Hadoop 求平均值 Average
hadoop 求平均值
1、源代码,map切割读入名字和分数,reduce汇总同一个人key的分数,然后求平均值
package com.dtspark.hadoop.hellomapreduce;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Average {
/*
*
*/
public static class DataMapper
extends Mapper<Object, Text, Text, FloatWritable>{
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
System.out.println("Map Method Invoked!");
String data = value.toString();
System.out.println(data);
StringTokenizer splited = new StringTokenizer(data,"\n");
while (splited.hasMoreElements()){
StringTokenizer record = new StringTokenizer(splited.nextToken());
String name =record.nextToken();
String score =record.nextToken();
context.write(new Text(name),new FloatWritable(Float.valueOf(score)));
}
}
}
/*
*
*/
public static class DataReducer
extends Reducer<Text, FloatWritable,Text,FloatWritable> {
public void reduce(Text key, Iterable<FloatWritable> values,
Context context
) throws IOException, InterruptedException {
System.out.println("Reduce Method Invoked!");
Iterator<FloatWritable> iterator = values.iterator();
float sum =0;
int count =0;
while(iterator.hasNext()){
float tmp =iterator.next().get();
sum += tmp;
count++;
}
float averageScore = sum/count;
context.write(key,new FloatWritable(averageScore) );
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: DefferentData <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "Average");
job.setJarByClass(Average.class);
job.setMapperClass(DataMapper.class);
job.setCombinerClass(DataReducer.class);//加快效率
job.setReducerClass(DataReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FloatWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2、数据文件
[root@master IMFdatatest]#cat dataForAverage.txt
Spark 100
Hadoop 98
Spark 95
Kfaka 80
[root@master IMFdatatest]#
3、上传集群
[root@master IMFdatatest]#hadoop dfs -put dataForAverage.txt /library
4、运行参数
hdfs://192.168.2.100:9000/library/dataForAverage.txt
hdfs://192.168.2.100:9000/library/outputdataForAverage9
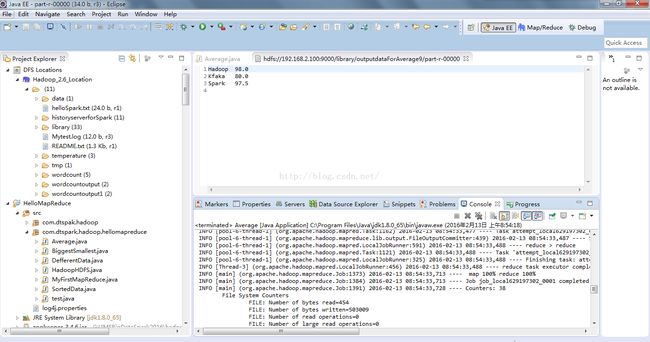
运行结果如下
[root@master IMFdatatest]#hadoop dfs -cat /library/outputdataForAverage9/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/02/12 18:58:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Hadoop 98.0
Kfaka 80.0
Spark 97.5