由LCA引发的问题--RMQ,Tarjan,并查集等
原文来自:http://blog.csdn.net/qiuyang0607/article/details/7652310
引入LCA问题及其在线和离线算法
两个月前有一次一个电话面试问到了一个问题:“怎样求二叉树中距离两个叶子节点最近的祖先节点。”当时不会,后来在网上查了查发现是一个比较经典的题目,也有几种算法可以解决这个问题,我学习了一下,在这儿记下来。这个问题更宽泛的定义是:如何求树(不限于二叉树)中两个节点(不限于叶子节点)的最近公共祖先节点。这个问题被称为LCA(Lowest Common Ancestor)问题。
我找到的关于这个问题解答的最全面的文章是这篇:二叉树中两个节点的最近公共祖先
按照文中的说法,解决这个问题有两个思路,一个为离线算法,另一个为在线算法。我查了一下这两组名词的含义,“在计算机科学中,一个在线算法是指它可以以序列化的方式一个个的处理输入,也就是说在开始时并不需要已经知道所有的输入。相对的,对于一个离线算法,在开始时就需要知道问题的所有输入数据,而且在解决一个问题后就要立即输出结果。例如,选择排序在排序前就需要知道所有待排序元素,然而插入排序就不必。”
此问题的离线和在线算法都涉及到了深度优先搜寻,在线算法引出了另外一个问题,称为RMQ(Range Minimum/Maximum Query)问题,而离线算法是一个专门的由一个外国人发明的Tarjan算法。
由在线算法引出RMQ问题,及LCA与RMQ的相互转化
在查找到的资料中,LCA与RMQ是可以相互转化的,LCA向RMQ的转化是在在线算法的思路下进行的。下面说明一下他们之间的关系,这其中参考了一个PPT。
问题的提出:
LCA:基于有根树最近公共祖先问题。 LCA(T, u, v):在有根树T中,询问一个距离根最远的结点x,使得x同时为结点u、v的祖先。
RMQ:区间最小值询问问题。 RMQ(A, i, j):对于线性序列A中,询问区间[i, j]上的最小(最大)值。
RMQ向LCA的转化:
考察一个长度为N的序列A,按照如下方法将其递归建立为一棵树:
1)设序列中最小值为Ak,建立优先级为Ak的根节点Tk;
2)将A(1...k-1)递归建树作为Tk的左子树;
3)将A(k+1...N)递归建树作为Tk的右子树;
如序列A=(7, 5, 8, 1, 10)建树的结果为:
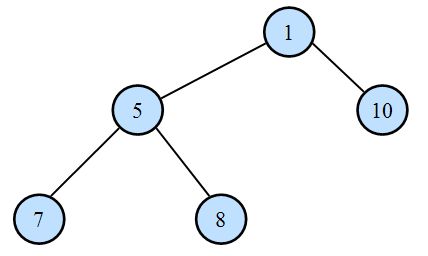
对于RMQ(A, i, j):
1)设序列中的最小值为Ak,若i<=k<=j,那么答案为k;
2)若k>j,那么答案为RMQ(A1...k-1, i, j);
3)若k<i,那么答案为RMQ(Ak+1...N, i, j);
不难发现RMQ(A, i, j)=LCA(T, i, j),这就证明了RMQ问题可以转化为LCA问题。
LCA向RMQ问题的转化:
对有根树T进行DFS,将遍历到的节点按顺序记录下来,我们将得到一个长度为2N-1的序列,称之为T的欧拉序列F。每个节点都在欧拉序列中出现,我们记录节点u在欧拉序列中第一次出现的位置为pos(u)。如下树:
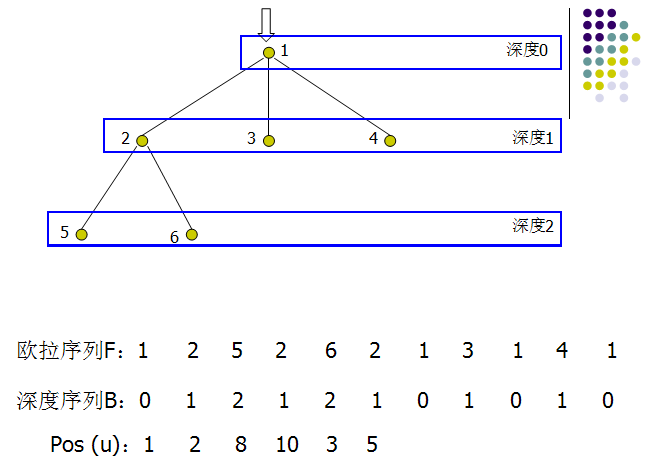
根据DFS的性质,对于两个节点u,v,从pos(u)遍历到pos(v)的过程中经过LCA(u, v)有且仅有一次,且深度是深度序列B[pos(u)...pos(v)]中最小的,即LCA(T, u, v)=RMQ(F, pos(u), pos(v)),并且问题的规模仍然是O(N)的。这就证明了LCA问题可以转化为RMQ问题。
RMQ的ST算法
RMQ问题:
RMQ问题是求给定区间中的最值问题,如下图所示:
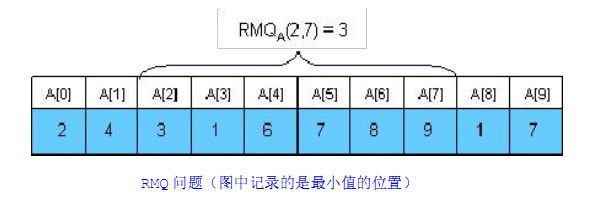
假设一个算法的预处理时间为f(n),查询时间为g(n),则这个算法的时间复杂度标记为:<f(n), g(n)>。
当然,最简单的算法是O(n)的,但是对于查询次数很多m(假设有100万次),则这个算法的时间复杂度为O(mn),显然时间效率太低。可以用线段树将查询算法优化到O(logn),而线段树的预处理时间复杂度为O(n),线段树整体复杂度为<O(n), O(logn)>,这个还没有研究。不过,Sparse_Table算法(简称ST算法)才是最好的:它可以在O(nlogn)的预处理以后实现O(1)的查询效率,即整体时间复杂度为<O(nlogn),O(1)>。ST(Sparse Table)算法的基本思想是,预先计算从起点A[i]开始长度为2的j次方
(j=0,1...logn)的区间的最小值,然后在查询时将任何一个区间A[i..j]划分为两个预处理好的可能重叠的区间,取这两个重叠区间的最小值。下面把ST算法分为预处理和查询两部分。
1.预处理
