Hadoop in Practice
第8章 使用R和Hadoop进行统计分析及与之相关的信息
本章主要内容为:
Ø 将R脚本和MapReduce和Streaming集成起来
Ø 理解什么是Rhipe,RHadoop,R+Streaming
R是用于统计分析和图形展示的统计分析语言。R语言可以对数据进行统计和预测分析、数据挖掘、可视化后处理等操作。它有诸多功能且应用广泛,如在金融、生命科学、制造业、零售业等都有所应用,所以R是一种非常流行的工具。
对数据分析科学家而言,有了Hadoop就像拥有了核武库,同时还需要使用R软件包。如果用Java或者其它高级语言重写这些R软件包将非常繁琐且开发速度也会很慢。所以我们需要做的就是将R和Hadoop集成起来,在Hadoop和R中的数据库之间建立一座桥梁将他们连接起来。
在我们工作中,大部分的数据都是文本格式的,比如来自Twitter的tweets,log文件、和库存记录等都是文本类型的。本章将介绍如何使用R对文本类型的库存记录进行简单的平均计算。以这个计算为例,重点介绍R与Hadoop的三种集成方式:R通过Streaming与Hadoop集成、通过Rhipe集成、以及通过RHadoop集成。在本章结束的时候,你将学会R与Hadoop集成的各种方式,并为你的应用选择一种最适合的方式。
R和统计学:
本章主要介绍R和Hadoop的集成。更多关于R的信息参考<<R inAction>>这本书
(August 2011, http://www.manning.com/kabacoff/).有关统计学的参考书见<<Statistics:A Gentle Introduction>>, http://www.sagepub.com/books/Book235514.
8.1 R和MapReduce的集成方法概述
本节将介绍三种用于集成R和MapReduce的方法。选择者三种方法是因为其非常流行,为了演示R和MapReduce的集成方式,将使用这三种方法处理同一个问题。
1、R+Streaming:这种方式允许你在MapReduce模式的map和reduce阶段执行R脚本。
2、Rhipe:Rhipe是一个开源项目,它可以让MapReduce和R在客户端紧密结合在一起。
3、RHadoop:RHadoop和Rhipe类似,但其对R进行了MapReduce封装,所以在客户端其能够与MapReduce无缝集成。
表8.1对R和MapReduce的集成方式的某些特性进行了对比。
表8.1 R和MapReduce集成方式对比
| 特性 |
R+Streaming |
Rhipe |
RHadoop |
| 授权方式 |
R是GPL-2和GPL-3授权;Streaming是Apache2.0授权 |
Apache2.0 |
Apache2.0 |
| 安装复杂度 |
安装简单,需要在每台DataNode上安装R,R包可以方便从互联网获取 |
安装最复杂,R必须要安装在每个DataNode上,并和协议缓冲区以及Rhipe集成到一起,因此需要建立协议缓冲区,Rhipe不需要时无缝安装的,如果想让Rhipe工作起来,可能还要做些工作 |
安装中等复杂,R需要安装在每个DataNode上,RHadoop依赖R的某些包,这些包可以用CRAN安装,and the RHadoop installation, while not via CRAN, is straight-forward. |
| 客户端与R集成 |
无集成,必须使用Hadoop的命令行执行Streaming Job并通过参数定义map端和reduce端的R脚本 |
高度集成,Rhipe是一个R的库文件,当调用R函数时,它将控制执行MapReduce的Job。用户在R中写好map和reduce函数,Rhipe能够维护R写成的应用的逻辑传输关系,并在map和reduce的任务中调用R脚本 |
高度集成,RHadoop也是R的一个库,用户可以在R中定义map和reduce脚本 |
| 使用的底层技术 |
Streaning |
和Streaming不同Rhipe没有使用Hadoop的map和reduce函数,Rhipe以协议缓冲区编码的形式将map和reduce的输入分配给Rhipe的可执行C程序,可执行程序使用R调用用户的map和reduce脚本 |
RHadoop技术简单,其在Hadoop和Streaming的顶层做了封装。因此,它没有专门的MapReduce代码,它只有一个简单的能够被Streaming调用的R脚本,以达到轮流调用用户用R编写的map和reduce脚本 |
哪种工具最适合你的应用?当你学习了本章内容之后,你将会找到适合自己的工具。表8.2是作者对这三种工具适用范围的描述。
表8.2 对三种方式适用情况的描述
| 方式 |
适用情况 |
需要牢记的点 |
| R+Streaming |
如果你想控制你的MapReduce函数,比如控制分割和排序过程 |
与其它方式比起来,该法无法从R脚本中直接调用执行 |
| Rhipe |
如果你现在R环境中使用R和MapReduce,可以选择该方式 |
