采集baidu搜索信息的java源代码实现(使用了htmlunit和Jsoup)
最近大四做毕设,题目是关于语言自动处理的。其中的第一步,需要采集数据,最开始时候写了一个爬虫,但是效果不好,尝试了网上的一个主题爬虫,但是好像也就他给的那个主题搜素的比较全面,朋友说,你干嘛不把百度搜索的结果作为爬虫的数据来源,心想也是,本人懒,再者毕竟这个部分不是毕设的主要部分,便开始找代码看有没有直接能用的,显然没有。于是一步步总结了一套方法,尝试了用java做了关于爬百度搜索结果的程序。
1.需要下载Htmlunit和Jsoup的jar包
(最开始只尝试使用其中之一,无果,尝试两个合起来,效率不太高,但是搜索结果出来了,如果有什么改进空间,大家可以提议。方法也都没有封装,不过我注释写得比较详细,如果有问题,可以留言)
htmlunit是公认的比较好的无GUI的浏览器,模拟执行浏览器的操作,Jsoup的相关jar包也是比较好的关于爬虫的集成的包。
下载链接:CSDN地址
Jsoup:http://download.csdn.net/detail/zhaohang_1/8586799
htmlunit:http://download.csdn.net/detail/zhaohang_1/8586849
2.建立项目
建立两个java文件。
第一部分,HtmlUnitforBD.java:主要实现摘取百度搜索的URL链接;
第二部分,transURLtoINFO.java:摘取链接的具体内容。
3.观察网页内容
观察网页源码:
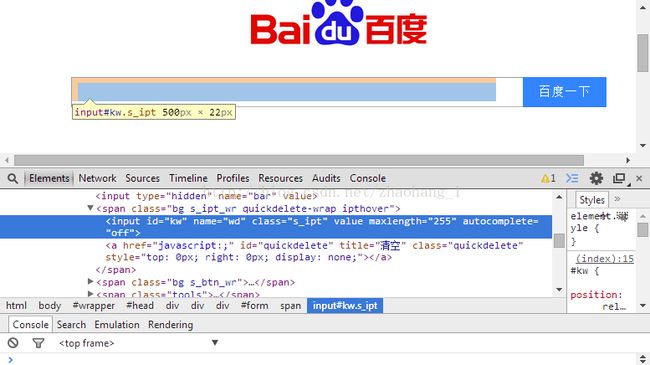
3.1百度输入框参数:id=kw
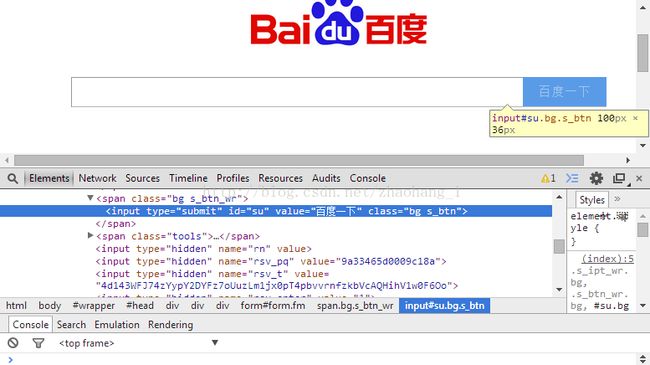
3.2“百度一下”的按钮参数:id=su
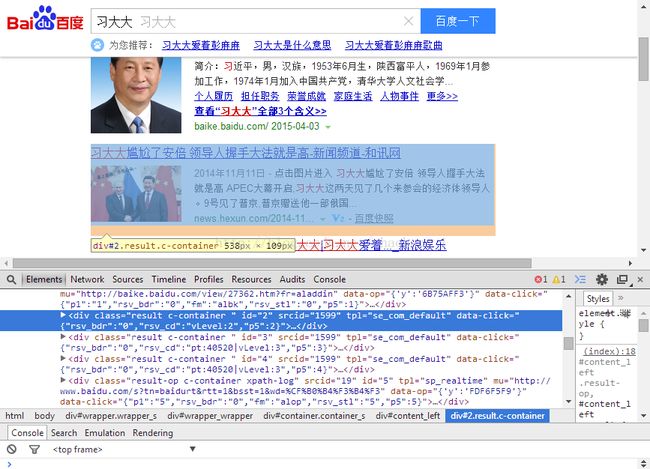
3.3执行搜索“习大大”之后的网页源码,可以发现搜索的结果里面几乎都包含带有data-click属性的<div>标签,就是要把他们全提取出来,另外某些结果的属性是“mu”的,因为含这个属性的<div>标签比较少,本人没有做,有兴趣的可以试着改改。
3.4看其他页的代码,找规律获取所有页的地址
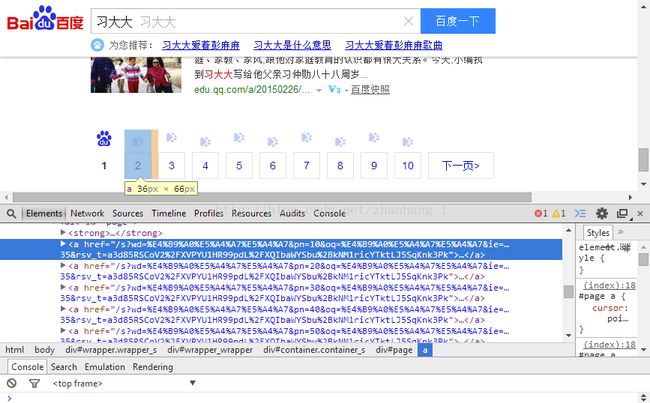
规律就是如图: ,pn=1(第二页),pn=2(第三页)...,并且其他的部分是相同的,也就是是说,直接替换掉数字就可以定位到该页。
,pn=1(第二页),pn=2(第三页)...,并且其他的部分是相同的,也就是是说,直接替换掉数字就可以定位到该页。
4.好,来代码!
(第一部分中有两处try catch中注释掉的代码,可以取消注释,这样能够查看从网页获取的文本内容。程序执行过程中存在找不到网页返回504等错误,很少碰见,如果出现,可以稍等一下,程序给出反馈后继续执行。
)
第一部分(获取链接的部分):
package bdsearch;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlInput;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
///////////////关于htmlunit的相关资料,在此站上有些资料,参考了一下:http://www.cnblogs.com/cation/p/3933408.html
public class HtmlUnitforBD {
private static int N = 3;// 搜索页数
private static String keyW = "习大大";// 搜索词
private static HtmlPage firstBaiduPage;// 保存第一页搜索结果
private static String format = "";// Baidu对应每个搜索结果的第一页第二页第三页等等其中包含“&pn=1”,“&pn=2”,“&pn=3”等等,提取该链接并处理可以获取到一个模板,用于定位某页搜索结果
private static ArrayList<String> eachurl = new ArrayList<String>();// 用于保存链接
public static void main(String[] args) throws Exception {
mainFunction(N, keyW);
}
public static void mainFunction(final int n, final String keyWord) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
int x = n;// 页数
System.out.println("要提取百度关于“" + keyWord + "”搜索结果的前" + x + "页");
/*
* 1.获取并输出第一页百度查询内容
*/
Elements firstPageURL = null;
try {
firstPageURL = getFirstPage(keyWord);
} catch (FailingHttpStatusCodeException | IOException e) {