预处理使用DP思想,用f(i, j)表示[i, i+2^j-1]区间中的最小值,即f(i, j)表示从第i个数起连续2^j个数中的最小值(例如,f(1, 0)表示[1, 1]中的最小值,就是num[1]),而任意一个长度为2^j的区间都可以划分为两个长度为2^(j-1)的区间,其中第一个区间的范围为:i...i+2^(j-1)-1,第二个区间范围为:i+2^(j-1)...i+2^j-1。所以f(i, j)可以由f(i, j-1)和f(i+2^(j-1), j-1)导出,而递推的初值(所有的f(i, 0)=num[i])都是已知的,所以我们可以采用自底向上的方法递推地给出所有符合条件的f(i, j)的值。ST的状态转移方程为:

2.查询
假设要查询从m到n这一段的最小值,m到n的区间长度为n-m+1,求出一个最大的k,使得k满足2^k<=(n-m+1),那么这个区间[m, n]可以被两个部分重叠的长度为2^k的区间完全覆盖,这两个区间为[m, m+2^k-1]和[n-2^k+1, n]。而我们之前已经求出了f(m, k)为[m, m+2^k-1]的最小值,f(n-2^k+1, k)为[n-2^k+1, n]的最小值。我们只要返回其中更小的那个,就是答案,算法时间复杂度为O(1)。

参考了一篇博客:RMQ问题的ST算法
ST算法在数组上的实现如下:
- // Using ST(Sparse Table) to solve RMQ Problem
- // M[i][j] stands for the subscript of the minimum number in the array range A[i,i+2^j-1]
- #include <stdio.h>
- #include <math.h>
- #define K 100
- int M[K][K];
- //
- int RMQinit(int a[], int len)
- {
- int i, j;
- //int len=sizeof(a)/sizeof(int); 犯错误了
- //printf("%d\n",len);
- int lenJ=sqrt(len);
- //int lenJ=log(len)/log(2);
- // Initilization
- for(i=0;i<len;i++)
- M[i][0]=i;
- for(j=1;j<=lenJ;j++)
- {
- for(i=0;i+(1<<j)-1<len;i++)
- M[i][j]=(a[M[i][j-1]]<a[M[i+(1<<(j-1))][j-1]])?(M[i][j-1]):(M[i+(1<<(j-1))][j-1]);
- }
- return 0;
- }
- int Query(int a[], int i, int j)
- {
- int k=sqrt(j-i+1);
- //int k=log(j-i+1)/log(2);
- int min=(a[M[i][k]]<a[M[j+1-(1<<k)][k]])?(a[M[i][k]]):(a[M[j+1-(1<<k)][k]]);
- printf("The Minimum number denoted by %d and %d in the array is %d\n",i, j, min);
- return 0;
- }
- int main()
- {
- int Array[]={2,4,3,1,6,7,8,9,1,7};
- int length=sizeof(Array)/sizeof(int);
- RMQinit(Array, length);
- Query(Array, 3, 7);
- return 0;
- }
- // Using ST(Sparse Table) to solve RMQ Problem
- // M[i][j] stands for the subscript of the minimum number in the array range A[i,i+2^j-1]
- #include <stdio.h>
- #include <math.h>
- #define K 100
- int M[K][K];
- //
- int RMQinit(int a[], int len)
- {
- int i, j;
- //int len=sizeof(a)/sizeof(int); 犯错误了
- //printf("%d\n",len);
- int lenJ=sqrt(len);
- //int lenJ=log(len)/log(2);
- // Initilization
- for(i=0;i<len;i++)
- M[i][0]=i;
- for(j=1;j<=lenJ;j++)
- {
- for(i=0;i+(1<<j)-1<len;i++)
- M[i][j]=(a[M[i][j-1]]<a[M[i+(1<<(j-1))][j-1]])?(M[i][j-1]):(M[i+(1<<(j-1))][j-1]);
- }
- return 0;
- }
- int Query(int a[], int i, int j)
- {
- int k=sqrt(j-i+1);
- //int k=log(j-i+1)/log(2);
- int min=(a[M[i][k]]<a[M[j+1-(1<<k)][k]])?(a[M[i][k]]):(a[M[j+1-(1<<k)][k]]);
- printf("The Minimum number denoted by %d and %d in the array is %d\n",i, j, min);
- return 0;
- }
- int main()
- {
- int Array[]={2,4,3,1,6,7,8,9,1,7};
- int length=sizeof(Array)/sizeof(int);
- RMQinit(Array, length);
- Query(Array, 3, 7);
- return 0;
- }
LCA的在线算法程序
- // 二叉树LCA在线算法, 转化为RMQ问题
- // c/c++是大小写敏感的, NULL=0, null只是一个符号
- #include <iostream>
- #include <cmath>
- #define MAX 10
- using namespace std;
- int dfs[2*MAX];
- int depth[2*MAX];
- int pos[MAX]; // first apparence position
- int M[2*MAX][2*MAX];
- int len=0; // denote the subscript of the array
- struct Node
- {
- int value;
- Node *left;
- Node *right;
- Node(int val, Node *l, Node *r)
- {
- value=val;
- left=l;
- right=r;
- }
- };
- // Depth First Search
- int DFS(Node *root, int d)
- {
- if(root==NULL)
- return 0;
- dfs[len]=root->value;
- depth[len]=d;
- pos[root->value-1]=len; //
- len++;
- //DFS(root->left, ++d);
- DFS(root->left, d+1);
- // left backtrack
- if(root->left!=NULL)
- {
- dfs[len]=root->value;
- depth[len]=d;
- len++;
- }
- //DFS(root->right, ++d);
- DFS(root->right, d+1);
- // right backtrack
- if(root->right!=NULL)
- {
- dfs[len]=root->value;
- depth[len]=d;
- len++;
- }
- return 0;
- }
- //
- int RMQ()
- {
- int i, j;
- int lenJ=(int)sqrt(len);
- for(i=0;i<len;i++)
- M[i][0]=i;
- for(j=1;j<=lenJ;j++)
- {
- for(i=0;i+(1<<j)-1<len;i++)
- M[i][j]=(depth[M[i][j-1]]<depth[M[i+(1<<(j-1))][j-1]])?(M[i][j-1]):(M[i+(1<<(j-1))][j-1]);
- }
- return 0;
- }
- int Query(Node *a, Node *b)
- {
- int i=pos[a->value-1], j=pos[b->value-1];
- int temp;
- if(i>j)
- {
- temp=j;
- i=j;
- j=temp;
- }
- int k=(int)sqrt(j-i+1);
- // pay attention to the relation
- int minpos=(depth[M[i][k]]<depth[M[j+1-(1<<k)][k]])?(M[i][k]):(M[j+1-(1<<k)][k]);
- int nodeval=dfs[minpos];
- printf("The LCA of node %d and node %d is node %d", a->value, b->value, nodeval);
- return 0;
- }
- int main()
- {
- Node *n3 = new Node(3, NULL, NULL);
- Node *n5 = new Node(5, NULL, NULL);
- Node *n6 = new Node(6, NULL, NULL);
- Node *n8 = new Node(8, NULL, NULL);
- Node *n4 = new Node(4, n5, n6);
- Node *n7 = new Node(7, NULL, n8);
- Node *n2 = new Node(2, n3, n4);
- Node *n1 = new Node(1, n2, n7);
- DFS(n1, 0); // pass parameter depth
- RMQ();
- Query(n4, n8);
- return 0;
- }
- // 二叉树LCA在线算法, 转化为RMQ问题
- // c/c++是大小写敏感的, NULL=0, null只是一个符号
- #include <iostream>
- #include <cmath>
- #define MAX 10
- using namespace std;
- int dfs[2*MAX];
- int depth[2*MAX];
- int pos[MAX]; // first apparence position
- int M[2*MAX][2*MAX];
- int len=0; // denote the subscript of the array
- struct Node
- {
- int value;
- Node *left;
- Node *right;
- Node(int val, Node *l, Node *r)
- {
- value=val;
- left=l;
- right=r;
- }
- };
- // Depth First Search
- int DFS(Node *root, int d)
- {
- if(root==NULL)
- return 0;
- dfs[len]=root->value;
- depth[len]=d;
- pos[root->value-1]=len; //
- len++;
- //DFS(root->left, ++d);
- DFS(root->left, d+1);
- // left backtrack
- if(root->left!=NULL)
- {
- dfs[len]=root->value;
- depth[len]=d;
- len++;
- }
- //DFS(root->right, ++d);
- DFS(root->right, d+1);
- // right backtrack
- if(root->right!=NULL)
- {
- dfs[len]=root->value;
- depth[len]=d;
- len++;
- }
- return 0;
- }
- //
- int RMQ()
- {
- int i, j;
- int lenJ=(int)sqrt(len);
- for(i=0;i<len;i++)
- M[i][0]=i;
- for(j=1;j<=lenJ;j++)
- {
- for(i=0;i+(1<<j)-1<len;i++)
- M[i][j]=(depth[M[i][j-1]]<depth[M[i+(1<<(j-1))][j-1]])?(M[i][j-1]):(M[i+(1<<(j-1))][j-1]);
- }
- return 0;
- }
- int Query(Node *a, Node *b)
- {
- int i=pos[a->value-1], j=pos[b->value-1];
- int temp;
- if(i>j)
- {
- temp=j;
- i=j;
- j=temp;
- }
- int k=(int)sqrt(j-i+1);
- // pay attention to the relation
- int minpos=(depth[M[i][k]]<depth[M[j+1-(1<<k)][k]])?(M[i][k]):(M[j+1-(1<<k)][k]);
- int nodeval=dfs[minpos];
- printf("The LCA of node %d and node %d is node %d", a->value, b->value, nodeval);
- return 0;
- }
- int main()
- {
- Node *n3 = new Node(3, NULL, NULL);
- Node *n5 = new Node(5, NULL, NULL);
- Node *n6 = new Node(6, NULL, NULL);
- Node *n8 = new Node(8, NULL, NULL);
- Node *n4 = new Node(4, n5, n6);
- Node *n7 = new Node(7, NULL, n8);
- Node *n2 = new Node(2, n3, n4);
- Node *n1 = new Node(1, n2, n7);
- DFS(n1, 0); // pass parameter depth
- RMQ();
- Query(n4, n8);
- return 0;
- }


LCA的离线Tarjan算法说明及程序
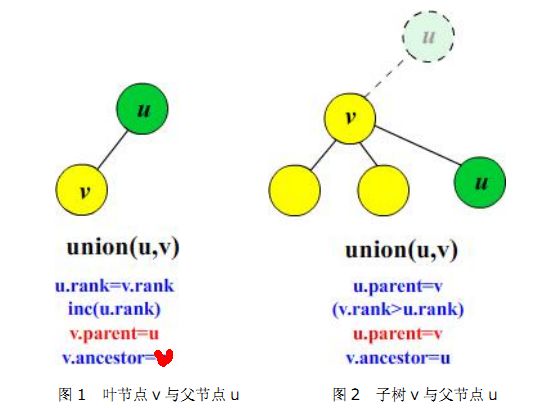
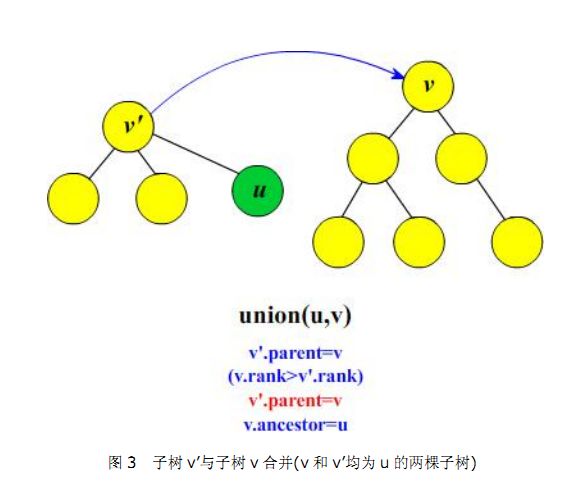
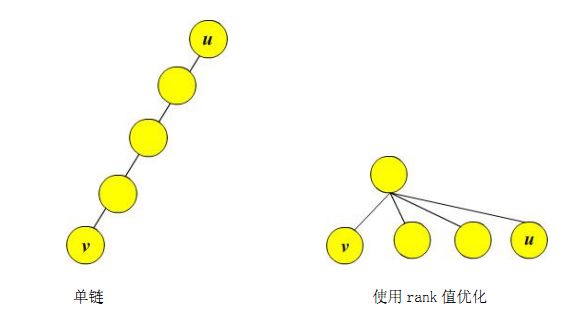
- // POJ 1330
- // Use Tarjan to solve LCA problem
- #include <iostream>
- #include <vector>
- #define MAX 100
- using namespace std;
- int parent[MAX];
- int rank[MAX];
- int ancestor[MAX];
- int indegree[MAX];
- int visit[MAX]; // record
- vector<int> Tree[MAX], Ques[MAX];
- // 加入初始化为多次运行清理环境
- int Init(int n)
- {
- int i;
- for(i=1;i<=n;i++)
- {
- parent[i]=0;
- rank[i]=0;
- ancestor[i]=0;
- indegree[i]=0;
- visit[i]=0;
- Tree[i].clear();
- Ques[i].clear();
- }
- return 0;
- }
- int MakeSet(int i)
- {
- parent[i]=i;
- rank[i]=1;
- //ancestor[i]=i;
- return 0;
- }
- int Find(int i)
- {
- if(parent[i]==i)
- return i;
- else
- parent[i]=Find(parent[i]);
- return parent[i];
- }
- int Union(int x, int y)
- {
- // 寻找集合的根
- int a=Find(x);
- int b=Find(y);
- if(a==b)
- return 0;
- else if(rank[a]>rank[b])
- {
- parent[b]=a;
- rank[a]+=rank[b];
- }
- else
- {
- parent[a]=b;
- rank[b]+=rank[a];
- }
- /*
- else if(a!=b)
- {
- parent[b]=a;
- rank[a]+=1;
- }
- */
- return 0;
- }
- int LCA(int u)
- {
- MakeSet(u);
- ancestor[u]=u;
- int size=Tree[u].size(); //
- for(int i=0;i<size;i++)
- {
- LCA(Tree[u][i]);
- //Union(u,i);
- Union(u, Tree[u][i]);
- ancestor[Find(u)]=u;
- }
- visit[u]=1;
- size=Ques[u].size(); // 统计与u相关的查询的个数
- for(int i=0;i<size;i++)
- {
- if(visit[Ques[u][i]]==1)
- {
- //cout<<ancestor[find(u)]<<endl;
- cout<<ancestor[Find(Ques[u][i])]<<endl;
- return 0;
- }
- }
- return 0;
- }
- int main()
- {
- int cnt; // number of Test cases need to be sloved
- int n; // number of nodes in a tree
- cin>>cnt;
- while(cnt--)
- {
- int s, t, i;
- cin>>n;
- //for(int i=0;i<n;i++)
- Init(n);
- for(i=0;i<n-1;i++) // N nodes then N-1 edges 此处i只为计数没有实际意义
- {
- cin>>s>>t;
- Tree[s].push_back(t);
- indegree[t]++;
- }
- cin>>s>>t;
- Ques[s].push_back(t);
- Ques[t].push_back(s); // 离线算法,两次询问