为了能够和协议缓冲区的编码数据一起工作,要求此种方法的输入、输入符合特定的数据格式 |
| RHadoop |
如果你既不想离开R环境,又能够控制MapReduce的输入输出格式,可以采用此方法 |
需要大内存,因为一个键所对应的值都要存储在内存中,值并不会流到reduce函数 |
8.2 R基础
这部分介绍R的安装及R的基本语法结构和数据类型。
安装:
可以参照附录A安装R。需要注意的是:在所有节点上,要将R安装在相同的路径中,而且要求R的版本要一至。
启动R并运行简单的脚本命令:
启动R很简单,在终端输入R即可,如下

快速入门:
下面将介绍一些R的基本知识,以帮助理解本章中所用到的技术,详细内容如图8.1。
在R中向量是很有用的数据结构,因为大多数数值计算的函数都支持向量格式的数据结构。图8.2介绍了一些R 的向量知识。
R语言还支持其它一些数据结构,如:矩阵、数组、数据帧、因子等数据结构。本章中将主要介绍向量的使用,因为本章中主要用到向量。所以其它数据结构不做过多介绍。如果要了解R的更详细知识,可以参考Robert Kabacoff的《R in Action》(http://www.manning.com/kabacoff/)。

图8.1 R中变量使用实例

图8.2 R中向量和函数使用实例
以上已经介绍了R语言的一些简单知识。下面将介绍如何将Hadoop的Streaming与R结合起来。
8.3 R和Streaming
只要是支持标准输入、输出流的脚本语言都可以写成map和reduce函数与Hadoop的Streaming集成。在本节中将会看到R语言如何与Streaming集成,首先介绍只有map的作业情况,然后介绍map和reduce函数都有的作业情况。本例中将使用股票数据并进行简单的计算。目的是介绍如何通过Streaming将R和Hadoop集成起来。
8.3.1Streming和只有map的R脚本
就像普通的MapReduce一样,也可以用R编写只有map而没有reduce的R作业与Streaming集成。在不需要对数据进行合并、分组等操作时,可以使用只有map而没有reduce的作业。
技巧57:计算股票数据的日均值
在这个技术中,介绍Hadoop的Streaming与R集成计算股票数据的日均值。
问题描述:
将R和MapReduce集成起来,不需要对数据进行合并和排序。
解决方法:
采用只有map的作业处理数据。
详细介绍:
该技术将工作在CSV文件上,对于每只股票包括如下信息:
Symbol,Date,Open,High,Low,Close,Volume,AdjClose
查看股票子集内容如下:
$ head -6test-data/stocks.txt
AAPL,2009-01-02,85.88,91.04,85.16,90.75,26643400,90.75
AAPL,2008-01-02,199.27,200.26,192.55,194.84,38542100,194.84
AAPL,2007-01-03,86.29,86.58,81.90,83.80,44225700,83.80
AAPL,2006-01-03,72.38,74.75,72.25,74.75,28829800,74.75
AAPL,2005-01-03,64.78,65.11,62.60,63.29,24714000,31.65
AAPL,2004-01-02,21.55,21.75,21.18,21.28,5165800,10.64
在作业中将计算没行中开始和结束的股价均值。实现功能的R脚本如下:
#! /usr/bin/envRscript //用于识别可以执行脚本的R进程名
options(warn=-1)//屏蔽警告信息,可以减少输出流的杂乱程度
sink("/dev/null")//sink函数控制输出的位置。因为R代码被Streaming使用,用户就需要控制标准输出流的内容,因此重定向R的输出到/dev/null
input <-file("stdin", "r") //打开标准输入句柄
while(length(currentLine<-readLines(input, n=1, warn=FALSE)) > 0) //从标准输入中读入数据,n是每次读入的数据行数,将warn设置为FALSE,因为在标准输入流中无法读取EOF结束标记。如果读取了一个空行,意味着输入结束。
{
fields <- unlist(strsplit(currentLine,",")) //将读取的字符串按照逗号分隔,并将结果转化为向量
lowHigh <- c(as.double(fields[3]),as.double(fields[6])) //将股票的开盘和收盘价格放到一个向量中
mean <- mean(lowHigh) //计算均值
sink() // 调用无参数的sink函数,恢复输出位置
cat(fields[1], fields[2], mean,"\n", sep="\t") //将每天的股票名称、日期、均值写到标准输出流
sink("/dev/null") // 重定向R的输出到/dev/null.
}
close(input)
总结:
图8.3中展示了只有map时Streaming和R的集成。
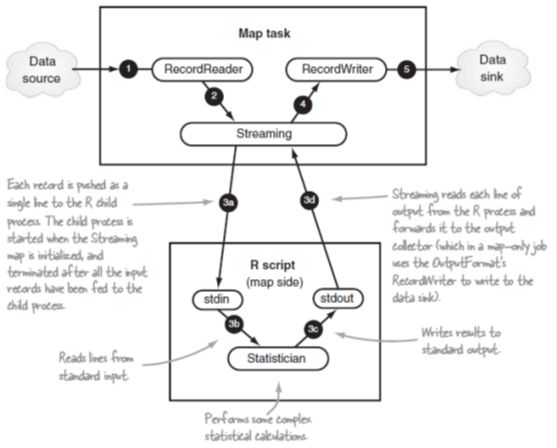
图8.3 只有map的R和Streaming数据流
为了测试map脚本的正确性,可以对任何MapReduce的代码进行修改。但是最方便的办法是不用启动MapReeduce而直接在命令行中对map脚本进行测试。下面用Linux的cat命令对R脚本进行测试
$ cattest-data/stocks.txt | src/main/R/ch8/stock_day_avg.R
AAPL 2009-01-0288.315
AAPL 2008-01-02197.055
AAPL 2007-01-0385.045
AAPL 2006-01-0373.565
...
输出无误,所以可以进行Hadoop上的计算了
$ exportHADOOP_HOME=/usr/lib/hadoop //设置Hadooop安装路径,该路径必须是全路径
$ ${HADOOP_HOME}/bin/hadoopfs -rmr output //删除HDFS上的output文件,如果HDFS上不存在output文件,会产生一个警告,该警告可以忽略
$${HADOOP_HOME}/bin/hadoop fs -put test-data/stocks.txt \
stocks.txt // 拷贝股票数据到HDFS
$${HADOOP_HOME}/bin/hadoop \
jar${HADOOP_HOME}/contrib/streaming/*.jar \ //定义运行Streaming的JAR文件,这里必须给出完成路径
-Dmapreduce.job.reduces=0 \ //因为只有map,所以讲reduce的数量设置为0
-inputformatorg.apache.hadoop.mapred.TextInputFormat \ //定义输入格式
-inputstocks.txt \ //设置输入文件
-output output \//设置输出路径
-mapper`pwd`/src/main/R/ch8/stock_day_avg.R \ //通知Streming在map阶段可以运行的文件位置
-file`pwd`/src/main/R/ch8/stock_day_avg.R //定义需要被拷贝到分布式缓存中并被map作业使用的R脚本所在的位置
用cat查看output中的数据,其和直接调用R脚本产生的数据一致:
$ hadoop fs -catoutput/part*
AAPL 2009-01-0288.315
AAPL 2008-01-02197.055
AAPL 2007-01-0385.045
AAPL 2006-01-0373.565
...
在以上的命令中使用了TextInputFormat,该出入格式产生key/value对,key值是value在文件中的偏移量,value是每行数据。在R脚本中仅使用了value。这是因为在Hadoop的Streaming中做了优化处理,如果检测到使用TextInputFormat格式,Streaming将忽略key值,如果希望key值不被忽略可以将属性stream.map.input.ignoreKey设置为true。
图8.4显示了一些Streming的配置
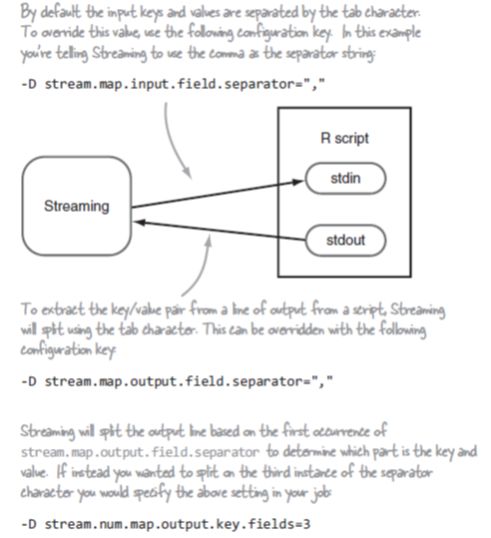
图8.4 map任务的Streaming配置
现在应该理解如何使用R和Streaming实现只有map的作业了。下面介绍如何实现既有map又有reduce的作业。
8.3.2Streaming,R实现完全MapReduce
现在演示如何实现完全的MapReduce作业。在8.3.1的基础上介绍如何构建reduce函数。当map和reduce函数都完成后。我们将会看到Hadoop的Streaming如何将map输出的键值对输出到R的标准输入流中的,以及如何收集R函数的输出结果。
技巧58:计算股票的累积移动平均
在技巧57中计算了股票的每天平均值,下面将使用MapReduce框架收集同一只股票每天的平均值,然后计算股票的累积移动平均(CMA)。
问题描述:
希望在map端和reduce端与Streaming集成
解决方法:
使用R和Hadoop的Streaming编写的map和reduce函数与Streaming集成起来
详细介绍:
只执行map端的作业时,产生如下空格分隔的域:
Symbol Date Mean
MapReduce将对map输出的key值(股票的名称,即Symbol)进行排序和分组。MapReduce将与同一只股票相关的由map输出的值传递给reduce。reduce脚本中对所有的均值进行求和,reduce最终的输出包括CMA。
#! /usr/bin/envRscript
options(warn=-1)
sink("/dev/null")
outputMean <-function(stock, means) //该函数将股票的名称和均值向量作为输入参数,计算CMA后,将股票名称和CMA写入到标准输出中
{
stock_mean <- mean(means)
sink()
cat(stock, stock_mean, "\n",sep="\t")
sink("/dev/null")
}
input <-file("stdin", "r")
prevKey <-"
means <-numeric(0)
while(length(currentLine<- readLines(input, n=1, warn=FALSE)) > 0)
{
fields <- unlist(strsplit(currentLine,"\t"))
key <- fields[1] //读股票名称
mean <- as.double(fields[3]) //从输入流中读取均值
if( identical(prevKey, ") ||identical(prevKey, key))
{
prevKey <- key
means <- c(means, mean)
}
else
{
outputMean(prevKey, means) //当找到一个新的key值时,意味着有一个新的map输出的key,这也意味着此时需要调用参数计算CMA并将结果写到标准输出中
prevKey <- key
means <- c(means, mean)
}
}
if(!identical(prevKey,"))
{
outputMean(prevKey, means)
}
close(input)
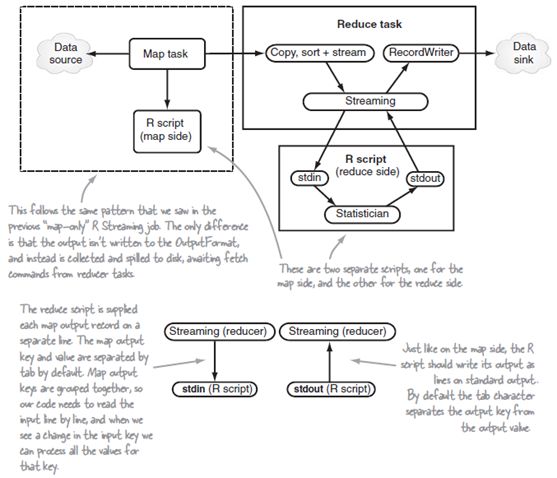
图8.5 R和Streaming的MapReduce数据流
总结:
图8.5中显示了Streaming和R脚本在reduce端的工作模式。Streaming的好处是可以使用Linux的流命令此时R脚本,命令如下:
$ cattest-data/stocks.txt | src/main/R/ch8/stock_day_avg.R | \
sort --key 1,1 |src/main/R/ch8/stock_cma.R
AAPL 68.997
CSCO 49.94775
GOOG 123.9468
MSFT 101.297
YHOO 94.55789
上面输出的结果正确,所以下面开始执行Hadoop作业:
$ exportHADOOP_HOME=/usr/lib/hadoop
$${HADOOP_HOME}/bin/hadoop fs -rmr output
$ ${HADOOP_HOME}/bin/hadoopfs -put test-data/stocks.txt stocks.txt
$${HADOOP_HOME}/bin/hadoop \
jar${HADOOP_HOME}/contrib/streaming/*.jar \
-inputformatorg.apache.hadoop.mapred.TextInputFormat \
-inputstocks.txt \
-output output \
-mapper`pwd`/src/main/R/ch8/stock_day_avg.R \ //定义map脚本
-reducer`pwd`/src/main/R/ch8/stock_cma.R \ //定义reduce脚本
-file`pwd`/src/main/R/ch8/stock_day_avg.R \
-file`pwd`/src/main/R/ch8/stock_cma.R
用cat命令查看output结果,其与Linux测试结果相同,结果如下:
$ hadoop fs -catoutput/part*
AAPL 68.997
CSCO 49.94775
GOOG 123.9468
MSFT 101.297
YHOO 94.55789
图8.6显示了某些Streaming参数项,其可以对reduce的输入、输出进行控制。

图8.6 用于控制reduce输入、输出的Streaming参数
如果map的输出值在传递给reduce之前需要按照一定的顺序排列(被称之为二次排序),这时该如何处理。二次排序的内容在第4章和第七章有详细介绍。在Streaming中进行二次排序时可以通过KeyFieldBasedPartitioner,设置,设置方法如下:
$ exportHADOOP_HOME=/usr/lib/hadoop
$${HADOOP_HOME}/bin/hadoop fs -rmr output
$${HADOOP_HOME}/bin/hadoop fs -put test-data/stocks.txt stocks.txt
$${HADOOP_HOME}/bin/hadoop \
jar${HADOOP_HOME}/contrib/streaming/*.jar \
-Dstream.num.map.output.key.fields=2 \ //定义股票的名称和日期是map输出的key的一部分
-Dmapred.text.key.partitioner.options=-k1,1\ //定义MapReduce按照map输出的第一个字符,即股票名称,进行分割
-inputformatorg.apache.hadoop.mapred.TextInputFormat \
-inputstocks.txt \
-output output \
-mapper`pwd`/src/main/R/ch8/stock_day_avg.R \
-reducer`pwd`/src/main/R/ch8/stock_cma.R \
-partitioner \ //设置KeyFieldBasedPartitioner参数,其将解析mapred.text.key.partitioner.options决定分割方法
org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner\
-file`pwd`/src/main/R/ch8/stock_day_avg.R
更多关于Streaming关于排序控制的内容见Hadoop的Streaming文档。
至此已经完成了R与Streaming集成计算股票均值的全部内容。这种方式的缺点是,在客户端R脚本与Hadoop的集成不是那么方便。这也正是Rhipe和RHadoop需要解决的问题。下面将介绍Rhipe。
8.4 Rhipe-R和Hadoop客户端无缝集成
Rhipe是R和Hadoop集成处理环境的简称,它是一个开源项目。与Streaning相比Rhipe使R和Hadoop更紧密的结合在一起。在8.3中通过命令行将R和Hadoop集成起来,而在Rhipe中可以在R中直接运行MapReduce程序。
在开始Rhipe之前,需要按照附录A中的方法,在集群上安装Rhipe及其依赖项。
技巧59:使用Rhipe计算累积移动平均
在该节中将再次计算每只股票的CMA。但是实现的技术采用Rhipe,你将会看到R和Hadoop的是如何紧密结合在一起的。
1)问题描述:
希望在R代码中直接调用Hadoop。
2)解决方法:
该例子演示如何使用Rhipe在客户端,直接从R中调用MapReduce作业。同时也会看到Rhipe的MapReduce作业中Rhipe的R回调函数的使用方式。
3)详细介绍:
下面介绍用Rhipe脚本计算CMA。值得注意的是,MapReduce完全嵌入在Rhipe中,这便于将现有的R脚本与MapReduce集成到一起,脚本如下:
#! /usr/bin/env Rscript
library(Rhipe)//加载Rhipe库到内存
rhinit(TRUE,TRUE)//初始化Rhipe
map <- expression({//定义map代码,其在map端执行
process_line <- function(currentLine) {
fields <- unlist(strsplit(currentLine, ","))
lowHigh <- c(as.double(fields[3]), as.double(fields[6]))
rhcollect(fields[1], toString(mean(lowHigh)))//调用Rhipe的rhcollect函数生成map阶段的键值对
}
lapply(map.values, process_line)
})
reduce <- expression(
pre = {//reduce阶段保留了三个步骤,在输入reduce的value值赋给reduce模块之前,对于map输出的每个key,都会调用pre模块一次,map输出的key值存储在reduce.key中(此处没有使用)
means <- numeric(0)
},
reduce = {//调用reduce模块,value值以向量形式存储在reduce.value中,如果value的值个数大于10000时,该模块会被调用多次,知道value的值读取完毕
means <- c(means, as.numeric(unlist(reduce.values)))
},
post = {//和map中的类似,调用rhcollect产生最终的键值对结果
rhcollect(reduce.key, toString(mean(means)))
}
)
input_file <- "stocks.txt"
output_dir <- "output"
job <- rhmr(//用rhmr函数设置作业
jobname = "Rhipe CMA",
map = map,
reduce = reduce,
ifolder = input_file,
ofolder = output_dir,
inout = c("text", "sequence")
)
rhex(job)//启动MapReduce作业
4)总结
和Streaming方式相比,使用Rhipe可以直接在R脚本中执行MapReduce作业
$ hadoop fs -put test-data/stocks.txt /tmp/stocks.txt
$ export HADOOP_BIN=/usr/lib/hadoop/bin
$ src/main/R/ch8/stock_cma_rhipe.R//脚本stock_cma_rhipe.R可以直接运行,因为在开始运行时其会通知shell,该脚本的运行方式是通过Rhipe执行的。
为了理解Rhipe的工作方式,以及R代码是如何和Rhipe一起工作的,这就需要了解Rhipe的一系列工作流。首先分析R脚本,理解MapReduce作业是如何被触发的,如图8.7所示:

图8.7更高层次的Rhipe流程
下面展示Rhipe是如何与MapReduce任务上下文一起工作的,首先从map端的任务开始,见图8.8。
Rhipe在reduce端工作方式见图8.9。
Rhipe还包括了一系列用于读取HDFS文件的函数,更多信息参考:http://saptarshiguha.github.com/RHIPE/functions.html#hdfs-related。
需要注意的一点是,Rhipe没有使用Streaming,而是使用其自己的map和reduce函数,以及其自己的输入、输出格式。所以如果你的数据的输入、输出格式和Rhipe要求的不一样,将无法使用。
至此,以及介绍了Rhipe的使用过程,Rhipe提供了R和Hadoop在客户端的集成方式。下一部分介绍RHadoop,其也在客服端提供了R与Hadoop的集成方式,RHadoop更注重于轻量级层面的集成。

图8.8 map端的Rhipe

图8.9 reduce端Rhipe
8.5 RHadoop-R和Hadoop客户端简单集成
RHadoop是由Revolution Analytics创建的开源项目,它提供了另一种R与Hadoop集成的方式,和Rhipe类似,在客户端的R脚本中执行MapReduce程序。
RHadoop由三部分组成:
1 rmr:支持MapReduce集成
2 rdfs:HDFS的R接口
3 rhbase:R与HBase接口
本节主要介绍rmr,因为R与MapReduce的集成是最常使用的,如果想完全理解R和Hadoop的集成,rdfs和rhbase亦值得一窥。
安装RHadoop以及依赖项,可以参考、附录A。
技术60:用RHadoop计算CMA
在这部分介绍如何用RHadoop计算股票的CMA。
