【hadoop】Hadoop学习笔记(一)之示例程序:计算每年的最高温度MaxTemperature
本《hadoop学习笔记》系列是在《hadoop: the definitive guide 3th》的基础上通过网上额外搜集资料和查看hadoop的API再加上自己的实践方面的理解编写而成的,主要针对hadoop的特性和功能学习以及Hadoop生态圈中的其他工具(如Pig,Hive,Hbase,Avro等等)。另外设计到hadoop编程方面的请查阅另一个笔记系列:《Hadoop编程笔记》。如果有同学同时也在研究这本书,欢迎沟通交流,在下能力有限,还望各路大神看到有不对的地方加以指正~~(本系列学习笔记还正在整理中,以后会陆续发布)。
本书第二章以一个很浅显的例子为大家提供了hadoop入门,那就是从气象站中保存的历史气象信息里面提取出每年的最高气温来。其大致过程如下(注意在不同阶段的数据形式):
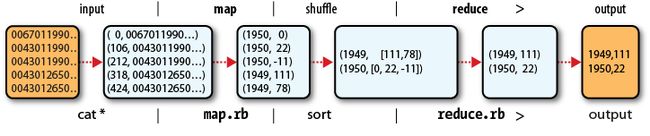
注意:shuffle阶段是把map的输出传输到reduce任务的阶段,其中包括了键值对的排序和分组。
1.Map阶段
Map任务是十分简单的,我们只需要从输入文件中提取出年份和对应的温度值即可,同时过滤掉坏的记录。这里我们选择Text输入格式(默认的),其中数据集的每一行作为map任务输入中的key-value pair中的value值,key值是对应行在输入文件中的位移(以字节为单位),但我们并不需要key的值,所以忽略之。下面我们来看一下map任务的java表示:
1 import java.io.IOException; 2 import org.apache.hadoop.io.IntWritable; 3 import org.apache.hadoop.io.LongWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Mapper; 6 7 public class MaxTemperatureMapper 8 extends Mapper<LongWritable, Text, Text, IntWritable> { //注1 9 private static final int MISSING = 9999; 10 @Override 11 public void map(LongWritable key, Text value, Context context) 12 throws IOException, InterruptedException { 13 String line = value.toString(); 14 String year = line.substring(15, 19); 15 int airTemperature; 16 if (line.charAt(87) == '+') { // parseInt doesn't like leading plus signs 17 airTemperature = Integer.parseInt(line.substring(88, 92)); 18 } else { 19 airTemperature = Integer.parseInt(line.substring(87, 92)); 20 } 21 String quality = line.substring(92, 93); 22 if (airTemperature != MISSING && quality.matches("[01459]")) { 23 context.write(new Text(year), new IntWritable(airTemperature)); 24 } 25 } 26 }
注1:Mapper类是一个泛型,其中的四个类型参数(LongWritable, Text, Text, IntWritable)指明了Mapper任务的输入(键,值)类型和输出(键,值)类型。其中LongWritable相当于java中的long类型,类似的,Text~String,IntWritable~int,只不过前者在网络传输时序列化操作方面做了优化。
2. Reduce阶段
同样的,Reducer类的四个类型参数也指明了Reducer任务的输入(键,值)类型和输出(键,值)类型。其输入类型必须和Mapper任务的输出类型匹配(在这个例子中为(Text,IntWritable))。
1 import java.io.IOException; 2 import org.apache.hadoop.io.IntWritable; 3 import org.apache.hadoop.io.Text; 4 import org.apache.hadoop.mapreduce.Reducer; 5 6 public class MaxTemperatureReducer 7 extends Reducer<Text, IntWritable, Text, IntWritable> { 8 @Override 9 public void reduce(Text key, Iterable<IntWritable> values, 10 Context context) 11 throws IOException, InterruptedException { 12 int maxValue = Integer.MIN_VALUE; 13 for (IntWritable value : values) { 14 maxValue = Math.max(maxValue, value.get()); 15 } 16 context.write(key, new IntWritable(maxValue)); 17 } 18 }
3. 下面我们总体查看一下作业的运行代码:
1 import org.apache.hadoop.fs.Path; 2 import org.apache.hadoop.io.IntWritable; 3 import org.apache.hadoop.io.Text; 4 import org.apache.hadoop.mapreduce.Job; 5 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 6 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 7 8 public class MaxTemperature { 9 public static void main(String[] args) throws Exception { 10 if (args.length != 2) { 11 System.err.println("Usage: MaxTemperature <input path> <output path>"); 12 System.exit(-1); 13 } 14 Job job = new Job(); 15 job.setJarByClass(MaxTemperature.class); 16 job.setJobName("Max temperature"); 17 18 FileInputFormat.addInputPath(job, new Path(args[0])); 19 FileOutputFormat.setOutputPath(job, new Path(args[1])); 20 21 job.setMapperClass(MaxTemperatureMapper.class); 22 job.setReducerClass(MaxTemperatureReducer.class); 23 24 job.setOutputKeyClass(Text.class); //注1 25 job.setOutputValueClass(IntWritable.class); 26 27 System.exit(job.waitForCompletion(true) ? 0 : 1); 28 } 29 }
注1:setOutputKeyClass()和setOutputValueClass()控制map任务和reduce任务的输出(两者输出类型相同的情况下),如果他们不一样,那么map的输出就要通过setMapOutputKeyClass()和setMapOutputValueClass()来设定了(reduce任务的输出设定之手前两者的影响)。
附1:map的输入格式由Job的静态方法 public void setInputFormatClass(Class<? extends InputFormat> cls)来设定,默认为TextInputFormat(在本例中并未显式给出)。
通过以下命令来运行我们的第一个hadoop程序:
% export HADOOP_CLASSPATH=hadoop-examples.jar //HADOOP_CLASSPATH的具体含义请参看这里
% hadoop MaxTemperature input/ncdc/sample.txt output
其中sample.txt是我们指定的本地输入文件,output是我们指定的输出文件所在目录,注意此目录在运行前不应该存在,否则程序会报错并停止运行,这样做的目的主要是为了防止被指定的目录如果是另一个已存在的包含大量珍贵数据的目录,那么此目录下的文件就会被覆盖掉从而造成数据损坏。
运行成功后就会在output目录下产生part-r-00000文件和_SUCCESS文件,前者对应于reduce任务的输出,每个reducer对应于一个这样的输出文件,以零(00000)开始计数(通过特殊的设置,reducer也可以产生多个输出文件,这个我们在后面再介绍);后者是一个内容为空的标志文件(marker),表示作业已经成功完成。
转载请注明出处:http://www.cnblogs.com/beanmoon/archive/2012/12/07/2804183.html