4-1、Spark简介
1、Spark简介
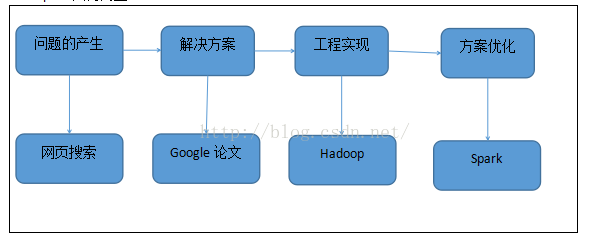
1.1、Spark为何物?
Spark是基于内存计算的大数据并行计算框架。
Spark基于内存计算,提高了大数据环境下处理的实时性,同时保证了高容错性和高伸缩性。
Spark于2009年诞生于加州大学伯克利分校AMPLab。现在已经成为Apache软件基金会旗下的顶级开源项目。
Spark历史与发展:
2009年:Spark诞生于AMPLab;
2010年:开源;
2013年6月:Apache孵化器项目:
2014年2月:Apache顶级项目;
2014年2月:大数据公司Cloudera宣城加大Spark框架的投入来取代MapReduce;
2014年4月:大数据公司MapR投入Spark阵营,Apache Mahout放弃MapReduce,将使用Spark作为计算引擎;
2014年5月:Pivotal Hadoop集成Spark全栈;
2014年5月30日:Spark1.0.0发布;
2014年6月:Spark 2014峰会在旧金山召开;
2014年7月:Hive on Spark项目启动;
2015年:Spark成为了现在大数据领域最火的开源软件;
2016年:Spark2.0将发布;
one stack to rule them all

Spark因何而生:
1.2、Spark和Hadoop关系
Spark用Scala语言编写,Hadoop用Java语言编写。
Spark是一个计算框架,而Hadoop中包含计算框架MapReduce和分布式文件系统HDFS,Hadoop更广泛地说还包含在其生态系统上的其他系统,如HBase、Hive等。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive等分布式存储层,可融入Hadoop的生态系统,以弥补MapReduce的不足。
Spark相比Hadoop MapReduce的优势:
1)、中间结果输出
基于MapReduce的计算引擎通常会把中间结果输出到磁盘上,进行存储和容错。当一些查询翻译到MapReduce任务时,处于任务管道承接考虑,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统来存储每一个Stage的输出结果。
Spark将执行模型抽象为通用的有向无环图(DAG),这可以将多Stage的任务串联或者并行执行,而无须将Stage中间结果输出到HDFS上面。类似的引擎包括Dryad、Tez。
2)、数据格式和内存布局
MapReduce Schema on Read处理方式会引起较大的处理开销。
Spark抽象出分布式内存存储结构弹性分布式数据集RDD,进行数据的存储。
RDD支持粗粒度写操作,但对于读取操作,RDD可以精确到每条记录。
3)、执行策略
MapReduce在数据Shuffle之前花费大量时间来排序。
Spark任务在Shuffle中不是所有的情景都需要排序,所以支持基于Hasnde的分布式聚合,调度中采用更为通用的任务执行计划图(DAG),每一次轮次的输出结果在内存缓存。
4)、任务调度和开销
Hadoop MapReduce是为了运行长达数小时的批量作业而设计的,在某些极端的情况下,提交一个任务的延迟非常高。
Spark采用了事件驱动的类库AKKA来启动任务,通过线程池复用线程来避免进程或线程启动和切换开销。
简单的说:
与MapReduce提供的编程模型相比,Spark具有如下鲜明的两点:
1)、计算更为快捷,速度可以提高10到100倍;
2)、计算过程中,如果某一点出现问题,事件重演的代价远远小于MapReduce。
从Spark的应用理论上来讲,原先基于MapReduce来开发的分析工具都可以基于Spark来实现,通过这样一种迁移来达到更快的处理效果。
Spark和Hadoop的几重关系:
1)、Spark和Hadoop的MapReduce处于同一层面。
2)、Spark可以部署在YARN上。
3)、Spark原生支持HDFS文件系统的访问。