e.printStackTrace();
}// 定义firstPageURL作为第一个搜索页的元素集
for (Element newlink : firstPageURL) {
String linkHref = newlink.attr("href");// 提取包含“href”的元素成分,JSoup实现内部具体过程
String linkText = newlink.text();// 声明变量用于保存每个链接的摘要
if (linkHref.length() > 14 & linkText.length() > 2) {// 去除某些无效链接
System.out.println(linkHref + "\n\t\t摘要:" + linkText);// 输出链接和摘要
eachurl.add(linkHref);// 作为存储手段存储在arrayList里面
// try {
// String temp = "";
// try {
// transURLtoINFO.trans(linkHref, temp);
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
// } catch (FailingHttpStatusCodeException e) {
// e.printStackTrace();
// }
}
}
/*
* 2.读取第二页及之后页面预处理
*/
nextHref(firstBaiduPage);// 以firstBaiduPage作为参数,定义format,即网页格式。
/*
* 3.获取百度第一页之后的搜索结果
*/
for (int i = 1; i < x; i++) {
System.out.println("\n************百度搜索“" + keyW + "”第" + (i + 1) + "页结果************");
String tempURL = format.replaceAll("&pn=1", "&pn=" + i + "");// 根据已知格式修改生成新的一页的链接
System.out.println("该页地址为:" + format.replaceAll("&pn=1", "&pn=" + i + ""));// 显示该搜索模板
HtmlUnitforBD h = new HtmlUnitforBD();
String htmls = h.getPageSource(tempURL, "utf-8");// 不知为何此处直接用JSoup的相关代码摘取网页内容会出现问题,所以采用新的编码来实现摘取网页源码
org.jsoup.nodes.Document doc = Jsoup.parse(htmls);// 网页信息转换为jsoup可识别的doc模式
Elements links = doc.select("a[data-click]");// 摘取该页搜索链接
for (Element newlink : links) {// 该处同上getFirstPage的相关实现
String linkHref = newlink.attr("href");
String linkText = newlink.text();
if (linkHref.length() > 14 & linkText.length() > 2) {// 删除某些无效链接,查查看可发现有些无效链接是不包含信息文本的
System.out.println(linkHref + "\n\t\t摘要:" + linkText);
eachurl.add(linkHref);// 作为存储手段存储在arrayList里面
// try {
// String temp = "";
// try {
// transURLtoINFO.trans(linkHref, temp);
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
// } catch (FailingHttpStatusCodeException e) {
// e.printStackTrace();
// }
}
}
}
System.out.println("\n\n\n输出所有地址");
for (String xx : eachurl) {
System.out.println(xx);
}
return;
}
});
thread.start();
}
/*
* 获取百度搜索第一页内容
*/
public static Elements getFirstPage(String w) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
// 创建Web Client
String word = w;
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(false);// HtmlUnit对JavaScript的支持不好,关闭之
webClient.getOptions().setCssEnabled(false);// HtmlUnit对CSS的支持不好,关闭之
