Study Note: Optimization in MapReduce
云计算本质上是一种scalable的分布式计算。对于之前提到的many cores和multi-cores而言,最大的局限在于内存都是有限的。云计算完美解决了这个问题(用分割数据的方法)。
有两种分布式计算的方法:
1)好像openmp和cuda一样,允许共享内存空间,实行workload distribute。在分布式系统实现这种方法需要分清楚processnode和storage node. 但这种方法存在的问题是磁盘的I/O和网络带宽成为了局限,同时,程序猿需要同步、资源分配等问题。
2)只分数据,让各个节点自行计算各自部分的数据,最后再合计。(computeindependent) 这种就是can perform independent shared nothingcomputations on fragments of the dataset. Shared Nothing Architecture: Eachnode is independent and self-sufficient (none of the nodes share memory or diskstorage)。Mapreduce就是这样的一个sharenothing approach
具有scalable的算法是云计算的主要应用方向,什么是scalable的算法?

下面就来说说MapReduce平台:
介绍一些基础的概念:
一个实际的计算节点可能有多个map。一个节点对应着是一个task(一个mapper)。因为在mapreduce当中,mapper的分配框架自动决定的,人为无法干预。Mapper是被分配到存储数据的节点进行计算,我们不能指定某个mapper要去计算某一部分的数据。
但是我们可以修改中间键的排序算法和partition算法,决定哪个部分的Key会分配到某一个reducer。
同时,我们可以preserve state across multipleinput and intermediate key in mappers and reducers
优化和最大化mapreduce框架的效率的关键是:
(1)内存的合适利用。当mapper缓存的数据太多了,memory被paging到了disk的话,就是大大地降低MR的效率。所以,当多个map在一个node的时候,注意不要让他们用光内存。
(2)减少datatransfer over network.减少中间KV对的数目和大小。

MapReduce的优化方法主要是:
(1)平均工作量:
自定义partitioner,使得每个reducer 拥有均等的计算量
(2)调用合适数量的mapper与reducer
mapper的数量是框架自动决定的,我们只能定义有多少个节点以及输入数据的KV结构,但是reducer的数量是我们决定的(通过setreducer),我们需要注意的是不要让reducer的memory超载(从partitioner 和reducer的数量保证)
(3)对于mapreduce算法的实现需要设计模型的考虑

① 本地聚集:
本地聚集包含两种:combiner in map 还有 In-mapper combiner()
首先,我们要分清map和mapper的关系, 一个mapper可以循环执行多次map函数。本地聚集的目的是减少中间的KV对的数目和量。如果不使用关联数组来减少KV对,一个简单KV对就会输出并写入磁盘。有I/O和网络传输的延时。
引用的话:
举个常见的例子来说:数单词。假设现在有100 篇的文集,要数出每个单词出现的次数。MapRudce 接到这个任务后,首先检测文集数据的正确性。然后进行分割(这里我们采用逻辑上的分割)。比如集群有10 个TaskTracker可用。MapReduce 将100文档进行平均分割,每个TaskTracker会得到10篇文集。若每个TaskTracker运行一个Mapper的话,这10篇文集会一次被Mapper 处理(调用10次map函数)。10篇文集又会被分切成10个RecordReader形式的Key/Value(key=docId,value=docContent)。这样一个Mapper 一次就会处理一片文档。
① combiner in map: 只对一个map 函数处理的一片文档进行本地聚集(counts for entiredocument)
② In-mapper combiner 对一个mapper函数的所有map函数的处理文档进行本地聚集
(counts acrossdocuments)
如果需要使用这个,必须打开:mapreduce.job.jvm.numtasks=-1
使用本地聚集的话必须注意内存使用,不能溢出。以数单词为例,假设Mapper处理的10篇文档很大设计到很多的单词,这样关联数组势必会非常大,又可能大到一个JVM不能完全存储这个关联数组。当几个map在同一个Node进行的时候,会对内存资源产生竞争,降低效率。
另外,使用in-mapper combiner的时候,它破坏了MapReduce 编程模式(functionalprogramming paradigm due to state preservation)的基础,对于一些特定的算法它是不合适使用,比如某些算法要求对Map方法处理的Key/Value的中间结果先后有要求,那么这种In-Mapper Combining 是不适应的。
② Pairs and Stripes ——对一些共同出现的频数统计
Pairs: ((w1, w2), count)坏处:a large number ofintermediate kv, limited benefits of combiners 好处:no memory pagingproblem
Strips: (w1,[count(w1,w2),count(w1,w3)…]) 把对应的频数放在关联数组里
好处:fewer intermediate keys, benefits from combiners 坏处:values complex,overhead of read/write, memory paging problem.
Pairs:

Strips:

③ Order Inversion 求相对频率的分母——在mapper的输出利用combiner 去求
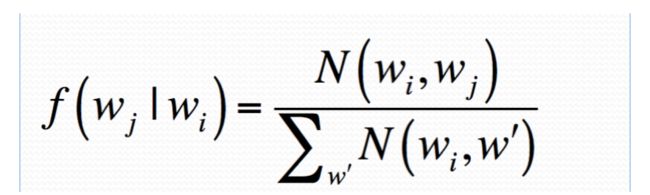
The denominator iscalled the marginal.
1、对于strip的KV,直接在reducer的时候求和就好
2、对于pairs 的KV,可以利用Mapreduce的特点,对于multiple keys,利用memory buffer(缓存) 一些中间KV。Buffer in memory all the words that co-occur with wi and their counts.