1)问题描述:
R和Hadoop在客户端的轻量级集成
2)解决方法:
该技术介绍如何使用RHadoop,在R脚本中直接启动MapReduce作业,同时也会看到RHadoop是如何和Streaming一起工作的。
3)详细介绍:
从概念上来看,RHadoop的工作方式和Rhipe类似,Rhipe中需要设置map和reduce的操作控制,而在RHadoop这也会有类似的设置。
#! /usr/bin/env Rscript
library(rmr)//加载rmr库
map <- function(k,v) {//定义map函数,它的输入是key,value对,调用keyval函数输出map的key,value
fields <- unlist(strsplit(v, ","))
keyval(fields[1], mean(as.double(c(fields[3], fields[6]))))
}
reduce <- function(k,vv) {//每有个map输出的key值,就要调用一次reduce函数,k代表key值,v是一系列值
keyval(k, mean(as.numeric(unlist(vv))))
}
kvtextoutputformat = function(k,v) {//自定义reduce的key,value输出时的分割方式
paste(c(k,v, "\n"), collapse = "\t")
}
mapreduce( //运行MapReduce作业
input = "stocks.txt",
output = "output",
textinputformat = rawtextinputformat,
textoutputformat = kvtextoutputformat,
map = map,
reduce = reduce)
为了执行RHadoop,可以运行如下命令:
$ HADOOP_HOME=<Hadoop installation directory>
$ $HADOOP_HOME/bin/hadoop fs -put test-data/stocks.txt stocks.txt
$ src/main/R/ch8/stock_cma_rmr.R
$ hadoop fs -cat output/part*
CSCO 30.8985
MSFT 44.6725
AAPL 68.997
GOOG 419.943
YHOO 70.971
rmr和Rhipe不同,因为rmr使用的是Streaming。图8.10展示了R代码是如何与MapReduce作业一起工作的。
rmr比较有趣的特性是,在MapReduce的map和reduce中可以使用R的客户端环境。这意味着map和reduce函数可以引用函数体外面的变量,这对R的开发者来说意义重大。

图8.10 rmr和客户端的交互
rmr还有另外一项特性,它可以和MapReduce的输入、输出无缝集成。在该例子中作业的输入已经在HDFS上,在R中不需要与输出进行交互。rmr可以将R变量直接写入HDFS作为MapReduce作业的输入,但计算结束后在将HDFS上的结果加载成为R的数据结构。在处理大数据集是RHadoop可能有些捉襟见肘,但在小数据集的测试和原型验证时其还是有相当优势。
$ R
> library(rmr)
> small.ints = to.dfs(1:10)//创建1:10的数组,将结果存储在HDFS
> out = mapreduce( //The result from the MapReduce job is a closure that can
be used to read the results back out of HDFS
input = small.ints,
map = function(k,v) keyval(v, v^2))
...
> result = from.dfs(out) //从HDFS读取结果
> print(result)
[[1]]
[[1]]$key
[1] 10
[[1]]$val
[1] 100
attr(,"rmr.keyval")
[1] TRUE
...
如果希望学习更多的rmr示例,可以参考https://github.com/RevolutionAnalytics/RHadoop/blob/master/rmr/pkg/docs/tutorial.md。
8.6本章小结
R和Hadoop的融合使大规模统计计算成为可能。随着数据规模和分析需求的增长,R和Hadoop的融合技术变得引人注目。本章主要集中讨论了三种可以将R和Hadoop集成在一起的技术。R和Streaming提供了较低层次的集成,Rhipe和RHadoop框架提供了在客户端R与Hadoop集成。
在学习完本章之后,你可以为自己的项目选择合适的技术。
下一章将继续数据科学主题,主要介绍Mahout用于预测分析。