Case Analyzer 配置之(设计Filed)
项目中想设计几个与流程有关的报表,这些报表需要查找EventLog,EventLog里面记录中流程的流转信息,比如什么时间什么人发起什么流程,这个流程在发起以后,下一个节点的参与者什么完成,中间停留了多长时间等信息。所以EventLog的信息是非常大的,项目组决定采用IBM的CA(Case Analyzer)即PA(process Analyzer)。
下面是配置CA展现字段的过程:
PE server side:
0/ PE is enabled for case analyzer data capture、
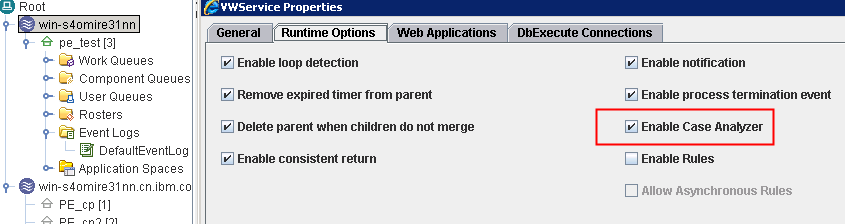
1/ expose fields in event log in PA and commit to the PE database

3/ launch the workflow many times to create event log record
You will find the values of exposed field in PA like this:

as you can see, the value changed from 1 to 4 during process running
CA server side:
0/ CA get connected to PE
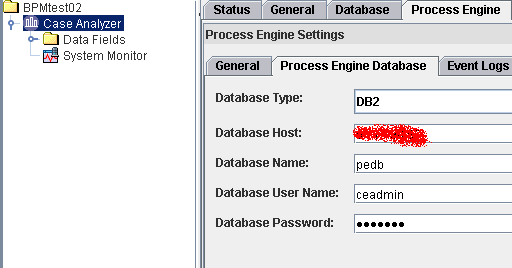
1/ get the CA service stopped
2/ add the fields which are related to the fields we added in PE event log
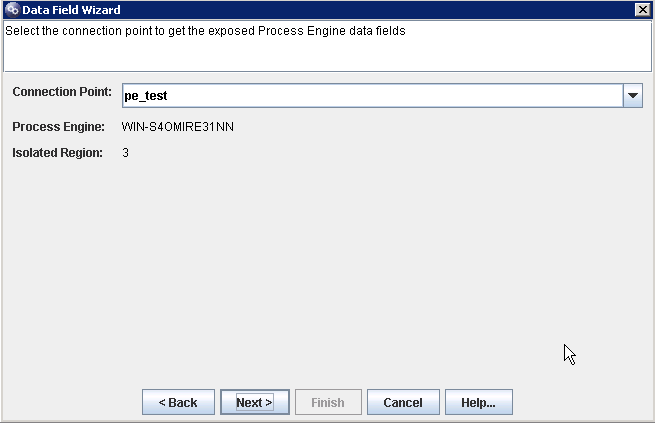
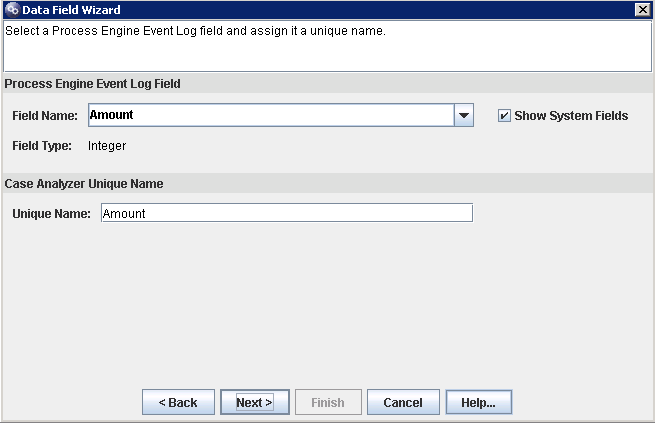

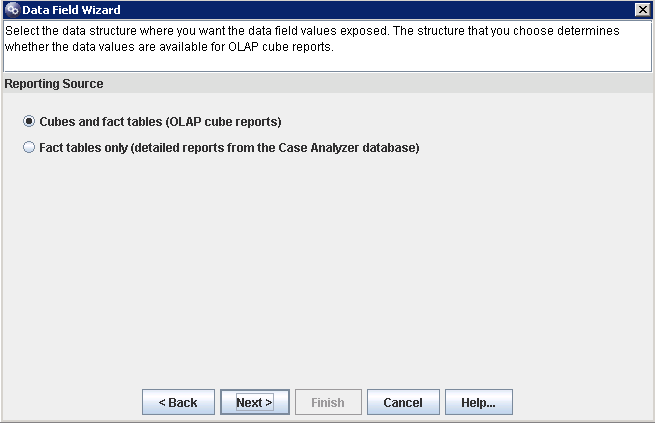

click finish the whole field adding process.
You can follow same problem for field location. Finally it looks like:
click finish the whole field adding process.
You can follow same problem for field location. Finally it looks like:

* field of integer type could be measurable or not.
3/ get CA started
4/ make sure CA get the data from PE and commited
5/ process the cube manually.
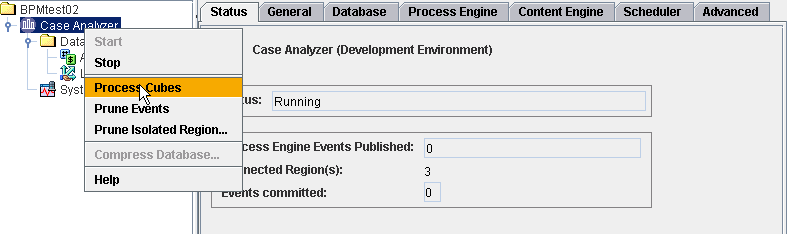
字段配置完成然后通过Process Cubes 就会生成一个Cubes ,需要用SQL Sserver来查看,具体内容在下一篇博客讲述。