Linux内核可加载模块基础(2)
file_operations结构体定义在linux/fs.h文件中,并且包含一系列函数指针这些函数指针最终都会由驱动程序实现的函数来进行填充(由于之前的驱动都只有两个函数,一个在加载时被调用,而另一个则在卸载的时候被调用)。文件操作体结构通用函数如下所示:
struct file_operations {
struct module *owner;
loff_t(*llseek) (struct file *, loff_t, int);
ssize_t(*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t(*aio_read) (struct kiocb *, char __user *, size_t, loff_t);
ssize_t(*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t(*aio_write) (struct kiocb *, const char __user *, size_t,
loff_t);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int,
unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t(*readv) (struct file *, const struct iovec *, unsigned long,
loff_t *);
ssize_t(*writev) (struct file *, const struct iovec *, unsigned long,
loff_t *);
ssize_t(*sendfile) (struct file *, loff_t *, size_t, read_actor_t,
void __user *);
ssize_t(*sendpage) (struct file *, struct page *, int, size_t,
loff_t *, int);
unsigned long (*get_unmapped_area) (struct file *, unsigned long,
unsigned long, unsigned long,
unsigned long);
};
每一个设备由内核中的file结构体表示,这个结构体在linux/fs.h中定义。而对文件系统的分析可以知道,file是文件所通用的一个结构体,在file结构体中存在一个结构体指针,这个结构体指针就是指向具体的文件操作结构体——也就是上面陈列的file_operation。至于文件操作结构体存在于驱动程序中,只要驱动程序在内存中就不会出错。而file结构体则通过内核调用相关的函数生成。
字节性设备驱动程序中,对应的File结构体和file_operation结构体的是通过register_chrdev函数关联起来的。下面是这个函数的函数原型:int register_chrdev(unsigned int major, const char *name, struct file_operations *fops);
传递进去的第一个参数是设备的主版本号,第二个参数将会出现在/proc/devices目录中,而fops是一个file_operations指针。参数中没有次版本号,因为系统不关注次版本号是多少,如果传递的主版本号等于0,则表明主版本号由系统进行自动分配,返回值就是动态分配的主版本号。然而,动态返回的主版本号不便于之后调用mknod创建文件节点。因此创建文件节点可能需要在注册成功之后调用mknod的系统调用,或者从/proc/modules获得文件信息利用一个脚本创建设备文件。
驱动在卸载的时候,需要将文件结构体和文件操作结构进行分离,这个功能是由unregister_chrdev函数实现的。这个函数会进行清理工作,当然前提是加载的驱动的引用计数下降到0。在添加了file_operation的驱动程序中,就可以通过mknod创建一个/dev/目录下的设备文件,并通过对/dev/目录下的文件进行操作,从而达到控制设备的目的。#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <asm/uaccess.h> /* for put_user */
int init_module(void);
void cleanup_module(void);
static int device_open(struct inode *, struct file *);
static int device_release(struct inode *, struct file *);
static ssize_t device_read(struct file *, char *, size_t, loff_t *);
static ssize_t device_write(struct file *, const char *, size_t, loff_t *);
#define SUCCESS 0
#define DEVICE_NAME "chardev"
#define BUF_LEN 80
static int Major;
static int Device_Open = 0;
static char msg[BUF_LEN];
static char *msg_Ptr;
static struct file_operations fops = {
.read = device_read,
.write = device_write,
.open = device_open,
.release = device_release
};
int init_module(void)
{
Major = register_chrdev(0, DEVICE_NAME, &fops);
if (Major < 0) {
printk(KERN_ALERT "Registering char device failed with %d\n", Major);
return Major;
}
printk(KERN_INFO "I was assigned major number %d. To talk to\n", Major);
printk(KERN_INFO "the driver, create a dev file with\n");
printk(KERN_INFO "'mknod /dev/%s c %d 0'.\n", DEVICE_NAME, Major);
printk(KERN_INFO "Try various minor numbers. Try to cat and echo to\n");
printk(KERN_INFO "the device file.\n");
printk(KERN_INFO "Remove the device file and module when done.\n");
return SUCCESS;
}
void cleanup_module(void)
{
int ret = unregister_chrdev(Major, DEVICE_NAME);
if (ret < 0)
printk(KERN_ALERT "Error in unregister_chrdev: %d\n", ret);
}
static int device_open(struct inode *inode, struct file *file)
{
static int counter = 0;
if (Device_Open)
return -EBUSY;
Device_Open++;
sprintf(msg, "I already told you %d times Hello world!\n", counter++);
msg_Ptr = msg;
try_module_get(THIS_MODULE);
return SUCCESS;
}
static int device_release(struct inode *inode, struct file *file)
{
Device_Open--; /* We're now ready for our next caller */
module_put(THIS_MODULE);
return 0;
}
static ssize_t device_read(struct file *filp,char *buffer,size_t length, loff_t * offset)
{
int bytes_read = 0;
if (*msg_Ptr == 0)
return 0;
while (length && *msg_Ptr) {
put_user(*(msg_Ptr++), buffer++);
length--;
bytes_read++;
}
return bytes_read;
}
static ssize_t
device_write(struct file *filp, const char *buff, size_t len, loff_t * off)
{
printk(KERN_ALERT "Sorry, this operation isn't supported.\n");
return -EINVAL;
}
除了通过/dev/目录操作设备之外,Linux还可以直接通过/proc文件系统对设备进行操作。/proc原来是一个获取当前系统中存在的进程的信息的接口,而现在可以用于处理内核中处在于内存中的相应的节点。利用/proc文件系统对设备驱动进行访问的方式和运用设备文件操作结构体的方式很类似。受限创建一个/proc文件结构体,这个结构体中包括访问相应模块所必须的信息——比如/proc文件结构体中的访问指针。同样,在模块加载的时候将这个结构体与内核中的相应文件进行关联,而在模块卸载时则进行清除。
之所以需要/proc文件系统是因为/dev目录下的文件存在于磁盘上,而/proc中的文件存在于内存中,/proc目录下的文件不包含/dev目录下文件打开的计数,因此可能造成信息不统一——当模块已经卸载时却被多个进程打开。
下面是一个/proc文件系统的例子,整个/proc文件系统的操作分为三个部分。首先在驱动初始化时创建一个/proc文件系统文件/proc/helloworld,返回值类似于普通文件系统下的file_operation,这个结构体中的函数指针在创建之后会被填充。初始化之后,就可以通过填充的函数指针进行相应的驱动操作,最后再卸载时删除相应的结构体。在读取操作中需要注意的是,当这个函数返回值不等于0时,这个函数将会陷入到死循环调用当中。#include <linux/module.h> /* Specifically, a module */
#include <linux/kernel.h> /* We're doing kernel work */
#include <linux/proc_fs.h> /* Necessary because we use the proc fs */
#include <asm/uaccess.h> /* for copy_from_user */
#define PROCFS_MAX_SIZE 1024
#define PROCFS_NAME "buffer1k"
static struct proc_dir_entry *Our_Proc_File;
static char procfs_buffer[PROCFS_MAX_SIZE];
static unsigned long procfs_buffer_size = 0;
int procfile_read(char *buffer,
char **buffer_location,
off_t offset, int buffer_length, int *eof, void *data)
{
int ret;
printk(KERN_INFO "procfile_read (/proc/%s) called\n", PROCFS_NAME);
if (offset > 0) {
ret = 0;
} else {
memcpy(buffer, procfs_buffer, procfs_buffer_size);
ret = procfs_buffer_size;
}
return ret;
}
int procfile_write(struct file *file, const char *buffer, unsigned long count,
void *data)
{
procfs_buffer_size = count;
if (procfs_buffer_size > PROCFS_MAX_SIZE ) {
procfs_buffer_size = PROCFS_MAX_SIZE;
}
if ( copy_from_user(procfs_buffer, buffer, procfs_buffer_size) ) {
return -EFAULT;
}
return procfs_buffer_size;
}
int init_module()
{
Our_Proc_File = create_proc_entry(PROCFS_NAME, 0644, NULL);
if (Our_Proc_File == NULL) {
remove_proc_entry(PROCFS_NAME, &proc_root);
printk(KERN_ALERT "Error: Could not initialize /proc/%s\n",
PROCFS_NAME);
return -ENOMEM;
}
Our_Proc_File->read_proc = procfile_read;
Our_Proc_File->write_proc = procfile_write;
Our_Proc_File->owner = THIS_MODULE;
Our_Proc_File->mode = S_IFREG | S_IRUGO;
Our_Proc_File->uid = 0;
Our_Proc_File->gid = 0;
Our_Proc_File->size = 37;
printk(KERN_INFO "/proc/%s created\n", PROCFS_NAME);
return 0; /* everything is ok */
}
void cleanup_module()
{
remove_proc_entry(PROCFS_NAME, &proc_root);
printk(KERN_INFO "/proc/%s removed\n", PROCFS_NAME);
}
在上面的程序中,存在一个未定义的proc_root。实际上这个函数在当前代码中没有被定义,然而存在与内核中,而makefile将会调用到内核中相应的头文件,因此即使没有在当前文件中定义也照样可以编译通过。
上面的例子是通过/proc中的文件接口处理/proc文件系统中的文件,同样也可以通过标准文件节点处理/proc中的文件,利用文件节点操作/proc文件系统中的文件可以使用一些标准文件系统下的特有的函数,比如权限验证。在Linux中,存在一个标准的文件处理机制用于文件系统注册。由于每个文件系统都存在自身所特有的函数来操作文件节点和以及相应的文件操作。因此存在一个通用的结构体inode_operations,这个结构体组成VFS的接口层。这个结构体将上层传递下来的针对特定文件系统的调用传递给下层特定的文件系统的操作结构体——结构体inode_operation包含一个指向file_operations结构体的指针,而后者则会包含对文件系统的处理函数。在/proc文件系统中,不论何时当我们注册一个新文件,都会创建一个相应的inode_operations来对相应的文件进行访问。#include <linux/kernel.h> /* We're doing kernel work */
#include <linux/module.h> /* Specifically, a module */
#include <linux/proc_fs.h> /* Necessary because we use proc fs */
#include <asm/uaccess.h> /* for copy_*_user */
#define PROC_ENTRY_FILENAME "buffer2k"
#define PROCFS_MAX_SIZE 2048
static char procfs_buffer[PROCFS_MAX_SIZE];
static unsigned long procfs_buffer_size = 0;
static struct proc_dir_entry *Our_Proc_File;
static ssize_t procfs_read(struct file *filp, char *buffer,size_t length, loff_t * offset)
{
static int finished = 0;
if ( finished ) {
printk(KERN_INFO "procfs_read: END\n");
finished = 0;
return 0;
}
finished = 1;
if ( copy_to_user(buffer, procfs_buffer, procfs_buffer_size) ) {
return -EFAULT;
}
printk(KERN_INFO "procfs_read: read %lu bytes\n", procfs_buffer_size);
return procfs_buffer_size;
}
static ssize_t
procfs_write(struct file *file, const char *buffer, size_t len, loff_t * off)
{
if ( len > PROCFS_MAX_SIZE ) {
procfs_buffer_size = PROCFS_MAX_SIZE;
}
else {
procfs_buffer_size = len;
}
if ( copy_from_user(procfs_buffer, buffer, procfs_buffer_size) ) {
return -EFAULT;
}
printk(KERN_INFO "procfs_write: write %lu bytes\n", procfs_buffer_size);
return procfs_buffer_size;
}
static int module_permission(struct inode *inode, int op, struct nameidata *foo)
{
if (op == 4 || (op == 2 && current->euid == 0))
return 0;
return -EACCES;
}
int procfs_open(struct inode *inode, struct file *file)
{
try_module_get(THIS_MODULE);
return 0;
}
int procfs_close(struct inode *inode, struct file *file)
{
module_put(THIS_MODULE);
return 0; /* success */
}
static struct file_operations File_Ops_4_Our_Proc_File = {
.read = procfs_read,
.write = procfs_write,
.open = procfs_open,
.release = procfs_close,
};
static struct inode_operations Inode_Ops_4_Our_Proc_File = {
.permission = module_permission,
};
int init_module()
{
Our_Proc_File = create_proc_entry(PROC_ENTRY_FILENAME, 0644, NULL);
if (Our_Proc_File == NULL){
printk(KERN_ALERT "Error: Could not initialize /proc/%s\n",
PROC_ENTRY_FILENAME);
return -ENOMEM;
}
Our_Proc_File->owner = THIS_MODULE;
Our_Proc_File->proc_iops = &Inode_Ops_4_Our_Proc_File;
Our_Proc_File->proc_fops = &File_Ops_4_Our_Proc_File;
Our_Proc_File->mode = S_IFREG | S_IRUGO | S_IWUSR;
Our_Proc_File->uid = 0;
Our_Proc_File->gid = 0;
Our_Proc_File->size = 80;
printk(KERN_INFO "/proc/%s created\n", PROC_ENTRY_FILENAME);
return 0; /* success */
}
void cleanup_module()
{
remove_proc_entry(PROC_ENTRY_FILENAME, &proc_root);
printk(KERN_INFO "/proc/%s removed\n", PROC_ENTRY_FILENAME);
}
上面的操作对于处理一个字符串之类的操作是比较简单的,然而当处理很长的数据,因为需要多次seek就会使得对设备的读取操作非常复杂。因此需要更加高层次的API(虽然上面所提到的都是字符设备,但是还是有些字符设备需要一次处理大量数据的能力)。恰好Linux提供了一套名为seq_file的API来辅助格式化一个/proc文件系统的输出。Seq_file接口包含三个方面:
1 一个滑动游标实现对整个文件的遍历
2 一些工具函数进行格式化输出而不必关心输出缓存
3 对file_operation中对虚拟文件进行访问的方法进行封装
实现seq_file文件操作API的模块必须实现一个很简单的游标对象,这个游标对象能够对整个感兴趣的数据进行遍历。然而游标和文件的偏移不相同,并且游标也不关注怎样与文件偏移进行转化,位移需要注意的是游标等于0表示文件的其实位置。
Seq_file操作通过调用相应的start函数开始,这个函数返回一个游标,这个游标指示开始读取的位置。游标是一个loff_t的数值,这个游标没有上限。在start之后,通过调用next函数来移动游标从而实现对整个顺序文件进行遍历,next函数返回下一个游标的位置或者NULL表示文件访问结束。Stop函数则表示整个游标访问结束,这个函数主要进行访问结束的一些清理工作。最后show函数将会实现格式化输出,这个函数将会返回0或者一个错误码。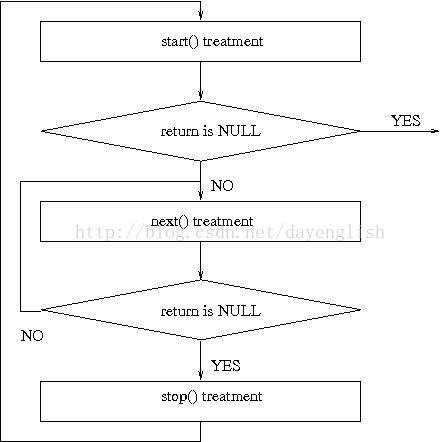
Seq_file提供了文件操作的基础函数,比如seq_read,seq_lseek以及其他的一些函数,不过没有提供写入操作。
#include <linux/kernel.h> /* We're doing kernel work */
#include <linux/module.h> /* Specifically, a module */
#include <linux/proc_fs.h> /* Necessary because we use proc fs */
#include <linux/seq_file.h> /* for seq_file */
#define PROC_NAME "iter"
MODULE_AUTHOR("Philippe Reynes");
MODULE_LICENSE("GPL");
static void *my_seq_start(struct seq_file *s, loff_t *pos)
{
static unsigned long counter = 0;
if ( *pos == 0 )
{
return &counter;
}
else
{
*pos = 0;
return NULL;
}
}
static void *my_seq_next(struct seq_file *s, void *v, loff_t *pos)
{
unsigned long *tmp_v = (unsigned long *)v;
(*tmp_v)++;
(*pos)++;
return NULL;
}
static void my_seq_stop(struct seq_file *s, void *v)
{
}
static int my_seq_show(struct seq_file *s, void *v)
{
loff_t *spos = (loff_t *) v;
seq_printf(s, "%Ld\n", *spos);
return 0;
}
static struct seq_operations my_seq_ops = {
.start = my_seq_start,
.next = my_seq_next,
.stop = my_seq_stop,
.show = my_seq_show
};
static int my_open(struct inode *inode, struct file *file)
{
return seq_open(file, &my_seq_ops);
};
static struct file_operations my_file_ops = {
.owner = THIS_MODULE,
.open = my_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release
};
int init_module(void)
{
struct proc_dir_entry *entry;
entry = create_proc_entry(PROC_NAME, 0, NULL);
if (entry) {
entry->proc_fops = &my_file_ops;
}
return 0;
}
void cleanup_module(void)
{
remove_proc_entry(PROC_NAME, NULL);
}