Mysql入门学习笔记02—DML基础
很久很久以前学习mysql的笔记记录,很随意,但都是自己记录的,希望对需要的人有所帮助。
本文使用word2013编辑并发布
Postbird | There I am , in the world more exciting!
Postbird personal website .www.ptbird.cn
NULL:
NULL 都是not,防止出现null
NULL=NULL 是假;NULL!=NULL 是假;
0=0 是真;
select uid from user2 where name is NULL;
select uid from user2 where name is not NULL;
Group分组与统计函数:
max(); 求最大
count(); 求个数
avg(); 求平均
min(); 求最小
sum(); 求总和
group有一个排序过程 可能会耗费资源。
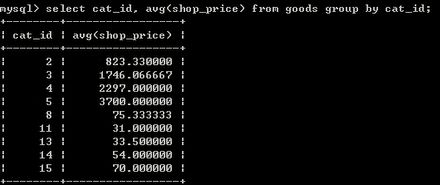
select cat_id,avg(shop_price) from goods group by cay_id;
Having 筛选:
where 作用的时间比较早 作用在磁盘上而不是内存上
having 可以做到使用 as 出来的数据
select (age1-age2) as cha from user3 where 1 having cha < 2;

练习:
找出下面中 不及格科目大于等于两门的人的平均分

select name ,sum(grade<60) as gk,avg(grade) as pj from
->user4 group by name
->having gk>=2;

Order by排序 limit查询
磁盘上的文件可能是排好序的,也可能没有排好序,需要拿到内存里排序。
select * from user4 order by grade desc;
升序;asc 默认
降序;desc
Limit 限制取出条目
第一个参数 : 偏移量
第二个参数 : 取出量
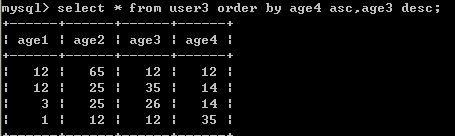
select * from user3 order by age4 asc,age3 desc limit 0,3;

子句的查询陷阱:(子查询)
where,group,having,order by,limit
5中子句有严格的顺序↑
Where型子查询:
内层查询的结果作为外层查询的条件

From型子查询:
select age1 from (select * from user3 order by age1 desc) as tmp;
先对表进行查找 然后 as 成一个别名的表,再次对表进行查询
Exists子查询:
select * from category where exists (select * from goods where goods_id=category_id);
查询 有商品的栏目id
首先查找goods表中的商品的栏目名有哪些(select * from goods where goods_id=category_id)
然后在表 category 中找确定存在(exists)的栏目名(符合上述要求的栏目名)。
新手的1+N模式查询

内链接查询
select boy.hid,boy.bname,girl.hid,girl.gname
->from boy inner join girl on boy.hid=girl.hid;

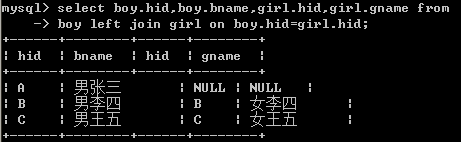
左连接查询 右连接查询
A left join B on C
A全部按照查询查询出,同时查询出符合条件C的B
select boy.hid,boy.bname,girl.hid,girl.gname from
-> boy left join girl on boy.hid=girl.hid;
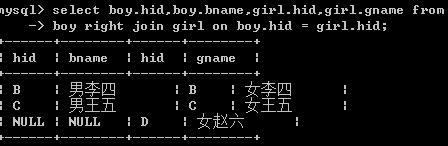
A right join B on C
B全部按照查询查询出,同时查询出符合条件C的A
select boy.hid,boy.bname,girl.hid,girl.gname from
->boy right join girl on boy.hid=girl.hid;

union查询
union查询就是把2条或多条sql的查询结果合并成一个结果集
sql1N行 sql2M行 结果 N+M行
union 上下两个sql必须是相同的列数,列名称不一定一样,列名称会使用第一条sql的列名称
select age1 from user3 union select bname from boy;
使用union时,完全相等的行,将会被合并,而且合并比较耗时的操作,
一般不让union进行合并,
使用 "union all"可以避免合并。
使用 union ,子句不用 order by, union之后的表可以使用 order by ;

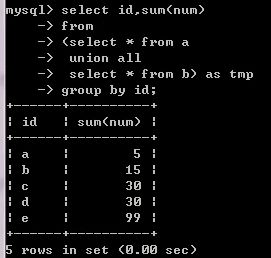
UNION 面试
将两张表中的ID相同的数字相加