HtmlPage page = (HtmlPage) webClient.getPage("http://www.baidu.com/");// 百度搜索首页页面
HtmlInput input = (HtmlInput) page.getHtmlElementById("kw");// 获取搜索输入框并提交搜索内容(查看源码获取元素名称)
input.setValueAttribute(word);// 将搜索词模拟填进百度输入框(元素ID如上)
HtmlInput btn = (HtmlInput) page.getHtmlElementById("su");// 获取搜索按钮并点击
firstBaiduPage = btn.click();// 模拟搜索按钮事件
String WebString = firstBaiduPage.asXml().toString();// 将获取到的百度搜索的第一页信息输出
org.jsoup.nodes.Document doc = Jsoup.parse(WebString);// 转换为Jsoup识别的doc格式
System.out.println("************百度搜索“" + word + "”第1页结果************");// 输出第一页结果
Elements links = doc.select("a[data-click]");// 返回包含类似<a......data-click=" "......>等的元素,详查JsoupAPI
return links;// 返回此类链接,即第一页的百度搜素链接
}
/*
* 获取下一页地址
*/
public static void nextHref(HtmlPage p) {
// 输入:HtmlPage格式变量,第一页的网页内容;
// 输出:format的模板
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
p = firstBaiduPage;
String morelinks = p.getElementById("page").asXml();// 获取到百度第一页搜索的底端的页码的html代码
org.jsoup.nodes.Document doc = Jsoup.parse(morelinks);// 转换为Jsoup识别的doc格式
Elements links = doc.select("a[href]");// 提取这个html中的包含<a href=""....>的部分
boolean getFormat = true;// 设置只取一次每页链接的模板格式
for (Element newlink : links) {
String linkHref = newlink.attr("href");// 将提取出来的<a>标签中的链接取出
if (getFormat) {
format = "http://www.baidu.com" + linkHref;// 补全模板格式
getFormat = false;
}
}
}
public String getPageSource(String pageUrl, String encoding) {
// 输入:url链接&编码格式
// 输出:该网页内容
StringBuffer sb = new StringBuffer();
try {
URL url = new URL(pageUrl);// 构建一URL对象
BufferedReader in = new BufferedReader(new InputStreamReader(url.openStream(), encoding));// 使用openStream得到一输入流并由此构造一个BufferedReader对象
String line;
while ((line = in.readLine()) != null) {
sb.append(line);
sb.append("\n");
}
in.close();
} catch (Exception ex) {
System.err.println(ex);
}
return sb.toString();
}
}
第二部分(提取可能有用的文本):
package bdsearch;
import java.io.BufferedReader;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.ConnectException;
import java.net.MalformedURLException;
import java.util.ArrayList;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class transURLtoINFO {
/*
* 匹配消除html元素
*/
// 定义script的正则表达式
private static final String regEx_script = "<script[^>]*?>[\\s\\S]*?<\\/script>";
// 定义style的正则表达式