- //for(int i=0;i<n;i++) // nodes start at 1 此处i为节点
- for(i=1;i<=n;i++)
- {
- if(indegree[i]==0)
- {
- LCA(i);
- break;
- }
- }
- }
- return 0;
- }
- // POJ 1330
- // Use Tarjan to solve LCA problem
- #include <iostream>
- #include <vector>
- #define MAX 100
- using namespace std;
- int parent[MAX];
- int rank[MAX];
- int ancestor[MAX];
- int indegree[MAX];
- int visit[MAX]; // record
- vector<int> Tree[MAX], Ques[MAX];
- // 加入初始化为多次运行清理环境
- int Init(int n)
- {
- int i;
- for(i=1;i<=n;i++)
- {
- parent[i]=0;
- rank[i]=0;
- ancestor[i]=0;
- indegree[i]=0;
- visit[i]=0;
- Tree[i].clear();
- Ques[i].clear();
- }
- return 0;
- }
- int MakeSet(int i)
- {
- parent[i]=i;
- rank[i]=1;
- //ancestor[i]=i;
- return 0;
- }
- int Find(int i)
- {
- if(parent[i]==i)
- return i;
- else
- parent[i]=Find(parent[i]);
- return parent[i];
- }
- int Union(int x, int y)
- {
- // 寻找集合的根
- int a=Find(x);
- int b=Find(y);
- if(a==b)
- return 0;
- else if(rank[a]>rank[b])
- {
- parent[b]=a;
- rank[a]+=rank[b];
- }
- else
- {
- parent[a]=b;
- rank[b]+=rank[a];
- }
- /*
- else if(a!=b)
- {
- parent[b]=a;
- rank[a]+=1;
- }
- */
- return 0;
- }
- int LCA(int u)
- {
- MakeSet(u);
- ancestor[u]=u;
- int size=Tree[u].size(); //
- for(int i=0;i<size;i++)
- {
- LCA(Tree[u][i]);
- //Union(u,i);
- Union(u, Tree[u][i]);
- ancestor[Find(u)]=u;
- }
- visit[u]=1;
- size=Ques[u].size(); // 统计与u相关的查询的个数
- for(int i=0;i<size;i++)
- {
- if(visit[Ques[u][i]]==1)
- {
- //cout<<ancestor[find(u)]<<endl;
- cout<<ancestor[Find(Ques[u][i])]<<endl;
- return 0;
- }
- }
- return 0;
- }
- int main()
- {
- int cnt; // number of Test cases need to be sloved
- int n; // number of nodes in a tree
- cin>>cnt;
- while(cnt--)
- {
- int s, t, i;
- cin>>n;
- //for(int i=0;i<n;i++)
- Init(n);
- for(i=0;i<n-1;i++) // N nodes then N-1 edges 此处i只为计数没有实际意义
- {
- cin>>s>>t;
- Tree[s].push_back(t);
- indegree[t]++;
- }
- cin>>s>>t;
- Ques[s].push_back(t);
- Ques[t].push_back(s); // 离线算法,两次询问
- //for(int i=0;i<n;i++) // nodes start at 1 此处i为节点
- for(i=1;i<=n;i++)
- {
- if(indegree[i]==0)
- {
- LCA(i);
- break;
- }
- }
- }
- return 0;
- }

参考资料:《RMQ和LCA讲稿》及网络上的各种资料文章