1),data3(:,2),data3(:,3),'g+');
grid on;
%三类数据合成一个不带标号的数据类
data=[data1;data2;data3]; %这里的data是不带标号的
%k-means聚类
[u re]=kmeans(data,3); %最后产生带标号的数据,标号在所有数据的最后,意思就是数据再加一维度
[m n]=size(u);
%最后显示聚类后的数据
figure;
hold on;
for i=1:m
if u(i,1)==1
plot3(data(i,1),data(i,2),data(i,3),'ro');
elseif u(i,1)==2
plot3(data(i,1),data(i,2),data(i,3),'go');
else
plot3(data(i,1),data(i,2),data(i,3),'bo');
end
end
grid on;
KMeans.m
%N是数据一共分多少类
%data是输入的不带分类标号的数据
%u是每一类的中心 re
%re是返回的带分类标号的数据 u
function [u re]=KMeans(data,N)
[m n]=size(data); %m是数据个数,n是数据维数
ma=zeros(n); %每一维最大的数
mi=zeros(n); %每一维最小的数
u=zeros(N,n); %随机初始化,最终迭代到每一类的中心位置
for i=1:n
ma(i)=max(data(:,i)); %每一维最大的数
mi(i)=min(data(:,i)); %每一维最小的数
for j=1:N
u(j,i)=ma(i)+(mi(i)-ma(i))*rand(); %随机初始化,不过还是在每一维[min max]中初始化好些
end
end
while 1
pre_u=u; %上一次求得的中心位置
for i=1:N
tmp{i}=[]; % 公式一中的x(i)-uj,为公式一实现做准备
for j=1:m
tmp{i}=[tmp{i};data(j,:)-u(i,:)];
end
end
quan=zeros(m,N);
for i=1:m %公式一的实现
c=[];
for j=1:N
c=[c norm(tmp{j}(i,:))];
end
[junk index]=min(c);
quan(i,index)=norm(tmp{index}(i,:));
end
for i=1:N %公式二的实现
for j=1:n
u(i,j)=sum(quan(:,i).*data(:,j))/sum(quan(:,i));
end
end
if norm(pre_u-u)<<span style="color:rgb(128,0,128);font-family:'Courier New' !important;">0.1 %不断迭代直到位置不再变化
break;
end
end
re=[];
for i=1:m
tmp=[];
for j=1:N
tmp=[tmp norm(data(i,:)-u(j,:))];
end
[junk index]=min(tmp);
re=[re;data(i,:) index];
end
end
运行结果:

