FreeBSD虚拟内存系统的启动
摘要
本报告介绍FreeBSD虚拟内存子系统的启动过程。FreeBSD虚拟内存子系统是许多其他子系统的基础,譬如文件子系统、设备子系统、进程子系统等等,而且它与系统设备、体系结构密切相关,特别是从实模式到保护模式下的映射,需要完成大量的工作。因此吸引我对从BootLoader到系统引导,再到虚拟内存子系统的启动这些内容的研究,主要参看了一下资料:
Ø Marshall等著《The Design and Implementation of the FreeBSD Operating System》
Ø FreeBSD文档项目《FreeBSD Architecture Handbook》第一章
Ø Thinker的网文《FreeBSD 4.0 Kernel Hacking Guide》
Ø Xuyifeng的网文《FreeBSD 内核中的SYSINIT分析》
Ø Jjww From FreeBSDChina《FreeBSD VM 内核内存管理》第一部分
Ø AT&T汇编指令参考
Intel x86的内存保护机制
要了解现代操作系统的虚拟内存系统,就需要明白Intel x86系统的“实模式”与“保护模式”的概念,由于我本身不是学体系出身,因此理解上可能有所差误。
Intel x86体系结构中有一个非常重要的元件——内存管理单元(Memory Management Unit,简称MMU),它是操作系统内核实现保护机制的关键,所有CPU对物理地址的访问都需要经过它的裁决。
Intel x86体系中的MMU设置了两种地址访问方式:
ü 实模式:直接使用内存单元的物理地址,作为访问内存信息的依据,CPU在总线上输出的地址为内存单元的实际物理地址;
ü 保护模式:MMU根据寄存器中的指定的页表目录项、页表项以及页内偏移地址作为访问内存信息的依据,这就是我们通常所说的两级映射方式,CPU在总线上输出的地址为“保护地址”也就是“虚拟地址”,根据页面地址的计算,得出实际映射的物理地址。

图1.MMU两级映射模式
上图就是MMU的两级映射模式,CPU提供完整的32位地址。当MMU接受到访问请求时,首先从寄存器()中获得页目录表基址,完整32位地址的前10位表示地址所在页表目录项在页表目录表内偏移地址,从而获得相应的页表页基址;完整32位地址中间的10位表示地址所在页面在页表中的偏移地址,从而获得相应的页面基址;最后12位作为页内偏移,与先前获得的页面基址进行操作,得到实际的物理内存地址。通过这样的两级目录得到真实的地址。
Intel x86体系结构中内存管理的基本常数:
l 页面大小:4K(12bit)——保护模式下,Intel x86将所有可以访问的物理地址划分为相同4K大小的块;
l 页目录项:4字节(32bit)——一个页目录项使用四个字节表示一个页表所在页面的基址,并且包括保护信息(由于页面是4K字节对齐的,所以每个页目录项至少有12个bit可以用于提供其他保护信息,譬如环、读写保护等);
l 页表项:4字节(32bit)——一个页表项使用四个字节表示一个页面所在的基址,并且包括保护信息(与页目录项基本相同);
l 页目录项/页:1K;
l 页表项/页:1K;
l 内核页目录表所占页面:1个;
l 内核页表所占页面:最初只有30个,可以扩充;
启动过程