private static final String regEx_style = "<style[^>]*?>[\\s\\S]*?<\\/style>";
// 定义HTML标签的正则表达式
private static final String regEx_html = "<[^>]+>";
// 定义空格回车换行符
private static final String regEx_space = "\\s*|\t|\r|\n";
public static void main(String[] args) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
String temp = null;
trans("http://www.baidu.com/", temp);
System.out.println("over");
}
public static String trans(String url, String info) throws FailingHttpStatusCodeException, MalformedURLException, IOException {
ArrayList<String> hrefList = new ArrayList<String>();
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.getOptions().setJavaScriptEnabled(false);
webClient.getOptions().setCssEnabled(false);
try {
HtmlPage page = null;
try {
page = (HtmlPage) webClient.getPage(url);
} catch (ConnectException e) {
}
InputStream temp = new ByteArrayInputStream(page.asText().getBytes());
InputStreamReader isr = new InputStreamReader(temp);
BufferedReader br = new BufferedReader(isr);
String str = null, rs = null;
while ((str = br.readLine()) != null) {
rs = str;
if (rs != null)
hrefList.add(rs);
}
System.out.println("从该网址" + url + "查找的可能相关文本如下:");
for (int i = 0; i < hrefList.size(); i++) {
String string = hrefList.get(i);
string = getTextFromHtml(string);
if (string.length() >= 50) {
info += "\n" + string;
System.out.println(string);
}
}
} catch (IOException e) {
}
return info;
}
/*
* 从一行开始清除标签
*
* @return
*/
public static String delHTMLTag(String htmlStr) {
Pattern p_space = Pattern.compile(regEx_space, Pattern.CASE_INSENSITIVE);
Matcher m_space = p_space.matcher(htmlStr);
htmlStr = m_space.replaceAll(""); // 过滤空格回车标签
Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
Matcher m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 过滤script标签
Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
Matcher m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); // 过滤style标签
Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
Matcher m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); // 过滤html标签
return htmlStr.trim(); // 返回文本字符串
}
public static String getTextFromHtml(String htmlStr) {
htmlStr = delHTMLTag(htmlStr);
htmlStr = htmlStr.replaceAll(" ", "");
return htmlStr;
}
}
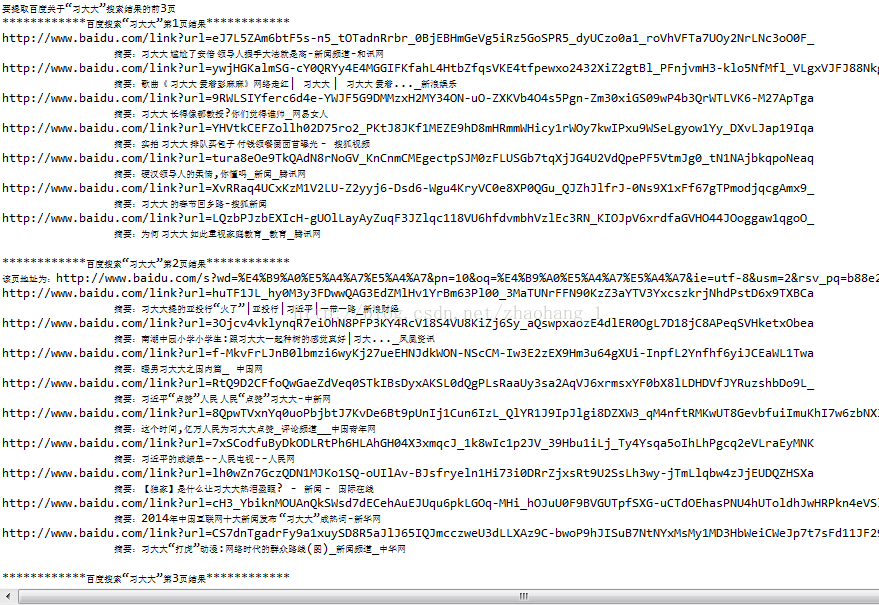
同时可以输出了所有链接,有需要的可以用此方法专门搜集链接:

如果取消注释输出的文本如下:
