hbase region lookups流程以及rpc线程卡死问题分析
未完待更新
1)
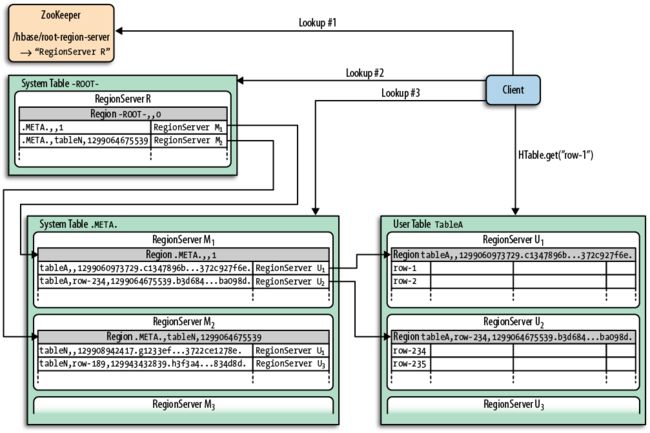
ZooKeeper中/hbase/root-region-server保存了-ROOT-表所在的服务器地址
2)hbase采用两张系统表来支持分片数据查找
-ROOT-表 (.META.表所在的服务器地址, 一般系统只有一行记录 ).META.表 (用户表所在的服务器地, 如:'table_test_a'各分片所在的服务器地址 )
2. hbase region lookups流程(以在'table_test_a'表, rowkey为'123456'的get为例子)
1)
首先, hbase client到ZooKeeper中获取-ROOT-表的所在位置
2)
再上-ROOT-表所在服务器查询-ROOT-表的.META.表所在的服务器地址
3)
再上.META.表所在的服务器查询用户表'table_test_a'分片信息
4)
根据用户表'table_test_a'分片信息, 计算出rowkey为'123456'所在的服务地址
(备注: 为了提升性能,hbase client端会缓存分片信息)
5) 代码入口: HRegionLocation getRegionLocation(byte [] tableName, byte [] row, boolean reload)
6) HBase Definitive Guide : Region Lookups 图
3. hbase client rpc线程卡死问题分析 ,已在0.94.1中修复(0.91, 0.92 版本 fix了很多0.94.0中的bug)。
1)hbase region lookups 死锁问题
详细见 @慢半拍de刀刀 博客 http://www.cnblogs.com/shenguanpu/archive/2012/12/02/2798217.html
2) 两个patch地址,
通过 避免嵌套重试循环来解决rpc线程卡死: https://issues.apache.org/jira/browse/HBASE-6326
通过等待 -root -的region地址设置到root region tracker 来避免deadlock问题: https://issues.apache.org/jira/browse/HBASE-6115
4. HTabe.get : retry connect引发rpc线程卡死问题
1)retry connect : withRetries
public Result get(final Get get) throws IOException {
return new ServerCallable<Result>(connection, tableName, get.getRow(), operationTimeout) {
public Result call() throws IOException {
return server.get(location.getRegionInfo().getRegionName(), get);
}
}.withRetries();
}
2)region lookups获取location,并根据location连接上region server。
/**
* Connect to the server hosting region with row from tablename.
* @param reload Set this to true if connection should re-find the region
* @throws IOException e
*/
public void connect(final boolean reload) throws IOException {
this.location = connection.getRegionLocation(tableName, row, reload);
this.server = connection.getHRegionConnection(location.getHostname(),
location.getPort());
}
3) getRegionLocation 调用locateRegion('用户表') , locateRegion('用户表')的核心流程是去.META.表中查询某用户表分片信息, 从而调用到locateRegionInMeta
private HRegionLocation locateRegion(final byte [] tableName,
final byte [] row, boolean useCache)
throws IOException {
....
if (Bytes.equals(tableName, HConstants.ROOT_TABLE_NAME)) {
...
ServerName servername = this.rootRegionTracker.getRootRegionLocation();
...
} ...
} else {
// Region not in the cache - have to go to the meta RS
return locateRegionInMeta(HConstants.META_TABLE_NAME, tableName, row,
useCache, userRegionLock);
}
}
4) 完整一次的'hbase region lookups流程', 会进入locateRegion('-ROOT-') 从而调用到 rootRegionTracker.getRootRegionLocation
(retry流程不会取cache数据, 而是先对regionLockObject加锁并prefetchRegionCache的metaScan, MetaScanner是完整一次的'hbase region lookups流程' )
/*
* Search one of the meta tables (-ROOT- or .META.) for the HRegionLocation
* info that contains the table and row we're seeking.
*/
private HRegionLocation locateRegionInMeta(final byte [] parentTable,
final byte [] tableName, final byte [] row, boolean useCache,
Object regionLockObject)
throws IOException {
......
// This block guards against two threads trying to load the meta
// region at the same time. The first will load the meta region and
// the second will use the value that the first one found.
synchronized (regionLockObject) {
// If the parent table is META, we may want to pre-fetch some
// region info into the global region cache for this table.
if (Bytes.equals(parentTable, HConstants.META_TABLE_NAME) &&
(getRegionCachePrefetch(tableName)) ) {
prefetchRegionCache(tableName, row);
}
......
}
......
}
}
4) 完整一次的'hbase region lookups流程', 会进入locateRegion('-ROOT-') 从而调用到 rootRegionTracker.getRootRegionLocation
private HRegionLocation locateRegion(final byte [] tableName,
final byte [] row, boolean useCache)
throws IOException {
....
if (Bytes.equals(tableName, HConstants.ROOT_TABLE_NAME)) {
...
ServerName servername = this.rootRegionTracker.getRootRegionLocation();
...
} ...
} else {
// Region not in the cache - have to go to the meta RS
return locateRegionInMeta(HConstants.META_TABLE_NAME, tableName, row,
useCache, userRegionLock);
}
}
5)RootRegionTracker 的getData, 从zookeeper取数据引发异常, 从而 abort流程
public synchronized byte [] getData(boolean refresh) {
if (refresh) {
try {
this.data = ZKUtil.getDataAndWatch(watcher, node);
} catch(KeeperException e) {
abortable.abort("Unexpected exception handling getData", e);
}
}
return this.data;
}
6) abort流程(deadlock bug所在: abortable实际为HConnectionManager.HConnectionImplementation对象 )
private synchronized void ensureZookeeperTrackers()
throws ZooKeeperConnectionException {
...
if (rootRegionTracker == null) {
rootRegionTracker = new RootRegionTracker(zooKeeper, this);
rootRegionTracker.start();
}
}