在启动过程中,最初操作系统工作在实模式下,此时访问的地址使用直接物理地址。操作系统在完成基本的启动设定之后,按照格式填写页目录表与页表,并将内核各个段的地址映射到对应的表项。由于内核在设定表项的时候同时填写了保护位,因此在启用分页机制,也就是保护模式后,每接受一个地址访问请求都回判断是否符合保护条件,若不符合,则禁止其访问。总的来说,操作系统正是应用了MMU的这个功能实现了对自身的保护,并可以提供一系列的保护机制。
BootLoader过程
系统的bootloader工具有好几个,譬如:GRUB、LILO等,基本原理相同,都是显示必要信息,找到可以启动设备,读入启动扇区。这里研究的对象是FreeBSD自带的bootloader,程序代码在sys/boot/boot0/boot0.S。下图是对程序的关键部分的简单分析,通过该图的展示,你能知道一个bootloader的基本流程:
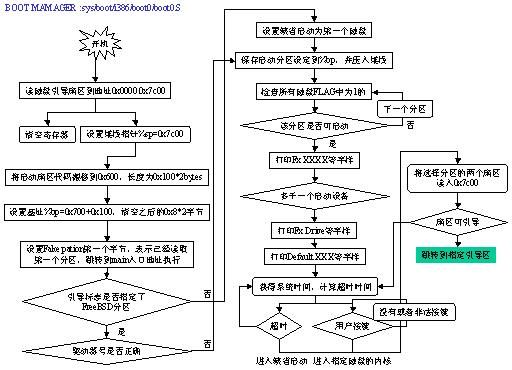
其中我们看到最主要的部分就是两次代码的搬移,因为实模式下使用直接物理地址,所以关于地址的操作必须非常小心,首先BIOS将bootloader代码复制到0:0x7c00,bootloader将自己搬移到0:0x0600,用户选择后将选定设备的引导扇区重新搬移到0:0x7c00。下图是两次搬移过程的图解:
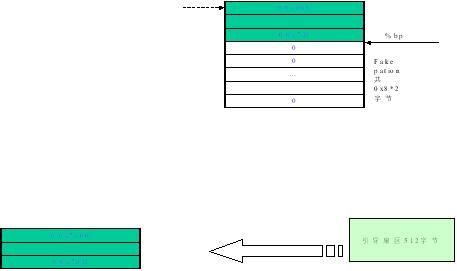
图3.bootloader两次搬移过程
其中涉及的汇编代码请参阅AT&T的汇编指令表以及Intel的寄存器参考
系统引导程序的工作
这里就是内核的开始,可以类比于C程序的main入口,不同的是这里的入口名称是btext,而不是main,文件位置:sys/i386/i386/locore.S,也是采用汇编语言编写。它主要负责系统硬件的识别与设置,其中包括创建内核页表,然后启动各个子系统,此后不再返回退出,系统资源由它独占,此后的子系统、进程等等都是属于它的一小部分。下图是对这段代码的关键点分析,由此可看出系统启动的流程:

图4.locore.S完成的工作
这里与虚拟内存子系统相关的部分包括create_pagetables()函数与init386()函数:
² create_pagetables函数在sys/i386/i386/locore.S,使用汇编码编写,主要的工作是找到内核位置与内核长度,划分空间,并创建内核页目录表与内核页表,接着将已经使用的物理地址和将要使用的空间进行页表映射,设置合适的保护位,下面两张图片就是其主要工作流程,以及create_pagetables之后的内存布局:
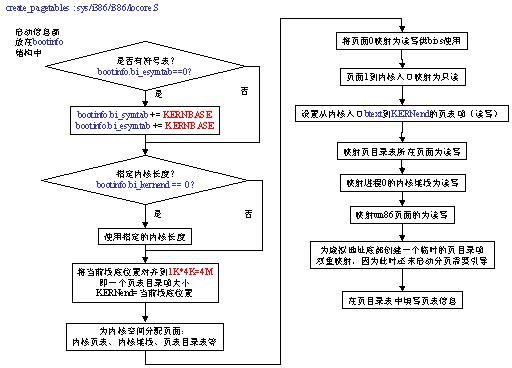
图5.create_pagetables的工作

图6.create_pagetables之后的内存布局
从这里可以看出通常所说的内核空间位置大于3G是如何得来的了,关于为何要将内核代码对齐到4Mbyte,目前没有看到相关资料,估计应该是在页面映射中,内核部分不能与应用程序部分共享一个页目录项,因此必须与4M(1pde=1K * 4K=4M)对齐。
之后还需要分配内核页表、页目录表、内核堆栈等等,其中页目录表占用一个页面,内核页表占用30页(30 * 1K * 4K = 120M),数量上似乎不正确,估计保留的4M空间可以用于扩展页表数组大小,从而支持大容量的内存。
在完成这些设置的同时,还需要设置对应的保护位,并且将计算得出的偏移量位置保存到全局变量KERNend、KPTphys、IdlePTD、proc0stack、physfree等等。
² init386函数在sys/i386/i386/machdep.c,它在操作系统启动中占有非常重要的地位,它要完成大部分硬件设置、启动工作,下图是它的工作过程:
图7.init386函数分析
由于init386的调用在locore.S中位于启用分页机制之后(参看图4),所以此时它需要再如全局描述符表、内核局部描述符表、中断向量表,并设置启动参数,它已经运行在保护模式之下。
这边有一个调用函数需要特别说明:getmemsize,它通过调用pmap_bootstrap()初始化pmap,然后计算可用的内存,并且设置一些全局变量,譬如可用内存数、内核结束地址,用于后面计算,不过这个函数还没有仔细看。
虚拟内存子系统的启动
在图4中我们看到在调用了init386()之后,紧接着就是调用mi_startup()函数,这里才是复杂的操作系统启动的执行部分。它在sys/kern/init_main.c中,不过参看它的代码就是两个循环,似乎不可思议,所以这里要首先介绍一下SYSINIT原理,然后才是虚拟内存子系统的启动部分:
SYSINIT宏与mi_startup()
在内核源文件中经常会看到使用SYSINIT宏,它的定义在sys/sys/kern.h,通过宏的扩展功能,它实际上是申明一个静态启动结构struct sysinitxxxx_sys_init,下图是该宏展开的过程,借用了虚拟内存子系统的SYSINIT声明,我们可以看到它定义了一个结构sysinit_vm_mem_sys_init,并且利用汇编将其加入sysinit_set数组(Note:最后的函数汇编指令的含义是:内核链接时建立一个section:.set.sysinit_set,并将vm_mem_sys_init的结构指针赋给它若前面有相同的名称的section定义,则附加到其后成为一个数组sysinit_set
)
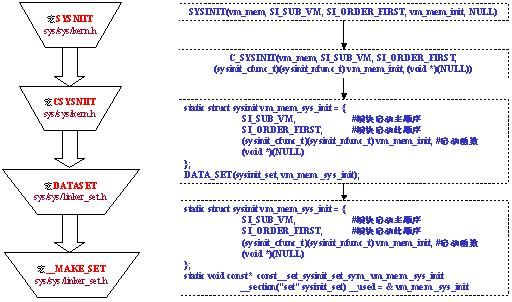
图8.SYSINIT宏展开过程
正是由于使用了sysinit_set这个数组,mi_startup才不需要那么辛苦地一个个子系统启动,在SYSINIT宏中,第二个参数指定了是第几个启动的子系统,第三个参数指定了在子系统中是第几个启动的部分,而第三个参数则是启动函数入口地址,最终它们将反映到sysinit_set数组中的单元结构中。
完成了这些设定之后mi_startup的工作就非常简单,首先对数组sysinit_set按照模块启动主顺序与启动次顺序进行排序,然后按照顺序依次启动子系统,最后检查是否使用kld新载入模块,是则重新开始。启动顺序的定义sys/sys/kern.h,我们可以看到除去第一个SI_SUB_DUMMY没用,与SI_SUB_DONE表示启动完毕,SI_SUB_TUNABLES、SI_SUB_CONSOLE没有找到对应的子系统,应该在之前已经完成,因为init386()函数设定了tunable与启动了控制台,SI_SUB_COPYRIGHT显示版本等信息,SI_SUB_SETTINGS检查设置,SI_SUB_MTX_POOL_STATIC初始化mutext池,SI_SUB_LOCKMGR则启动锁管理器,接下来就是我们的虚拟内存子系统了SI_SUB_VM,因此它在许多其他子系统启动之前完成。

图9.mi_startup()函数流程图
虚拟内存子系统的启动
