spark 版本定制 第5课:基于案例一节课贯通Spark Streaming流计算框架的运行源码3
先贴下案例源码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Durations, StreamingContext}
/**
* 感谢王家林老师的知识分享
* 王家林老师名片:
* 中国Spark第一人
* 新浪微博:http://weibo.com/ilovepains
* 微信公众号:DT_Spark
* 博客:http://blog.sina.com.cn/ilovepains
* 手机:18610086859
* QQ:1740415547
* 邮箱:[email protected]
* YY课堂:每天20:00免费现场授课频道68917580
* 王家林:DT大数据梦工厂创始人、Spark亚太研究院院长和首席专家、大数据培训专家、大数据架构师。
*/
object StreamingWordCountSelfScala {
def main(args: Array[String]) {
val sparkConf = new SparkConf().setMaster("spark://master:7077").setAppName("StreamingWordCountSelfScala")
val ssc = new StreamingContext(sparkConf, Durations.seconds(5)) // 每5秒收割一次数据
val lines = ssc.socketTextStream("localhost", 9999) // 监听 本地9999 socket 端口
val words = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) // flat map 后 reduce
words.print() // 打印结果
ssc.start() // 启动
ssc.awaitTermination()
ssc.stop(true)
}
}
上文已经从源码分析了InputDStream实例化过程,下一步是
val words = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _) // flat map 后 reduce
源码钻进去
// DStream.scala line 561
/**
* Return a new DStream by applying a function to all elements of this DStream,
* and then flattening the results
*/
def flatMap[U: ClassTag](flatMapFunc: T => Traversable[U]): DStream[U] = ssc.withScope {
new FlatMappedDStream(this, context.sparkContext.clean(flatMapFunc))
}
进入FlatMappedDStream.scala
// FlatMappedDStream.scala line 24
private[streaming]
class FlatMappedDStream[T: ClassTag, U: ClassTag](
parent: DStream[T],
flatMapFunc: T => Traversable[U]
) extends DStream[U](parent.ssc) {
// 很关键,这里设置了依赖是传入的parent,也就是DStream。本例中,就是SocketInputDStream
// 这里是有依赖的parent,且只有一个。
override def dependencies: List[DStream[_]] = List(parent)
// slideDuration也继承了parent的slideDuration
override def slideDuration: Duration = parent.slideDuration
// 是不是很清晰,返回的是RDD,DStream是RDD的模版
override def compute(validTime: Time): Option[RDD[U]] = {
parent.getOrCompute(validTime).map(_.flatMap(flatMapFunc))
}
}
这里顺势看下DStream的继承结构吧。
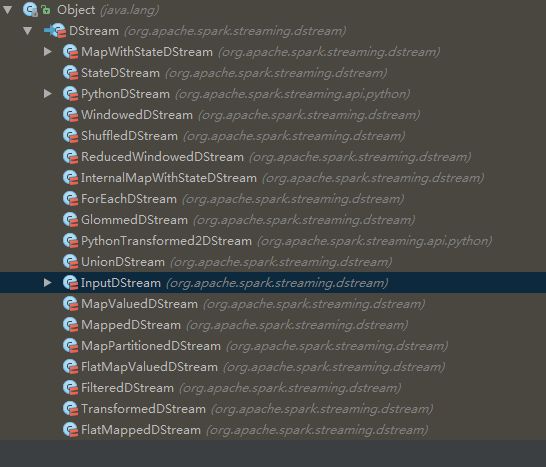
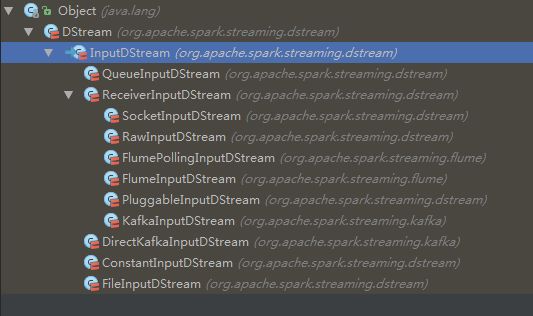
笔者扫描了一下代码,发现InputDStream及其他的子类的dependencies都是空列表 List() ,其他的都有一个甚至多个parent。
本例中 lines.flatMap(_.split(" ")) 操作创建的是FlatMappedDStream ,就是只有一个依赖的dependencies的。
读者还可以顾名思义发现很多只有一个依赖的dependencies的DStream。比如MappedDStream、MapValuedDStream、FilteredDStream等窄依赖
而肯定是2个依赖的DStream是什么呢?读者也不难发现,是PythonTransformed2DStream。此类不再讨论范围内,python的朋友可以自行深入。
其他的DStream在构造时,都需要传入多个DStream。如UnionDStream。
// UnionDStream.scala line 28
private[streaming]
class UnionDStream[T: ClassTag](parents: Array[DStream[T]])
extends DStream[T](parents.head.ssc) {
require(parents.length > 0, "List of DStreams to union is empty")
require(parents.map(_.ssc).distinct.size == 1, "Some of the DStreams have different contexts")
require(parents.map(_.slideDuration).distinct.size == 1,
"Some of the DStreams have different slide durations")
// 依赖是构建此DStream的DStream,由构造时传入
override def dependencies: List[DStream[_]] = parents.toList
...
