Hadoop 排序 SortData
Hadoop 排序
1、源代码(IMF)
package com.dtspark.hadoop.hellomapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class SortData {
/**
* 使用Mapper将输入文件中的数据作为Mapp输出的key直接输出
*/
public static class ForSortDataMapper
extends Mapper<Object, Text, LongWritable, LongWritable> {
private LongWritable data = new LongWritable(1);
private LongWritable eValue = new LongWritable(1);
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
data.set(Long.valueOf(value.toString()));
context.write(data, eValue);
}
}
/**
* 使用Reducer将输入的key本身作为输入的key直接输出
*/
public static class ForSortReducer
extends Reducer<LongWritable, LongWritable, LongWritable, LongWritable> {
private LongWritable position = new LongWritable(1);
public void reduce(LongWritable key, Iterable<LongWritable> values,
Context context)
throws IOException, InterruptedException {
for(LongWritable item : values){
context.write(position, key);
position.set(position.get() + 1);
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: Sort <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "Sort Data");
job.setJarByClass(SortData.class);
job.setMapperClass(ForSortDataMapper.class);
//job.setCombinerClass(ForSortReducer .class);
job.setReducerClass(ForSortReducer.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(LongWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2、已经上传的数据文件
[root@master IMFdatatest]#hadoop dfs -cat /library/SortedData.txt
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/02/12 20:26:41 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
423535
45
666
77
888
22
3
4
5
7777888
99999
3、运行参数
hdfs://192.168.2.100:9000/library/SortedData.txt
hdfs://192.168.2.100:9000/library/outputSortedData13
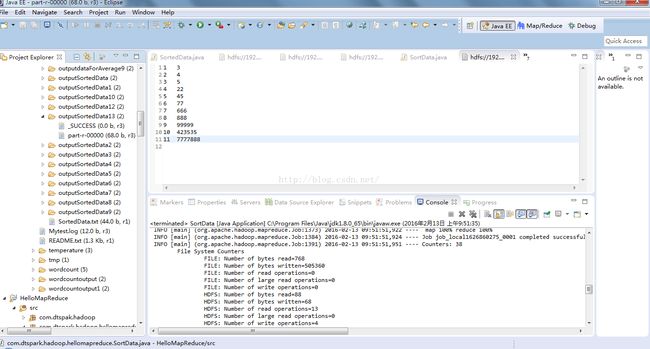
4、运行结果
[root@master IMFdatatest]#hadoop dfs -cat /library/outputSortedData13/part-r-00000
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
16/02/12 20:59:59 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1 3
2 4
3 5
4 22
5 45
6 77
7 666
8 888
9 99999
10 423535
11 7777888
[root@master IMFdatatest]#