以上完成了虚拟内存与硬件相关的部分,此处完成虚拟内存子系统与硬件基本无关的部分。主要文件都在sys/vm/目录下,以vm_init.c中的vm_mem_init()函数为入口,通过前面所述的SYSINIT机制完成。
vm_mem_init()函数定义在sys/vm/vm_init.c中,它的形式非常简单,一次调用以下函数,图10给出,它们依次完成图示的任务:
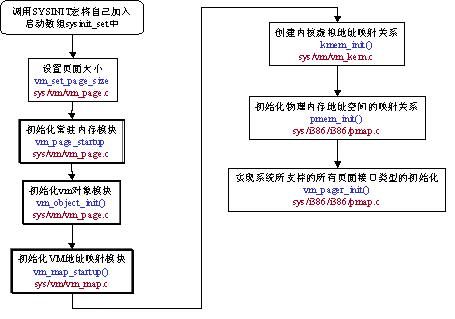
图10.vm_mem_init调用的函数
下面我们主要讲述几个重点函数,首先是vm_page_startup,下图是它的图示:

图11.vm_page_startup()操作分析
在介绍init386()时我们说过,它调用了getmemsize()函数计算了内存的基本参数,并保存到一些全局变量,譬如phys_avail数组、virtual_avail等,vm_page_startup正是使用这些参数初始化内存模块,包括初始化页面队列锁,创建free、active、inactive页面队列,并初始化,启动zone分配器(即linux中提到的slab机制),然后将剩余空间划分为页面,创建到页目录表、页表中,最后将所有可用的页面加入free页面队列。
从上面的计算可以看出实际创建页表时,包含的空间并没有包括内核已经使用部分、zone分配器使用部分,以及保存内存页表vm_page_array使用部分,到底怎么回事呢?其实MMU使用的4字节结构需要使用大量的位操作,对于表示和使用虚拟页面信息是不够的,而且不方便,因此实际上操作系统使用的是struct vm_page结构,并将它们组成一个链表,这种设计方法在FreeBSD底层比较普遍。
因此在这里我将操作系统使用的页表信息、页目录信息构成的虚拟内存称为“软虚拟内存”,而将MMU实际使用的页表信息与页目录信息称为“硬虚拟内存”,二者通过pmap_kenter映射:
n 硬虚拟内存的页表当然包含了系统所有的实际物理内存虚拟映射,应该说系统可寻址物理空间有多少个页面,对应的页表内容就有多少。
n 而软虚拟内存则映射了所有系统可用的物理内存空间,并且使用三个队列进行管理,由于内核以及内核分配的内存空间并不被软虚拟内存所映射中,所以不会被换出,这也是wire、nonpageable页面不被换出的原理。应当说硬虚拟内存映射的范围比软虚拟内存映射的范围要大。

图12.vm_object_init过程
上图是vm_object的初始化函数vm_object_init(),在sys/vm/vm_object.c中定义,在虚拟内存子系统中,vm_object扮演了非常重要的角色,它指出了页面数据的来源,其中为内核创建了两个vm对象,分别为:内核对象——管理内核部分的映射,内核内存对象——管理内核分配的内存。此处的vm对象管理的应该是内核pageable页面。
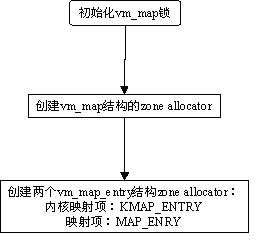
图13.vm_map初始化
接着vm_map初始化将创建vm_map的zone allocator,并且创建两个vm_map_entry的zone allocator,分别供内核与应用进程映射使用。最后调用kmem_init()、pmap_init()、vm_pager_init(),完成初始化虚拟内存子系统的任务,这里不再赘述。
总结
报告分析了FreeBSD虚拟内存子系统的启动过程。