A summary about gradient descent
There are three kind of gradient descent now:
1/ Traditional:
Like a people who wants to get down of the hill as soon as possible. Then he/she will find a way that has a big steepness of local place.
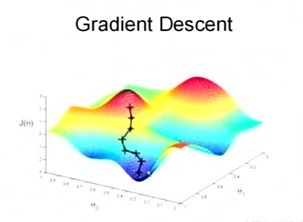
The biggest steepness direction is the direction of negative gradient(since the positive gradient represents the direction of increasing fastest).
In this situation, it is:

since the way we walk down the hill here is to change the θ to let the cost function be the lowest.
Once the cost function is convex function, we can get the global optimization.
The walk down is:
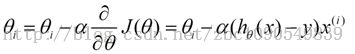
a is the learning rate. How big the walk down step is.
2/ Stochastic gradient descent(There is a very good explanation in Quora: https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent)
In general, the main difference is:
In this update we showed above, we only use one training sample. So there isn't any sum any more. We just calculate one sample to get the cost function.
3/ Mini-batch gradient descent
Mini-batch is the compromise of 1 and 2.
Instead of using all the data, it only sum up 100 or a particular amount of data. In order to improve the efficiency of gradient descent when the training dataset is so large.
Reference:
[1] https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
[2] http://blog.csdn.net/zbc1090549839/article/details/38149561
[3] http://blog.csdn.net/carson2005/article/details/21093989
[4] http://blog.csdn.net/lilyth_lilyth/article/details/8973972