HTK语音信号处理-帧序列
本文假设所处理的语音输入格式是WAVEFORM(SOURCEKIND的值设置),由HTK库中HWave库提供处理支持,对于其它的格式,基本也是相通的。从原始语音到最后的特征向量(如MFCC)文件需要经过
原始语音->预加重->分帧->加窗处理->快速傅里叶转换->滤波组处理->离散余弦转换(计算倒谱参数)->对数能量->差量倒谱参数(向量的形式了)->MFCC特征
本文只完成对预加重、分帧及加窗处理的简单说明 。
一,语音处理的目的
将语音数据转换成标准向量特征,所谓标准,是指特定软件可以支持识别和训练的意思,这里是HTK所支持的。
二,本文过程概览
上面的目的说明最后的输出应该是一个特征向量文件,在本文先讨论从原始语音到帧向量的形式,下面的图,可以表达这个过程的
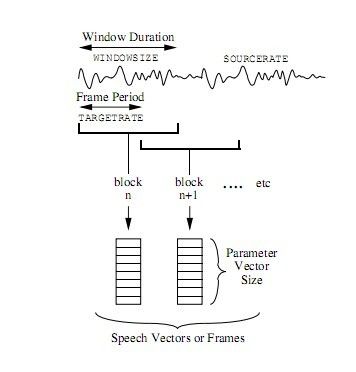
从上面的图可以看到,从语音输入到最后的每帧向量的形式,这就基本完成了语音到帧向量序列的处理过程了。原始信号就是上图中的波形图,特征参数向量序列就是最下面的每帧的语音向量。下面我从处理过程中用到的配置参数的角度来了解这个过程。
一,SOURCERATE
这个值是配置文件中设置原始信号的采样率的名值,表示原始语音信号的采样率,这个可以从原始文件中读取,也可以在配置文件中设置。
二,TARGETRATE
输出的采样率由每个参数向量之间的周期来决定,可以使用TARGETRATE在配置文件中设置。
三,WINDOWSIZE
窗口大小,由语音的采样文件到参数向量的转换过程中需要用到窗口大小。这个值和TARGETRATE是独立的,一般情况下,都会比TARGETRATE大,因为需要窗口有一定的重叠。
举个例子:假设语音文件采样率是16kHz,将其转换成每秒100个参数向量,就是10ms一个帧的分割,使用25ms的窗口大小,可以这样设置(下面都是100ns为单位)
SOURCERATE = 625 //表示 62500ns,0.0625ms,0.0000625s 。 f= 1/T = 1/0.0000625 = 16000 = 16kHz
TARGETRATE = 100000 // 表示 10 ms
WINDOWSIZE = 25 0000 // 表示 25ms
四,ZEANSOURCE
这是个布尔类型,如果设置为true时,就会从原始信号中移除DC均值。
五,PREEMCOEF
这是预加重的过程,这个参数表示加重系数,就像这样的公式S'(n) = S(n) - k S(n-1),这个参数表示k的值,一般都在0.9以上。关于预加重见:语音处理预加重
六,USEHAMMING
这个表示加窗过程,如果这个值设置为T 时,表示加汉明窗,具体见语音信息加窗处理。