hadoop完全分布式集群+Win Eclipse+Hbase+Hive+Zookeeper+Sqoop试验机平台
【申明】本文的编写是参考了数个Blog,并由本人亲身试验配置完成。为的是不忘却自己的配置过程,以便于及时恢复查看之用。最终会在配置完成之后提供虚拟机节点的百度云下载链接,供大家下载使用。
之前一直用的Hadoop伪分布式的平台进行试验。今天突发奇想,想配个更为真实的模拟环境——hadoop完全分布式集群,在VMware下用三个虚拟机实现模拟3个物理节点。
本人电脑64位,配置如下:

准备工作:
1、在本本上安装虚拟机为:VMware WorkStation8;
2、在虚拟机中安装一个Centos 6.5 X64位系统,作为master节点,并安装好Java,配置如下:

3、所以,在准备好这3个结点之后,需要分别将Centos系统的主机名重命名(因为前面是复制和粘帖操作产生另两上结点,此时这3个结点的主机名是一样的),重命名主机名的方法:
Vim /etc/hosts

以下是我对三个结点(还有两个没配呢)的centos系统主机分别命名为:master, node1, node2。
4、准备2个node节点:无须重点安装两个Centos虚拟机系统,只需将master节点(已经安装好JAVA环境,并修改了主机名了)文件Copy两份,在WorkStation中添加即可,命令为node1 与node2节点。
按照hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop程序中的namenode、secondorynamenode和jobtracker任务。用外两个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了,所以模拟hadoop集群至少要有3个结点,如果电脑配置非常高,可以考虑增加一些其它的结点。slave结点主要将运行hadoop程序中的datanode和tasktracker任务。
准备工作就绪,以下安装Hadoop完全分布式环境了:
一、 配置hosts文件
二、 建立hadoop运行帐号
三、 配置ssh免密码连入
四、 下载并解压hadoop安装包
五、 配置namenode,修改site文件
六、 配置hadoop-env.sh文件配置masters和slaves文件
七、 格式化namenode
八、 启动hadoop
九、 用jps检验各后台进程是否成功启动
十、 完全分布式Hbase的安装
十一、 完全分布式Hive的安装
十二、 在主机Win8下用MyEclipse连接VMware虚拟机Centos的Hadoop
十三、 总结及常见问题:
一、配置hosts文件:
这一步其实我们在准备工作中已经完成了,但复制节点之后,两个datanode节点的IP地址是随机分配的,所以仍需配置好IP地址。
sudo ifconfig eth1 192.168.1.125 //在node1上节点进行修改
sudo ifconfig eth1 192.168.1.126 //在node2上节点进行修改
此名,还需修改两个文件:
a.修改/etc/sysconfig/network文件,将包含当前的hostname改为新的hostname(这里三个都要修改的,分别对应着master,node1,node2)

b.在三台机子中 使用命令hosname更改一下,命令为:hostname 新的主机名,然后用hostname名称查看是否修改成功。
hostname master
hostname
![]()
二、建立Hadoop运行帐号
即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:
sudo groupadd hadoop //设置hadoop用户组
sudo useradd –s /bin/bash –d /home/lb –m lb –g hadoop –G admin //添加一个lb用户,此用户属于hadoop用户组,且具有admin权限。
sudo passwd lb //设置用户lb登录密码
su lb //切换到lb用户中
以上三个节点均须作同样的操作
三、配置ssh免密码登录
在Hadoop启动以后,Namenode是通过SSH(Secure Shell)来启动和停止各个datanode上的各种守护进程的,这就须要在节点之间执行指令的时候是不须要输入密码的形式,故我们须要配置SSH运用无密码公钥认证的形式。以本文中的三台机器为例,现在Master是主节点,他须要连接node1、node2。须要确定每台机器上都安装了ssh,并且datanode机器上sshd服务已经启动(一般centos6.5都已经自启动了,不需操作)。
在master节点上,切换到lb用户( 保证用户lb可以无需密码登录,因为我们后面安装的hadoop属主是lb用户。)
1) 在每台主机生成密钥对
这个命令生成一个密钥对:id_rsa(私钥文件)和id_rsa.pub(公钥文件)。默认被保存在~/.ssh/目录下。
2) 在另外两个datanode节点进行以上同操作。
3) 在master中将id_rsa.pub文件发放到node2: scp /home/lb/.ssh/id_rsa.pub lb@node2:~/.ssh/master.pub
在node1中将id_rsa.pub文件发放到node2: scp /home/lb/.ssh/id_rsa.pub lb@node2:~/.ssh/node1.pub
在node2中将id_rsa.pub文件复制一份: cp id_rsa.pub node2.pub
再复制master.pub,node1.pub,node2.pub三个文件的内容到一个文件,命名为authorized_keys,并将生成的文件Copy到另两个节点的.ssh目录下。
权限设置为600.(这点很重要,网没有设置600权限会导致登陆失败)
测试登陆: ssh node1,第一次会提示输入密码,exit之后,再退出的时候就不用再输入密码,此时ssh配置才算成功。
提示:本人在此步骤足足嗑磕碰碰了两个多小时就是第二次登录时还会提示输入密码,有以下几个原因:
a.authorized_keys文件并没有包括三个文件内容的合体;
b.目录或文件的权限没有设置好:
首先 .ssh目录权限是700, 两个dsa 和 rsa的 私钥权限是600,其余文件权限是644.
其次,.ssh目录的父目录文件权限应该是755,即所属用户的 用户文件目录,本虚拟机中应为/home/lb目录
c. 关闭防火墙(选择永久性关闭):
永久性生效,重启后不会复原
开启: chkconfig iptables on
关闭: chkconfig iptables off
即时生效,重启后复原
开启: service iptables start
关闭: service iptables stop
四、下载并解压Hadoop安装包
在master节点中先下载hadoop1.2.1安装包到目录,并解压之:
tar -zxvf hadoop-1.2.1.tar.gz

五、配置master(namenode)的文件

如上图所示修改master中的6个文件:
a.core-site.xml

b.hadoop-env.sh
c.hdfs-site.xml

d.mapred-site.xml

e.masters
f.slaves

六、配置slave(datanode)的文件
在master下将hadoop文件包分发下去(这三个节点一定要保持一致哦!):
scp -r /home/lb/hadoop-1.2.1 lb@node1:~/
scp -r /home/lb/hadoop-1.2.1 lb@node2:~/
1) 用jps检验各后台进程是否成功启动


Step1:先配置/home/lb/hbase-0.94.17/conf/hbase-site.xml
- [myhadoop@myhadoop1 ~]$ vim hbase-0.94.17/conf/hbase-site.xml
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://master:9000/hbase</value>
- <description>区域服务器使用存储HBase数据库数据的目录,服务器名称不能填IP,不然会报错</description>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- <description>指定HBase运行的模式: false: 单机模式或者为分布式模式 true: 全分布模式 </description>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>master,node1,node2</value>
- <description>ZooKeeper集群服务器的位置</description>
- </property>
- </configuration>
hbase-0.94.17/conf/regionservers
- [myhadoop@myhadoop1 ~]$ vim hbase-0.94.17/conf/regionservers
- master
- node1
- node2
step3: 配置HBase中Zeekeeper使用方式
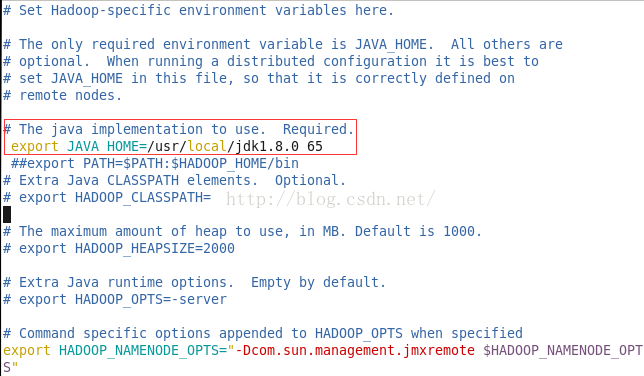
在hbase-0.94.17/conf/hbase-env.sh文件最尾部,打开注释 export HBASE_MANAGES_ZK=false,修改true为false。意思是使用外部的Zeekeeper。此外,还需要打开注释 export JAVA_HOME=/usr/local/jdk1.8.0_65
- [myhadoop@myhadoop1 ~]$ vim hbase-0.94.17/conf/hbase-env.sh
- export JAVA_HOME= /usr/local/jdk1.8.0_65
- export HBASE_MANAGES_ZK=false
(3)复制HBase目录到其他服务器
在myhadoop1上以myhadoop用户,使用以下命令进行复制:
scp -r hbase-0.94.17 lb@node1:~
scp -r hbase-0.94.17 lb@node2:~
(4)启动,验证
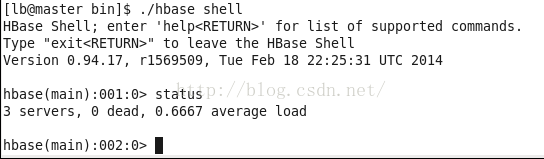
拷贝完成后在master的hbase目录的bin子目录下就可以输入:./start-hbase.sh启动HBase集群了;启动完成后,node1上使用jps命令可以看到多了一个HMaster服务,在子节点输入jps可以看到多了一个HRegionServer服务; 登录HBase可以使用hbase shell命令登录HBase,输入status查看当前状态。输入exit退出HBase服务。
- [myhadoop@myhadoop1 ~]$ start-hbase.sh
- starting master, logging to /home/myhadoop/hbase-0.94.17/logs/hbase-myhadoop-master-myhadoop1.out
- node1: starting regionserver, logging to /home/myhadoop/hbase-0.94.17/bin/../logs/hbase-myhadoop-regionserver-myhadoop2.out
- node2: starting regionserver, logging to /home/myhadoop/hbase-0.94.17/bin/../logs/hbase-myhadoop-regionserver-myhadoop3.out
- master: starting regionserver, logging to /home/myhadoop/hbase-0.94.17/bin/../logs/hbase-myhadoop-regionserver-myhadoop1.out
- [myhadoop@myhadoop1 ~]$ jps
- 4870 SecondaryNameNode
- 4625 NameNode
- 6013 HMaster
- 4746 DataNode
- 5102 TaskTracker
- 6377 Jps
- 5744 QuorumPeerMain
- 4971 JobTracker
- 6171 HRegionServer
-
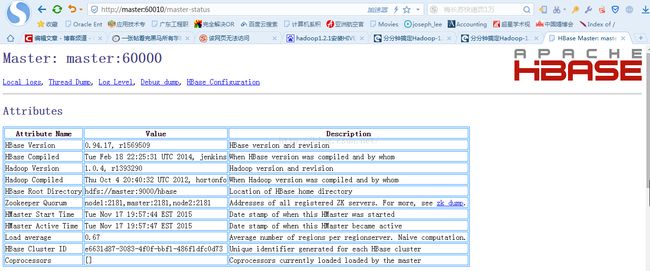
通过浏览器查看:在Win8主机的浏览器中输入 : http://master:60010/ 见下图所示
十一、Hive的安装
1、在安装MySQL后,创建用户hive,密码为libing,并创建新的Database名hive后,再从
网上下载hive-0.10.0,下载地址:http://archive.apache.org/dist/
2、vim ~/.bashrc,修改如下:

3、将下载的zip文件解压。
在hive主目录下找到conf文件夹下的hive_env.sh,将其中得HADOOP_HOME和HIVE_CONF_DIR并配置:

4、配置文件hive-site.xml
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.1.117:3306/hive</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>驱动名</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> <description>用户名</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>libing</value> <description>密码</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/home/hadoop/hive/warehouse</value> <description>数据路径(相对hdfs)</description> </property> <property> <name>hive.metastore.uris</name> <value>thrift://192.168.1.117:9083</value> <description>运行hive得主机地址及端口</description> </property> </configuration>在本机中的配置如下:


为了使MySQL与Hive能连接起来,还需要在MySQL下做如下操作:
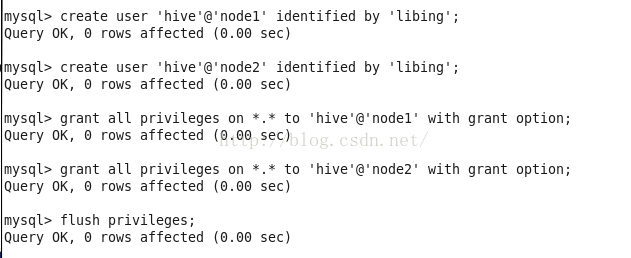
mysql -u root -p libing;
create user 'hive'@'master' identified by 'libing';
grant all privileges on *.* to 'hive'@'master' with grant option;
为了使node1与node2(即集群中所有节点都有权限操作mySQL数据库,为以后安装Sqoop工具做基础)必须做如下操作:
至此,hive完成安装!在MySQL下查看元数据:


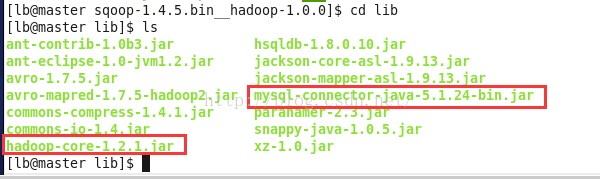
3.copy需要的lib包到Sqoop/lib
cp ~/hadoop/hadoop-core-1.0.4.jar ~/sqoop/lib/
cp mysql-connector-java-5.1.18.jar ~/sqoop/lib/
4.添加环境变量
export SQOOP_HOME=/home/hadoop/sqoop-1.4.5.bin__hadoop-1.0.0
export PATH=$SQOOP_HOME/bin:$PATH
export LOGDIR=$SQOOP_HOME/logs

5.测试验证
--列出mysql数据库中的所有数据库


注:为了使数据能从HDFS中顺利到HIVE数据库中,Sqoop也提供了以下操作顺序:
a.将数据从MySQL中导入到HDFS;
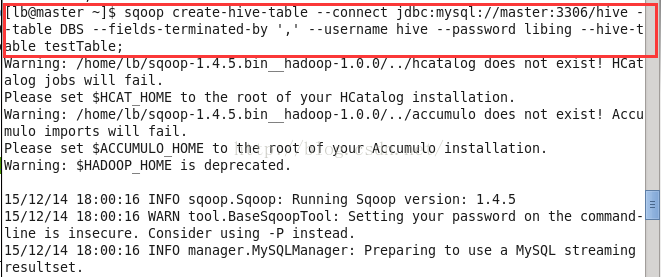
b.使用Sqoop创建表
例如上例中数据:
sqoop create-hive-table --connect jdbc:mysql://master:3306/hive --table DBS --fields-terminated-by ',' --username hive --passoword libing --hive-table testTable
创建一个testTable的HIVE表,跟MySQL中的DBS是一样的格式。
c.将数据从HDFS加载到HIVE表中
当然以上三个步骤可以凑成一个:
(导出MySQL的表结构到HIVE) sqoop create-hive-table --connect jdbc:mysql://master:3306/hive --table DBS --username hive --password libing --hive-table test2
(导出MySQL表数据到HIVE)sqoop import --connect jdbc:mysql://master:3306/hive --table DBS --username hive --password libing --hive-table test2 --hive-import

如此生成了test2表,与MySQL中的DBS表是一样的结构:

---导出数据:将HDFS中的某张表导出到MySQL中
1、要先在MySQL中建立一张表 test_received;
2、sqoop export --connect jdbc:mysql://master:3306/hive --table test_received --export-dir /user/hive/warehouse/test2 --username hive --password libing -m 1 --fields-terminated-by '\t' (将test2表从hive中导出到Mysql的test_received表)

在Window-->Show View中打开Map/Reduce Locations。
在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中填写配置Location name可以随意填写,Map/Reduce Master和DFS Master里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。username填写主节点的名称。
然后是打开“Advanced parameters”设置面板,修改相应参数。
dfs.datanode.data.dir dfs.namenode.name.dir等
点击Finish后可以看到HDFS结构。
设置成功。即可用之!
十二、 总结及常见问题:
现象:当停止Hadoop的时候发现no datanode to stop的信息
原因1:每次namenode format会重新创建一个namenodeId,而tmp/dfs/data下包含了上次format下的id,namenode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空tmp一下的所有目录。
这里有两种解决方案:
1)删除“/usr/hadoop/tmp”里面的内容
rm -rf /usr/hadoop/tmp/*
2)删除“/tmp”下以“hadoop”开头的文件
rm -rf /tmp/hadoop*
3)重新格式化hadoop
hadoop namenode -format
4)启动hadoop
start-all.sh
这种方案的缺点是原来集群上的重要数据全没有了。因此推荐第二种方案:
1)修改每个Slave的namespaceID,使其与Master的namespaceID一致。
或者
2)修改Master的namespaceID使其与Slave的namespaceID一致。
Master的“namespaceID”位于“/usr/hadoop/tmp/dfs/name/current/VERSION”文件里面,Slave的“namespaceID”位于“/usr/hadoop/tmp/dfs/data/current/VERSION”文件里面。
原因2:问题的原因是hadoop在stop的时候依据的是datanode上的mapred和dfs进程号。而默认的进程号保存在/tmp下,linux 默认会每隔一段时间(一般是一个月或者7天左右)去删除这个目录下的文件。因此删掉hadoop-hadoop-jobtracker.pid和hadoop-hadoop-namenode.pid两个文件后,namenode自然就找不到datanode上的这两个进程了。
在配置文件hadoop_env.sh中配置export HADOOP_PID_DIR可以解决这个问题。
在配置文件中,HADOOP_PID_DIR的默认路径是“/var/hadoop/pids”,我们手动在“/var”目录下创建一个“hadoop”文件夹,若已存在就不用创建,记得用chown将权限分配给hadoop用户。然后在出错的Slave上杀死Datanode和Tasktracker的进程(kill -9 进程号),再重新start-all.sh,stop-all.sh时发现没有“no datanode to stop”出现,说明问题已经解决。
hadoop集群Number of Under-Replicated Blocks问题
跑了一个mapreduce发现集群上出现了7个Under-Replicated Blocks,在web页面上能看到,在主节点上执行:
$ bin/hadoop fsck -blocks 重启完了即好啦。
现象三:在使用MyEclipse时,上传文件,会出现以下情况:

这是因为没有文件写权限所致,解决方法为:
修改HDFS中相应文件夹的权限,后面的/user/hadoop这个路径为HDFS中的文件路径,这样修改之后就让我们的administrator有在HDFS的相应目录下有写文件的权限(所有的用户都是写权限)。之后问题解决了!!

在运行Eclipse时还会发现,如果想要输出文件放在/user/lb/output/output.dat
可能会出现无法操作,不能写入的情况,那么要hadoop dfs -chmod 777 /user/lb/output才行。
现象四:hadoop1.2.1在windows远程调试linux的程序时,报错:
12/04/24 15:32:44 ERROR security.UserGroupInformation: PriviledgedActionException as:Administrator cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to 0700
Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to 0700
...
...
解:这个是Windows下文件权限问题,在Linux下可以正常运行,不存在这样的问题。
解决方法是,修改/hadoop-1.0.2/src/core/org/apache/hadoop/fs/FileUtil.java里面的checkReturnValue,注释掉即可(有些粗暴,在Window下,可以不用检查)
- ......
- private static void checkReturnValue(boolean rv, File p,
- FsPermission permission
- ) throws IOException {
- /**
- if (!rv) {
- throw new IOException("Failed to set permissions of path: " + p +
- " to " +
- String.format("%04o", permission.toShort()));
- }
- **/
- }
- ......
最后重新编译打包hadoop-core-1.2.1.jar,替换掉hadoop-1.2.1根目录下的hadoop-core-1.2.1.jar即可。
当然也可以直接从网上找一些,即可:下载地址为http://download.csdn.net/detail/echoqun/6198467
最后可以运行成功。