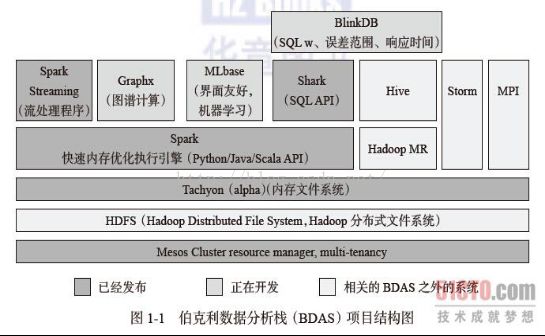
1.3、Spark生态系统BDAS
Spark已经发展成为包含众多子项目的大数据计算平台。伯克利将Spark的整个生态系统称为伯克利数据分析栈(BDAS)。
核心框架是Spark。
支持结构化数据SQL查询和分析的查询引擎Spark SQL;
提供机器学习功能的系统MLbase及底层的分布式机器学习库MLlib;
并行图计算框架GraphX;
流计算框架Spark Streaming;
采样近似计算查询引擎BlinkDB;
内存分布式文件系统Tachyon;
资源管理框架Mesos;
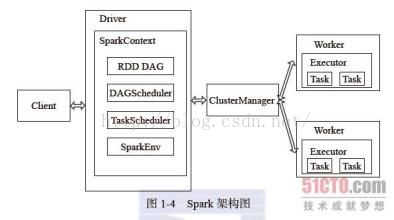
1.4、Spark架构
Spark架构采用了分布式计算中的Master-Slave模型。
Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。
Master作为整个集群的控制器,负责整个集群的正常运行;
Worker相当于计算节点,接收主节点命令和进行状态汇报;
Executor负责任务的执行;
Client作为用户的客户端负责提交应用;
Driver负责控制一个应用的执行;
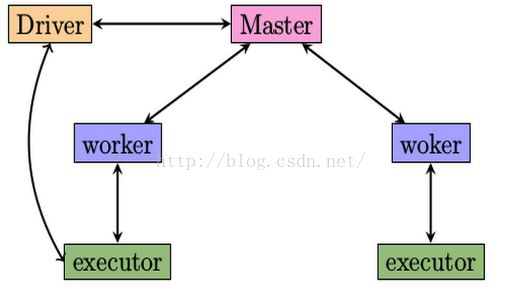
Driver和Worker是两个重要的角色。
Driver程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。
执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器,同时Executor对相应的数据分区的任务进行处理。
| Spark架构中的基本组件: ClusterManager:在Standalone模式中即为Master节点,控制整个集群,监控Worker。在YARN模式中为资源管理器。 Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。 Driver:运行Application的main()函数并创建SparkContext。 Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executors。 SparkContext:整个应用的上下文,控制应用的声明周期。 RDD:Spark基本的计算单元,一组RDD可形成执行的有向无环图RDD Graph。 DAGScheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。 TaskScheduler:将任务(Task)分发给Executor执行。 SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
在SparkEnv内创建如下一些重要的引用: MapOutPutTracker:负责Shuffle元信息的存储。 BroadcastManager:负责广播变量的控制与元信息的存储。 BlockManager:负责存储管理、创建和查询块。 MetricsSystem:监控运行时的性能指标信息。 SparkConf:负责存储配置信息。
|
Spark整体流程为:
Client提交应用,Master找到一个Worker启动Driver,Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph,再由DAGScheduler将RDD Graph转化为Stage的有向无环图提交给TaskScheduler,由TaskScheduler提交任务给Executor执行。任务提交的过程中,其它组件协同工作,确保整个应用顺利执行。
Spark standalone架构:
1.5、Spark核心组件
Spark支持丰富的应用计算场景,这个通过在Spark Core上构建多个组件完成的。
1.5.1、Spark Streaming
Spark Streaming实现了实时流处理;
Spark Streaming基于Spark Core实现了可扩展、高吞吐和容错的实时数据流处理。