}
因此这里有一个规律,InputDStream下的DStream是第一个DStream,由StreamingContext创建,这点与SparkContext创建第一个RDD类似。
而其他的基于DStream的操作都是由上一个DStream引发的。这点也与RDD操作引发下一个RDD类似。
DStream的宽窄依赖决定dependencies是一个还是多个。
继续前行,进入reduceByKey
val words = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
细心的朋友会发现,整个DStream中是没有 reduceByKey 方法的。为何这里可以执行呢?
这也是scala的魅力所在,隐式转换。
// DStream.scala line 975
object DStream {
// `toPairDStreamFunctions` was in SparkContext before 1.3 and users had to
// `import StreamingContext._` to enable it. Now we move it here to make the compiler find
// it automatically. However, we still keep the old function in StreamingContext for backward
// compatibility and forward to the following function directly.
implicit def toPairDStreamFunctions[K, V](stream: DStream[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null):
PairDStreamFunctions[K, V] = {
new PairDStreamFunctions[K, V](stream)
}
...
// 其他方法
}
此隐式转换匹配的是键值对类型的输入,和map((_,1))输出的是一致的,因此可以进行隐式转换。
reduceByKey返回的是 ShuffledDStream
// PairDStreamFunctions.scala line 81
/**
* Return a new DStream by applying `reduceByKey` to each RDD. The values for each key are
* merged using the associative reduce function. Hash partitioning is used to generate the RDDs
* with Spark's default number of partitions.
*/
// 重点是看返回结构,依然是DStream
def reduceByKey(reduceFunc: (V, V) => V): DStream[(K, V)] = ssc.withScope {
reduceByKey(reduceFunc, defaultPartitioner())
}
def reduceByKey(
reduceFunc: (V, V) => V,
numPartitions: Int): DStream[(K, V)] = ssc.withScope {
reduceByKey(reduceFunc, defaultPartitioner(numPartitions))
}
def reduceByKey(
reduceFunc: (V, V) => V,
partitioner: Partitioner): DStream[(K, V)] = ssc.withScope {
combineByKey((v: V) => v, reduceFunc, reduceFunc, partitioner)
}
def combineByKey[C: ClassTag](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiner: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true): DStream[(K, C)] = ssc.withScope {
val cleanedCreateCombiner = sparkContext.clean(createCombiner)
val cleanedMergeValue = sparkContext.clean(mergeValue)
val cleanedMergeCombiner = sparkContext.clean(mergeCombiner)
new ShuffledDStream[K, V, C]( // 返回的本质上是ShuffledDStream
self,
cleanedCreateCombiner,
cleanedMergeValue,
cleanedMergeCombiner,
partitioner,
mapSideCombine)
}
继续 words.print() ,实例化了ForEachDStream,对实例化后的ForEachDStream.register()
// DStream.scala line 757
def print(): Unit = ssc.withScope {
print(10)
}
// DStream.scala line 765
def print(num: Int): Unit = ssc.withScope {
def foreachFunc: (RDD[T], Time) => Unit = {
(rdd: RDD[T], time: Time) => {
val firstNum = rdd.take(num + 1)
// scalastyle:off println
println("-------------------------------------------")
println("Time: " + time)
println("-------------------------------------------")
firstNum.take(num).foreach(println)
if (firstNum.length > num) println("...")
println()
// scalastyle:on println
}
}
foreachRDD(context.sparkContext.clean(foreachFunc), displayInnerRDDOps = false)
}
// DStream.scala line 684
private def foreachRDD(
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean): Unit = {
new ForEachDStream(this,
context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register()
}
创建了一个ForEachDStream,并将当前的依赖传入作为parent。
// ForEachDStream.scala line 33
private[streaming]
class ForEachDStream[T: ClassTag] (
parent: DStream[T],
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean
) extends DStream[Unit](parent.ssc) {
// 依赖,本例是
override def dependencies: List[DStream[_]] = List(parent)
// 继承slideDuration
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[Unit]] = None
override def generateJob(time: Time): Option[Job] = {
parent.getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => createRDDWithLocalProperties(time, displayInnerRDDOps) {
foreachFunc(rdd, time)
}
Some(new Job(time, jobFunc))
case None => None
}
}
}
最后register,将此ForEachDStream加入到outputStreams。
读者扫描了下代码,发现所有的outputStreams都是通过register,且都是通过 foreachRDD创建ForEachDStream后调用register加入进DStreamGraph的。
// DStream.scala line 969
private[streaming] def register(): DStream[T] = {
ssc.graph.addOutputStream(this)
this
}
// DStreamGraph.scala line 90
def addOutputStream(outputStream: DStream[_]) {
this.synchronized {
outputStream.setGraph(this)
outputStreams += outputStream
}
}
至此,整个业务逻辑的定义已经完成,已经开始执行了吗?没有。这里只是将业务定义完了,并没有开始计算。因此,此时就算有数据流入,也不会有输出的。
下文,我们将开始关键的运行时。尽请期待。
感谢王家林老师的知识分享
王家林老师名片:
中国Spark第一人
感谢王家林老师的知识分享
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
YY课堂:每天20:00免费现场授课频道68917580
王家林:DT大数据梦工厂创始人、Spark亚太研究院院长和首席专家、大数据培训专家、大数据架构师。