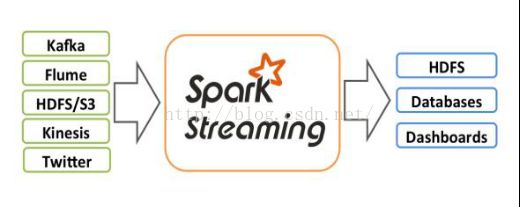
Spark Streaming是将流式计算分解成一系列短小的批处理作业。
这里的批处理引擎是Spark,也就是把Spark Streaming的输入数据按照尺寸(如1秒)分成一段一段的数据(Stream),每一段数据都转换为Spark中的RDD,然后将Spark Streaming中对DStream的转换变为针对Spark中对RDD的转换操作。将RDD经过操作变成中间结果保存在内存中。
1.5.2、MLlib
MLlib是Spark对常用的机器学习算法的实现库,同时含有相关的测试和数据生成器,包括分类、回归、聚类、降维、协同过滤以及底层基本的优化元素。
MLlib实现了很多机器学习算法:
分类与回归的算法包括SVM、逻辑回归、线性回归、朴素贝叶斯、决策树等;
协同过滤实现了交替最小二乘法(ALS);
聚类实现了K-means、高斯混合、PIC、LDA和Streaming版本的K-means;
降维实现了SVD和PCA;
还有频繁模式挖掘的FP-growth;
1.5.3、Spark SQL
Spark SQL实现了基于Spark的交互式查询;

数据源API通过Spark SQL提供了访问结构化数据的可插拔机制。数据源有了简便的途径进行数据转换并加入到Spark平台中。
数据源API的另一个优点就是不管数据的来源如何,用户都能通过Spark支持的所有语言来操作这些数据。
1.5.4、GraphX
GraphX实现了图计算,是Spark提供的关于图和图并行计算的API,它集ETL、试探性分析和迭代式的图计算与一体,在灵活性、易用性和容错性的前提下获得了很好的性能。
图算法是很多复杂机器学习算法的基础,GraphX的特点是离线计算、批量处理、基于同步的整体同步并行计算模型(BSP)。
http://www.cnblogs.com/Leo_wl/p/3530464.html
1.6、Spark版本

1.7、Spark整体代码结构规格
Spark Core是Spark的核心,它体现了Spark的核心设计思想。
Spark SQL、MLlib、GraphX和Spark Streaming都是基于Spark Core的实现和衍生。
在Spark1.2.0版本中,Spark Core包含了近6.5万行的Scala代码。
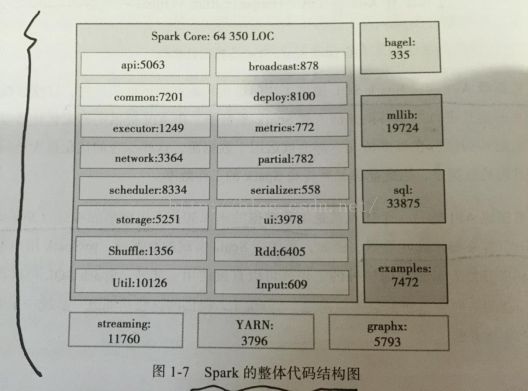
| scheduler:文件夹中含有负责整体的Spark应用、任务调度的代码; broadcast:含有Broadcast(广播变量)的实现代码,API是Java和Python实现的; deploy:含有Spark部署与启动运行的代码; Common:不是一个文件夹,而是代表Spark通用的类和逻辑的实现; Partial:含有近似评估代码; Network:含有集群通信模块代码; Storage:含有存储模块代码; 下面是Spark生态系统其它组件的实现: Streaming:是Spark Streaming的实现代码; Mllib:代表MLlib算法实现的代码; |
1.8、Spark on YARN
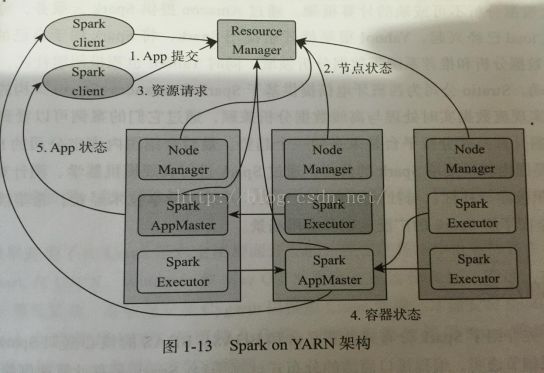
Spark on YARN架构解析如下:
基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager,ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager,NodeManager启动SparkAppMaster,SparkAppMaster启动后初始化作业,然后向ResourceManager申请资源,申请到相应资源后,SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor,SparkExecutor向SparkAppMaster汇报并完成相应的任务。此外,SparkClient会通过AppMaster获取作业运行状态。